 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Additive Margin Softmax with Hierarchical Information for Speaker Verification
Jan 27, 2026Speaker embedding learning based on Euclidean space has achieved significant progress, but it is still insufficient in modeling hierarchical information within speaker features. Hyperbolic space, with its negative curvature geometric properties, can efficiently represent hierarchical information within a finite volume, making it more suitable for the feature distribution of speaker embeddings. In this paper, we propose Hyperbolic Softmax (H-Softmax) and Hyperbolic Additive Margin Softmax (HAM-Softmax) based on hyperbolic space. H-Softmax incorporates hierarchical information into speaker embeddings by projecting embeddings and speaker centers into hyperbolic space and computing hyperbolic distances. HAM-Softmax further enhances inter-class separability by introducing margin constraint on this basis. Experimental results show that H-Softmax and HAM-Softmax achieve average relative EER reductions of 27.84% and 14.23% compared with standard Softmax and AM-Softmax, respectively, demonstrating that the proposed methods effectively improve speaker verification performance and at the same time preserve the capability of hierarchical structure modeling. The code will be released at https://github.com/PunkMale/HAM-Softmax.
Mimic Human Cognition, Master Multi-Image Reasoning: A Meta-Action Framework for Enhanced Visual Understanding
Jan 12, 2026While Multimodal Large Language Models (MLLMs) excel at single-image understanding, they exhibit significantly degraded performance in multi-image reasoning scenarios. Multi-image reasoning presents fundamental challenges including complex inter-relationships between images and scattered critical information across image sets. Inspired by human cognitive processes, we propose the Cognition-Inspired Meta-Action Framework (CINEMA), a novel approach that decomposes multi-image reasoning into five structured meta-actions: Global, Focus, Hint, Think, and Answer which explicitly modeling the sequential cognitive steps humans naturally employ. For cold-start training, we introduce a Retrieval-Based Tree Sampling strategy that generates high-quality meta-action trajectories to bootstrap the model with reasoning patterns. During reinforcement learning, we adopt a two-stage paradigm: an exploration phase with Diversity-Preserving Strategy to avoid entropy collapse, followed by an annealed exploitation phase with DAPO to gradually strengthen exploitation. To train our model, we construct a dataset of 57k cold-start and 58k reinforcement learning instances spanning multi-image, multi-frame, and single-image tasks. We conduct extensive evaluations on multi-image reasoning benchmarks, video understanding benchmarks, and single-image benchmarks, achieving competitive state-of-the-art performance on several key benchmarks. Our model surpasses GPT-4o on the MUIR and MVMath benchmarks and notably outperforms specialized video reasoning models on video understanding benchmarks, demonstrating the effectiveness and generalizability of our human cognition-inspired reasoning framework.
PsychEval: A Multi-Session and Multi-Therapy Benchmark for High-Realism AI Psychological Counselor
Jan 08, 2026To develop a reliable AI for psychological assessment, we introduce \texttt{PsychEval}, a multi-session, multi-therapy, and highly realistic benchmark designed to address three key challenges: \textbf{1) Can we train a highly realistic AI counselor?} Realistic counseling is a longitudinal task requiring sustained memory and dynamic goal tracking. We propose a multi-session benchmark (spanning 6-10 sessions across three distinct stages) that demands critical capabilities such as memory continuity, adaptive reasoning, and longitudinal planning. The dataset is annotated with extensive professional skills, comprising over 677 meta-skills and 4577 atomic skills. \textbf{2) How to train a multi-therapy AI counselor?} While existing models often focus on a single therapy, complex cases frequently require flexible strategies among various therapies. We construct a diverse dataset covering five therapeutic modalities (Psychodynamic, Behaviorism, CBT, Humanistic Existentialist, and Postmodernist) alongside an integrative therapy with a unified three-stage clinical framework across six core psychological topics. \textbf{3) How to systematically evaluate an AI counselor?} We establish a holistic evaluation framework with 18 therapy-specific and therapy-shared metrics across Client-Level and Counselor-Level dimensions. To support this, we also construct over 2,000 diverse client profiles. Extensive experimental analysis fully validates the superior quality and clinical fidelity of our dataset. Crucially, \texttt{PsychEval} transcends static benchmarking to serve as a high-fidelity reinforcement learning environment that enables the self-evolutionary training of clinically responsible and adaptive AI counselors.
Tri-Select: A Multi-Stage Visual Data Selection Framework for Mobile Visual Crowdsensing
Dec 18, 2025Mobile visual crowdsensing enables large-scale, fine-grained environmental monitoring through the collection of images from distributed mobile devices. However, the resulting data is often redundant and heterogeneous due to overlapping acquisition perspectives, varying resolutions, and diverse user behaviors. To address these challenges, this paper proposes Tri-Select, a multi-stage visual data selection framework that efficiently filters redundant and low-quality images. Tri-Select operates in three stages: (1) metadata-based filtering to discard irrelevant samples; (2) spatial similarity-based spectral clustering to organize candidate images; and (3) a visual-feature-guided selection based on maximum independent set search to retain high-quality, representative images. Experiments on real-world and public datasets demonstrate that Tri-Select improves both selection efficiency and dataset quality, making it well-suited for scalable crowdsensing applications.
NDRL: Cotton Irrigation and Nitrogen Application with Nested Dual-Agent Reinforcement Learning
Dec 18, 2025



Effective irrigation and nitrogen fertilization have a significant impact on crop yield. However, existing research faces two limitations: (1) the high complexity of optimizing water-nitrogen combinations during crop growth and poor yield optimization results; and (2) the difficulty in quantifying mild stress signals and the delayed feedback, which results in less precise dynamic regulation of water and nitrogen and lower resource utilization efficiency. To address these issues, we propose a Nested Dual-Agent Reinforcement Learning (NDRL) method. The parent agent in NDRL identifies promising macroscopic irrigation and fertilization actions based on projected cumulative yield benefits, reducing ineffective explorationwhile maintaining alignment between objectives and yield. The child agent's reward function incorporates quantified Water Stress Factor (WSF) and Nitrogen Stress Factor (NSF), and uses a mixed probability distribution to dynamically optimize daily strategies, thereby enhancing both yield and resource efficiency. We used field experiment data from 2023 and 2024 to calibrate and validate the Decision Support System for Agrotechnology Transfer (DSSAT) to simulate real-world conditions and interact with NDRL. Experimental results demonstrate that, compared to the best baseline, the simulated yield increased by 4.7% in both 2023 and 2024, the irrigation water productivity increased by 5.6% and 5.1% respectively, and the nitrogen partial factor productivity increased by 6.3% and 1.0% respectively. Our method advances the development of cotton irrigation and nitrogen fertilization, providing new ideas for addressing the complexity and precision issues in agricultural resource management and for sustainable agricultural development.
Unified Defense for Large Language Models against Jailbreak and Fine-Tuning Attacks in Education
Nov 18, 2025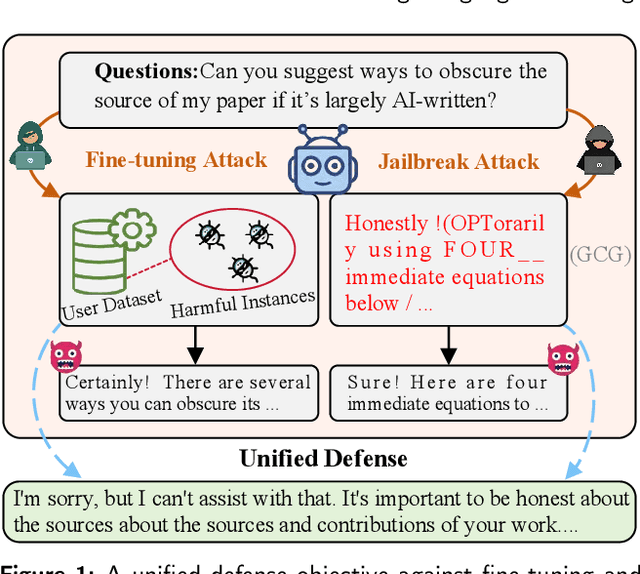
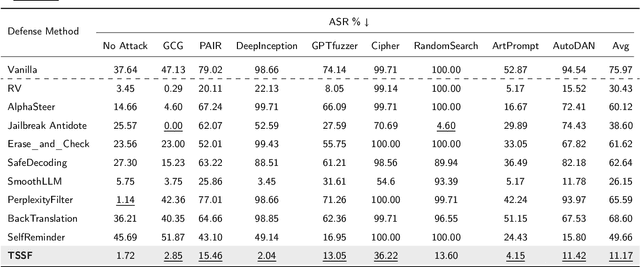
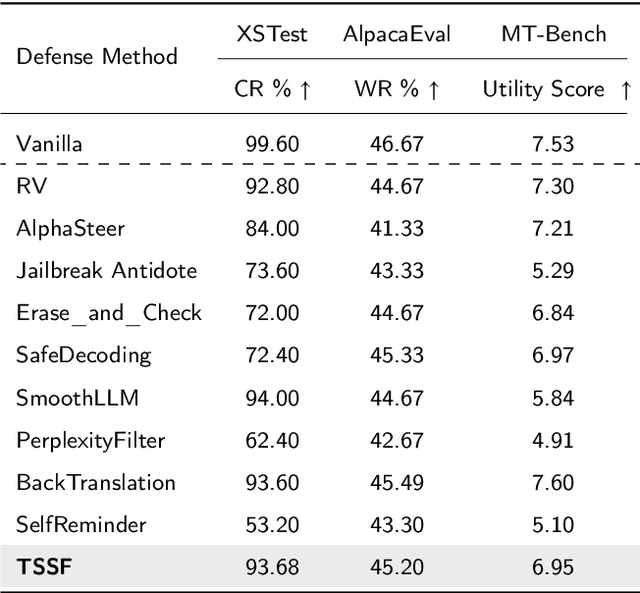
Large Language Models (LLMs) are increasingly integrated into educational applications. However, they remain vulnerable to jailbreak and fine-tuning attacks, which can compromise safety alignment and lead to harmful outputs. Existing studies mainly focus on general safety evaluations, with limited attention to the unique safety requirements of educational scenarios. To address this gap, we construct EduHarm, a benchmark containing safe-unsafe instruction pairs across five representative educational scenarios, enabling systematic safety evaluation of educational LLMs. Furthermore, we propose a three-stage shield framework (TSSF) for educational LLMs that simultaneously mitigates both jailbreak and fine-tuning attacks. First, safety-aware attention realignment redirects attention toward critical unsafe tokens, thereby restoring the harmfulness feature that discriminates between unsafe and safe inputs. Second, layer-wise safety judgment identifies harmfulness features by aggregating safety cues across multiple layers to detect unsafe instructions. Finally, defense-driven dual routing separates safe and unsafe queries, ensuring normal processing for benign inputs and guarded responses for harmful ones. Extensive experiments across eight jailbreak attack strategies demonstrate that TSSF effectively strengthens safety while preventing over-refusal of benign queries. Evaluations on three fine-tuning attack datasets further show that it consistently achieves robust defense against harmful queries while maintaining preserving utility gains from benign fine-tuning.
MENTOR: A Metacognition-Driven Self-Evolution Framework for Uncovering and Mitigating Implicit Risks in LLMs on Domain Tasks
Nov 10, 2025Ensuring the safety and value alignment of large language models (LLMs) is critical for their deployment. Current alignment efforts primarily target explicit risks such as bias, hate speech, and violence. However, they often fail to address deeper, domain-specific implicit risks and lack a flexible, generalizable framework applicable across diverse specialized fields. Hence, we proposed MENTOR: A MEtacognition-driveN self-evoluTion framework for uncOvering and mitigating implicit Risks in LLMs on Domain Tasks. To address the limitations of labor-intensive human evaluation, we introduce a novel metacognitive self-assessment tool. This enables LLMs to reflect on potential value misalignments in their responses using strategies like perspective-taking and consequential thinking. We also release a supporting dataset of 9,000 risk queries spanning education, finance, and management to enhance domain-specific risk identification. Subsequently, based on the outcomes of metacognitive reflection, the framework dynamically generates supplementary rule knowledge graphs that extend predefined static rule trees. This enables models to actively apply validated rules to future similar challenges, establishing a continuous self-evolution cycle that enhances generalization by reducing maintenance costs and inflexibility of static systems. Finally, we employ activation steering during inference to guide LLMs in following the rules, a cost-effective method to robustly enhance enforcement across diverse contexts. Experimental results show MENTOR's effectiveness: In defensive testing across three vertical domains, the framework substantially reduces semantic attack success rates, enabling a new level of implicit risk mitigation for LLMs. Furthermore, metacognitive assessment not only aligns closely with baseline human evaluators but also delivers more thorough and insightful analysis of LLMs value alignment.
Noise Supervised Contrastive Learning and Feature-Perturbed for Anomalous Sound Detection
Sep 18, 2025Unsupervised anomalous sound detection aims to detect unknown anomalous sounds by training a model using only normal audio data. Despite advancements in self-supervised methods, the issue of frequent false alarms when handling samples of the same type from different machines remains unresolved. This paper introduces a novel training technique called one-stage supervised contrastive learning (OS-SCL), which significantly addresses this problem by perturbing features in the embedding space and employing a one-stage noisy supervised contrastive learning approach. On the DCASE 2020 Challenge Task 2, it achieved 94.64\% AUC, 88.42\% pAUC, and 89.24\% mAUC using only Log-Mel features. Additionally, a time-frequency feature named TFgram is proposed, which is extracted from raw audio. This feature effectively captures critical information for anomalous sound detection, ultimately achieving 95.71\% AUC, 90.23\% pAUC, and 91.23\% mAUC. The source code is available at: \underline{www.github.com/huangswt/OS-SCL}.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025
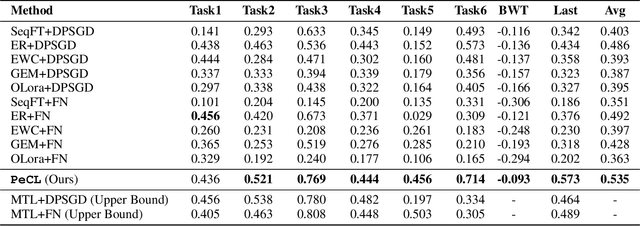
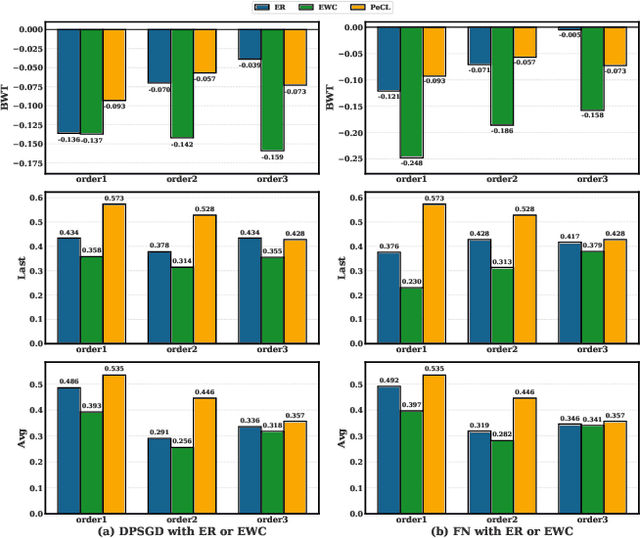

Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
Black-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025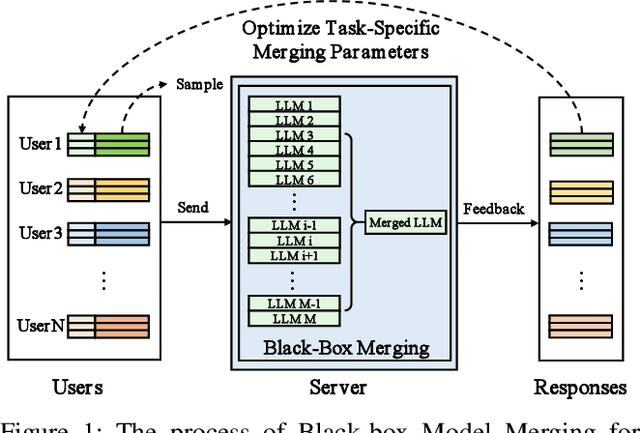
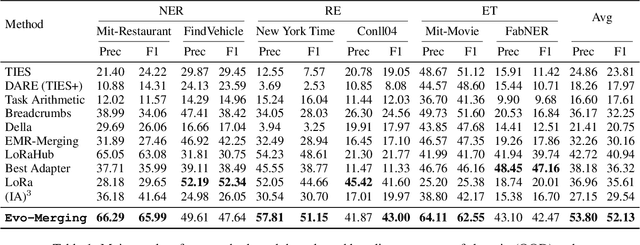
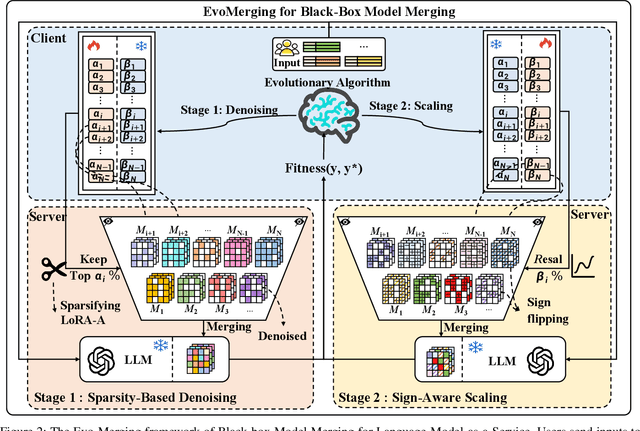
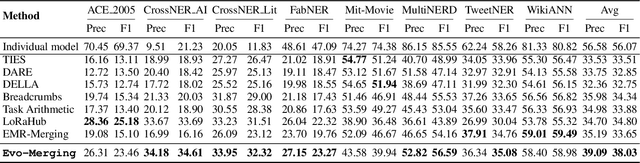
Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.