 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-$M^3$: Automatic Capability Evaluator for Multimodal Medical Models
Paper and Code
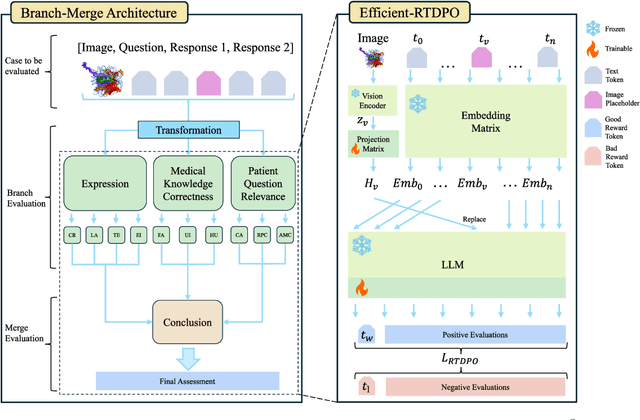
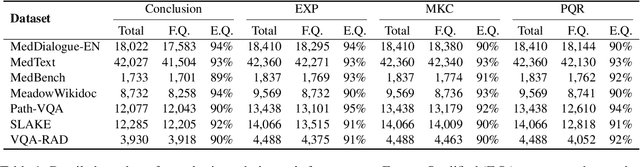
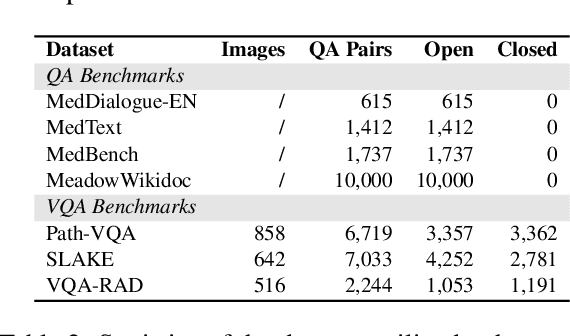
As multimodal large language models (MLLMs) gain prominence in the medical field, the need for precise evaluation methods to assess their effectiveness has become critical. While benchmarks provide a reliable means to evaluate the capabilities of MLLMs, traditional metrics like ROUGE and BLEU employed for open domain evaluation only focus on token overlap and may not align with human judgment. Although human evaluation is more reliable, it is labor-intensive, costly, and not scalable. LLM-based evaluation methods have proven promising, but to date, there is still an urgent need for open-source multimodal LLM-based evaluators in the medical field. To address this issue, we introduce ACE-$M^3$, an open-sourced \textbf{A}utomatic \textbf{C}apability \textbf{E}valuator for \textbf{M}ultimodal \textbf{M}edical \textbf{M}odels specifically designed to assess the question answering abilities of medical MLLMs. It first utilizes a branch-merge architecture to provide both detailed analysis and a concise final score based on standard medical evaluation criteria. Subsequently, a reward token-based direct preference optimization (RTDPO) strategy is incorporated to save training time without compromising performance of our model. Extensive experiments have demonstrated the effectiveness of our ACE-$M^3$ model\footnote{\url{https://huggingface.co/collections/AIUSRTMP/ace-m3-67593297ff391b93e3e5d068}} in evaluating the capabilities of medical MLLMs.