 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGMark: Attention-Guided Dynamic Watermarking for Large Vision-Language Models
Feb 10, 2026Watermarking has emerged as a pivotal solution for content traceability and intellectual property protection in Large Vision-Language Models (LVLMs). However, vision-agnostic watermarks may introduce visually irrelevant tokens and disrupt visual grounding by enforcing indiscriminate pseudo-random biases. Additionally, current vision-specific watermarks rely on a static, one-time estimation of vision critical weights and ignore the weight distribution density when determining the proportion of protected tokens. This design fails to account for dynamic changes in visual dependence during generation and may introduce low-quality tokens in the long tail. To address these challenges, we propose Attention-Guided Dynamic Watermarking (AGMark), a novel framework that embeds detectable signals while strictly preserving visual fidelity. At each decoding step, AGMark first dynamically identifies semantic-critical evidence based on attention weights for visual relevance, together with context-aware coherence cues, resulting in a more adaptive and well-calibrated evidence-weight distribution. It then determines the proportion of semantic-critical tokens by jointly considering uncertainty awareness (token entropy) and evidence calibration (weight density), thereby enabling adaptive vocabulary partitioning to avoid irrelevant tokens. Empirical results confirm that AGMark outperforms conventional methods, observably improving generation quality and yielding particularly strong gains in visual semantic fidelity in the later stages of generation. The framework maintains highly competitive detection accuracy (at least 99.36\% AUC) and robust attack resilience (at least 88.61\% AUC) without sacrificing inference efficiency, effectively establishing a new standard for reliability-preserving multi-modal watermarking.
Segmentation and Processing of German Court Decisions from Open Legal Data
Jan 04, 2026The availability of structured legal data is important for advancing Natural Language Processing (NLP) techniques for the German legal system. One of the most widely used datasets, Open Legal Data, provides a large-scale collection of German court decisions. While the metadata in this raw dataset is consistently structured, the decision texts themselves are inconsistently formatted and often lack clearly marked sections. Reliable separation of these sections is important not only for rhetorical role classification but also for downstream tasks such as retrieval and citation analysis. In this work, we introduce a cleaned and sectioned dataset of 251,038 German court decisions derived from the official Open Legal Data dataset. We systematically separated three important sections in German court decisions, namely Tenor (operative part of the decision), Tatbestand (facts of the case), and Entscheidungsgründe (judicial reasoning), which are often inconsistently represented in the original dataset. To ensure the reliability of our extraction process, we used Cochran's formula with a 95% confidence level and a 5% margin of error to draw a statistically representative random sample of 384 cases, and manually verified that all three sections were correctly identified. We also extracted the Rechtsmittelbelehrung (appeal notice) as a separate field, since it is a procedural instruction and not part of the decision itself. The resulting corpus is publicly available in the JSONL format, making it an accessible resource for further research on the German legal system.
* Accepted and published as a research article in Legal Knowledge and Information Systems (JURIX 2025 proceedings, IOS Press). Pages 276--281
GorillaWatch: An Automated System for In-the-Wild Gorilla Re-Identification and Population Monitoring
Dec 08, 2025
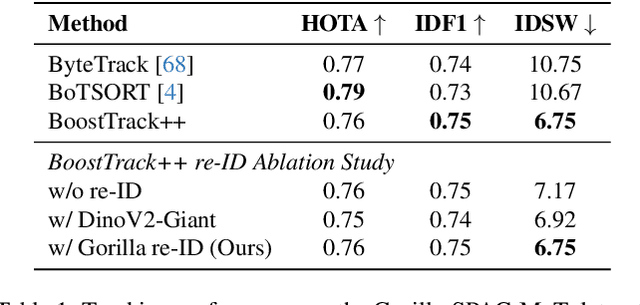

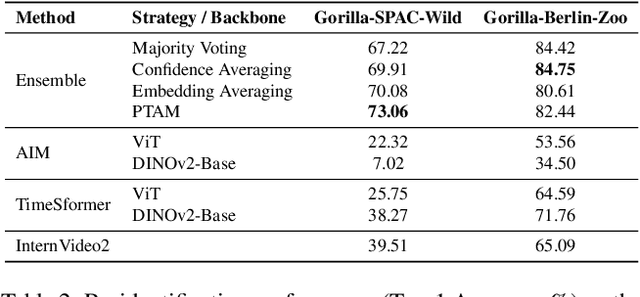
Monitoring critically endangered western lowland gorillas is currently hampered by the immense manual effort required to re-identify individuals from vast archives of camera trap footage. The primary obstacle to automating this process has been the lack of large-scale, "in-the-wild" video datasets suitable for training robust deep learning models. To address this gap, we introduce a comprehensive benchmark with three novel datasets: Gorilla-SPAC-Wild, the largest video dataset for wild primate re-identification to date; Gorilla-Berlin-Zoo, for assessing cross-domain re-identification generalization; and Gorilla-SPAC-MoT, for evaluating multi-object tracking in camera trap footage. Building on these datasets, we present GorillaWatch, an end-to-end pipeline integrating detection, tracking, and re-identification. To exploit temporal information, we introduce a multi-frame self-supervised pretraining strategy that leverages consistency in tracklets to learn domain-specific features without manual labels. To ensure scientific validity, a differentiable adaptation of AttnLRP verifies that our model relies on discriminative biometric traits rather than background correlations. Extensive benchmarking subsequently demonstrates that aggregating features from large-scale image backbones outperforms specialized video architectures. Finally, we address unsupervised population counting by integrating spatiotemporal constraints into standard clustering to mitigate over-segmentation. We publicly release all code and datasets to facilitate scalable, non-invasive monitoring of endangered species
Pretrained LLMs Learn Multiple Types of Uncertainty
May 27, 2025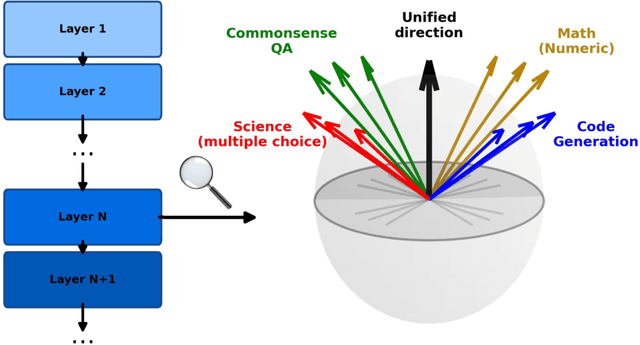

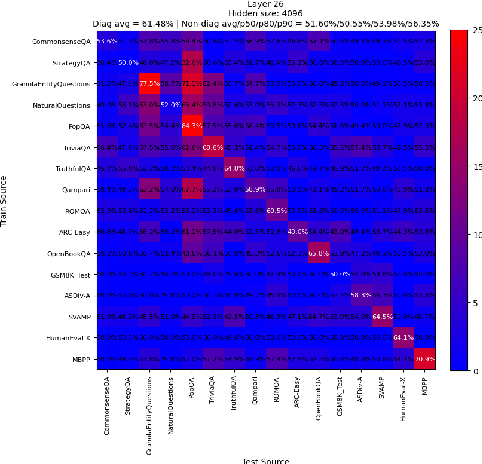
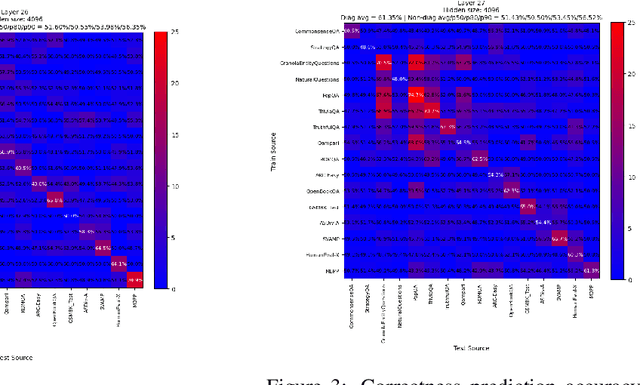
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we study how well LLMs capture uncertainty, without explicitly being trained for that. We show that, if considering uncertainty as a linear concept in the model's latent space, it might indeed be captured, even after only pretraining. We further show that, though unintuitive, LLMs appear to capture several different types of uncertainty, each of which can be useful to predict the correctness for a specific task or benchmark. Furthermore, we provide in-depth results such as demonstrating a correlation between our correction prediction and the model's ability to abstain from misinformation using words, and the lack of impact of model scaling for capturing uncertainty. Finally, we claim that unifying the uncertainty types as a single one using instruction-tuning or [IDK]-token tuning is helpful for the model in terms of correctness prediction.
AweDist: Attention-aware Embedding Distillation for New Input Token Embeddings
May 26, 2025Current language models rely on static vocabularies determined at pretraining time, which can lead to decreased performance and increased computational cost for domains underrepresented in the original vocabulary. New tokens can be added to solve this problem, when coupled with a good initialization for their new embeddings. However, existing embedding initialization methods either require expensive further training or pretraining of additional modules. In this paper, we propose AweDist and show that by distilling representations obtained using the original tokenization, we can quickly learn high-quality input embeddings for new tokens. Experimental results with a wide range of open-weight models show that AweDist is able to outperform even strong baselines.
InFact: Informativeness Alignment for Improved LLM Factuality
May 26, 2025Factual completeness is a general term that captures how detailed and informative a factually correct text is. For instance, the factual sentence ``Barack Obama was born in the United States'' is factually correct, though less informative than the factual sentence ``Barack Obama was born in Honolulu, Hawaii, United States''. Despite the known fact that LLMs tend to hallucinate and generate factually incorrect text, they might also tend to choose to generate factual text that is indeed factually correct and yet less informative than other, more informative choices. In this work, we tackle this problem by proposing an informativeness alignment mechanism. This mechanism takes advantage of recent factual benchmarks to propose an informativeness alignment objective. This objective prioritizes answers that are both correct and informative. A key finding of our work is that when training a model to maximize this objective or optimize its preference, we can improve not just informativeness but also factuality.
Image Tokens Matter: Mitigating Hallucination in Discrete Tokenizer-based Large Vision-Language Models via Latent Editing
May 24, 2025Large Vision-Language Models (LVLMs) with discrete image tokenizers unify multimodal representations by encoding visual inputs into a finite set of tokens. Despite their effectiveness, we find that these models still hallucinate non-existent objects. We hypothesize that this may be due to visual priors induced during training: When certain image tokens frequently co-occur in the same spatial regions and represent shared objects, they become strongly associated with the verbalizations of those objects. As a result, the model may hallucinate by evoking visually absent tokens that often co-occur with present ones. To test this assumption, we construct a co-occurrence graph of image tokens using a segmentation dataset and employ a Graph Neural Network (GNN) with contrastive learning followed by a clustering method to group tokens that frequently co-occur in similar visual contexts. We find that hallucinations predominantly correspond to clusters whose tokens dominate the input, and more specifically, that the visually absent tokens in those clusters show much higher correlation with hallucinated objects compared to tokens present in the image. Based on this observation, we propose a hallucination mitigation method that suppresses the influence of visually absent tokens by modifying latent image embeddings during generation. Experiments show our method reduces hallucinations while preserving expressivity. Code is available at https://github.com/weixingW/CGC-VTD/tree/main
Hierarchical Safety Realignment: Lightweight Restoration of Safety in Pruned Large Vision-Language Models
May 22, 2025With the increasing size of Large Vision-Language Models (LVLMs), network pruning techniques aimed at compressing models for deployment in resource-constrained environments have garnered significant attention. However, we observe that pruning often leads to a degradation in safety performance. To address this issue, we present a novel and lightweight approach, termed Hierarchical Safety Realignment (HSR). HSR operates by first quantifying the contribution of each attention head to safety, identifying the most critical ones, and then selectively restoring neurons directly within these attention heads that play a pivotal role in maintaining safety. This process hierarchically realigns the safety of pruned LVLMs, progressing from the attention head level to the neuron level. We validate HSR across various models and pruning strategies, consistently achieving notable improvements in safety performance. To our knowledge, this is the first work explicitly focused on restoring safety in LVLMs post-pruning.
AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
May 17, 2025With the proliferation of large language models (LLMs) in the medical domain, there is increasing demand for improved evaluation techniques to assess their capabilities. However, traditional metrics like F1 and ROUGE, which rely on token overlaps to measure quality, significantly overlook the importance of medical terminology. While human evaluation tends to be more reliable, it can be very costly and may as well suffer from inaccuracies due to limits in human expertise and motivation. Although there are some evaluation methods based on LLMs, their usability in the medical field is limited due to their proprietary nature or lack of expertise. To tackle these challenges, we present AutoMedEval, an open-sourced automatic evaluation model with 13B parameters specifically engineered to measure the question-answering proficiency of medical LLMs. The overarching objective of AutoMedEval is to assess the quality of responses produced by diverse models, aspiring to significantly reduce the dependence on human evaluation. Specifically, we propose a hierarchical training method involving curriculum instruction tuning and an iterative knowledge introspection mechanism, enabling AutoMedEval to acquire professional medical assessment capabilities with limited instructional data. Human evaluations indicate that AutoMedEval surpasses other baselines in terms of correlation with human judgments.
Hierarchical Divide-and-Conquer for Fine-Grained Alignment in LLM-Based Medical Evaluation
Jan 12, 2025In the rapidly evolving landscape of large language models (LLMs) for medical applications, ensuring the reliability and accuracy of these models in clinical settings is paramount. Existing benchmarks often focus on fixed-format tasks like multiple-choice QA, which fail to capture the complexity of real-world clinical diagnostics. Moreover, traditional evaluation metrics and LLM-based evaluators struggle with misalignment, often providing oversimplified assessments that do not adequately reflect human judgment. To address these challenges, we introduce HDCEval, a Hierarchical Divide-and-Conquer Evaluation framework tailored for fine-grained alignment in medical evaluation. HDCEval is built on a set of fine-grained medical evaluation guidelines developed in collaboration with professional doctors, encompassing Patient Question Relevance, Medical Knowledge Correctness, and Expression. The framework decomposes complex evaluation tasks into specialized subtasks, each evaluated by expert models trained through Attribute-Driven Token Optimization (ADTO) on a meticulously curated preference dataset. This hierarchical approach ensures that each aspect of the evaluation is handled with expert precision, leading to a significant improvement in alignment with human evaluators.