 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Divide-and-Conquer for Fine-Grained Alignment in LLM-Based Medical Evaluation
Jan 12, 2025In the rapidly evolving landscape of large language models (LLMs) for medical applications, ensuring the reliability and accuracy of these models in clinical settings is paramount. Existing benchmarks often focus on fixed-format tasks like multiple-choice QA, which fail to capture the complexity of real-world clinical diagnostics. Moreover, traditional evaluation metrics and LLM-based evaluators struggle with misalignment, often providing oversimplified assessments that do not adequately reflect human judgment. To address these challenges, we introduce HDCEval, a Hierarchical Divide-and-Conquer Evaluation framework tailored for fine-grained alignment in medical evaluation. HDCEval is built on a set of fine-grained medical evaluation guidelines developed in collaboration with professional doctors, encompassing Patient Question Relevance, Medical Knowledge Correctness, and Expression. The framework decomposes complex evaluation tasks into specialized subtasks, each evaluated by expert models trained through Attribute-Driven Token Optimization (ADTO) on a meticulously curated preference dataset. This hierarchical approach ensures that each aspect of the evaluation is handled with expert precision, leading to a significant improvement in alignment with human evaluators.
NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
Dec 17, 2024The emergence of finetuning-as-a-service has revealed a new vulnerability in large language models (LLMs). A mere handful of malicious data uploaded by users can subtly manipulate the finetuning process, resulting in an alignment-broken model. Existing methods to counteract fine-tuning attacks typically require substantial computational resources. Even with parameter-efficient techniques like LoRA, gradient updates remain essential. To address these challenges, we propose \textbf{N}euron-\textbf{L}evel \textbf{S}afety \textbf{R}ealignment (\textbf{NLSR}), a training-free framework that restores the safety of LLMs based on the similarity difference of safety-critical neurons before and after fine-tuning. The core of our framework is first to construct a safety reference model from an initially aligned model to amplify safety-related features in neurons. We then utilize this reference model to identify safety-critical neurons, which we prepare as patches. Finally, we selectively restore only those neurons that exhibit significant similarity differences by transplanting these prepared patches, thereby minimally altering the fine-tuned model. Extensive experiments demonstrate significant safety enhancements in fine-tuned models across multiple downstream tasks, while greatly maintaining task-level accuracy. Our findings suggest regions of some safety-critical neurons show noticeable differences after fine-tuning, which can be effectively corrected by transplanting neurons from the reference model without requiring additional training. The code will be available at \url{https://github.com/xinykou/NLSR}
ACE-$M^3$: Automatic Capability Evaluator for Multimodal Medical Models
Dec 16, 2024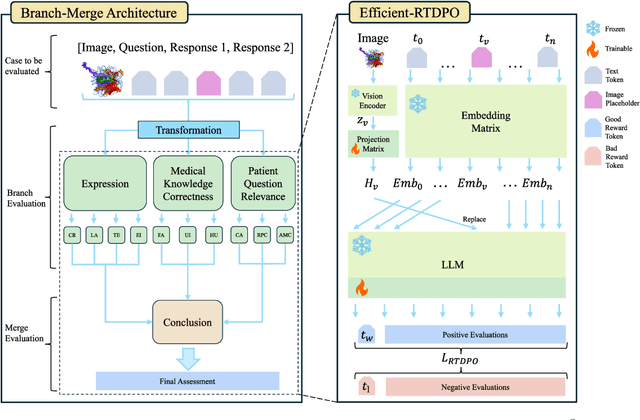
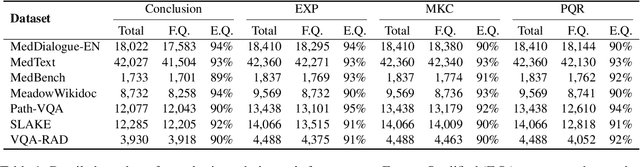
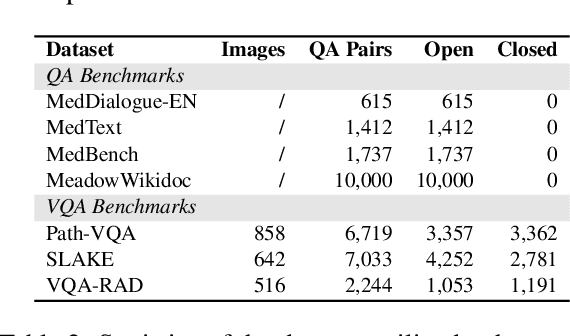
As multimodal large language models (MLLMs) gain prominence in the medical field, the need for precise evaluation methods to assess their effectiveness has become critical. While benchmarks provide a reliable means to evaluate the capabilities of MLLMs, traditional metrics like ROUGE and BLEU employed for open domain evaluation only focus on token overlap and may not align with human judgment. Although human evaluation is more reliable, it is labor-intensive, costly, and not scalable. LLM-based evaluation methods have proven promising, but to date, there is still an urgent need for open-source multimodal LLM-based evaluators in the medical field. To address this issue, we introduce ACE-$M^3$, an open-sourced \textbf{A}utomatic \textbf{C}apability \textbf{E}valuator for \textbf{M}ultimodal \textbf{M}edical \textbf{M}odels specifically designed to assess the question answering abilities of medical MLLMs. It first utilizes a branch-merge architecture to provide both detailed analysis and a concise final score based on standard medical evaluation criteria. Subsequently, a reward token-based direct preference optimization (RTDPO) strategy is incorporated to save training time without compromising performance of our model. Extensive experiments have demonstrated the effectiveness of our ACE-$M^3$ model\footnote{\url{https://huggingface.co/collections/AIUSRTMP/ace-m3-67593297ff391b93e3e5d068}} in evaluating the capabilities of medical MLLMs.
A safety realignment framework via subspace-oriented model fusion for large language models
May 15, 2024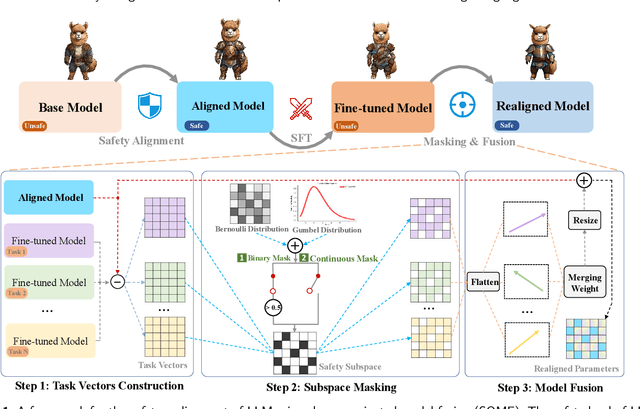
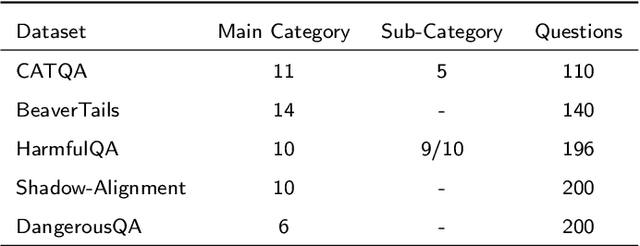
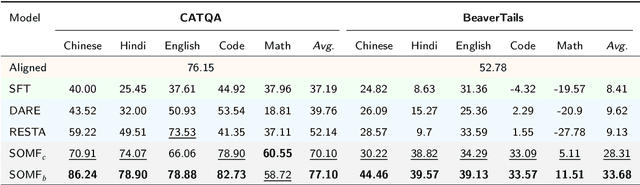
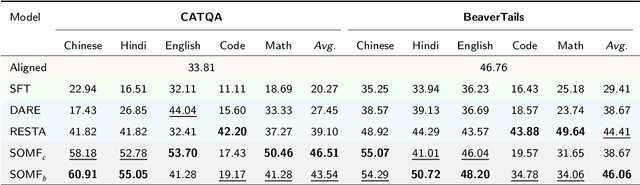
The current safeguard mechanisms for large language models (LLMs) are indeed susceptible to jailbreak attacks, making them inherently fragile. Even the process of fine-tuning on apparently benign data for downstream tasks can jeopardize safety. One potential solution is to conduct safety fine-tuning subsequent to downstream fine-tuning. However, there's a risk of catastrophic forgetting during safety fine-tuning, where LLMs may regain safety measures but lose the task-specific knowledge acquired during downstream fine-tuning. In this paper, we introduce a safety realignment framework through subspace-oriented model fusion (SOMF), aiming to combine the safeguard capabilities of initially aligned model and the current fine-tuned model into a realigned model. Our approach begins by disentangling all task vectors from the weights of each fine-tuned model. We then identify safety-related regions within these vectors by subspace masking techniques. Finally, we explore the fusion of the initial safely aligned LLM with all task vectors based on the identified safety subspace. We validate that our safety realignment framework satisfies the safety requirements of a single fine-tuned model as well as multiple models during their fusion. Our findings confirm that SOMF preserves safety without notably compromising performance on downstream tasks, including instruction following in Chinese, English, and Hindi, as well as problem-solving capabilities in Code and Math.