 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025
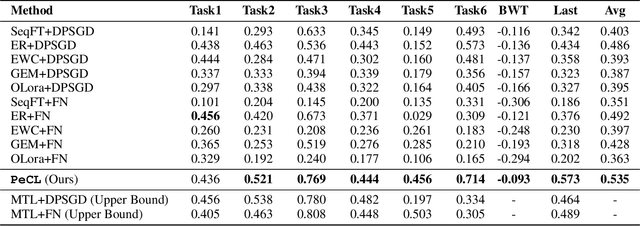
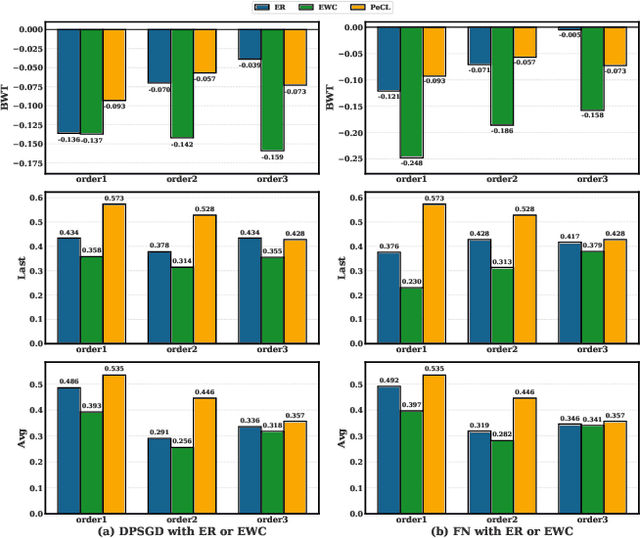

Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
Mitigating Strategy Preference Bias in Emotional Support Conversation via Uncertainty Estimations
Sep 16, 2025Emotional support conversation (ESC) aims to alleviate distress through empathetic dialogue, yet large language models (LLMs) face persistent challenges in delivering effective ESC due to low accuracy in strategy planning. Moreover, there is a considerable preference bias towards specific strategies. Prior methods using fine-tuned strategy planners have shown potential in reducing such bias, while the underlying causes of the preference bias in LLMs have not well been studied. To address these issues, we first reveal the fundamental causes of the bias by identifying the knowledge boundaries of LLMs in strategy planning. Then, we propose an approach to mitigate the bias by reinforcement learning with a dual reward function, which optimizes strategy planning via both accuracy and entropy-based confidence for each region according to the knowledge boundaries. Experiments on the ESCov and ExTES datasets with multiple LLM backbones show that our approach outperforms the baselines, confirming the effectiveness of our approach.
RMoA: Optimizing Mixture-of-Agents through Diversity Maximization and Residual Compensation
May 30, 2025Although multi-agent systems based on large language models show strong capabilities on multiple tasks, they are still limited by high computational overhead, information loss, and robustness. Inspired by ResNet's residual learning, we propose Residual Mixture-of-Agents (RMoA), integrating residual connections to optimize efficiency and reliability. To maximize information utilization from model responses while minimizing computational costs, we innovatively design an embedding-based diversity selection mechanism that greedily selects responses via vector similarity. Furthermore, to mitigate iterative information degradation, we introduce a Residual Extraction Agent to preserve cross-layer incremental information by capturing inter-layer response differences, coupled with a Residual Aggregation Agent for hierarchical information integration. Additionally, we propose an adaptive termination mechanism that dynamically halts processing based on residual convergence, further improving inference efficiency. RMoA achieves state-of-the-art performance on the benchmarks of across alignment, mathematical reasoning, code generation, and multitasking understanding, while significantly reducing computational overhead. Code is available at https://github.com/mindhunter01/RMoA.
Task-Core Memory Management and Consolidation for Long-term Continual Learning
May 15, 2025



In this paper, we focus on a long-term continual learning (CL) task, where a model learns sequentially from a stream of vast tasks over time, acquiring new knowledge while retaining previously learned information in a manner akin to human learning. Unlike traditional CL settings, long-term CL involves handling a significantly larger number of tasks, which exacerbates the issue of catastrophic forgetting. Our work seeks to address two critical questions: 1) How do existing CL methods perform in the context of long-term CL? and 2) How can we mitigate the catastrophic forgetting that arises from prolonged sequential updates? To tackle these challenges, we propose a novel framework inspired by human memory mechanisms for long-term continual learning (Long-CL). Specifically, we introduce a task-core memory management strategy to efficiently index crucial memories and adaptively update them as learning progresses. Additionally, we develop a long-term memory consolidation mechanism that selectively retains hard and discriminative samples, ensuring robust knowledge retention. To facilitate research in this area, we construct and release two multi-modal and textual benchmarks, MMLongCL-Bench and TextLongCL-Bench, providing a valuable resource for evaluating long-term CL approaches. Experimental results show that Long-CL outperforms the previous state-of-the-art by 7.4\% and 6.5\% AP on the two benchmarks, respectively, demonstrating the effectiveness of our approach.
Aesthetic Matters in Music Perception for Image Stylization: A Emotion-driven Music-to-Visual Manipulation
Jan 03, 2025



Emotional information is essential for enhancing human-computer interaction and deepening image understanding. However, while deep learning has advanced image recognition, the intuitive understanding and precise control of emotional expression in images remain challenging. Similarly, music research largely focuses on theoretical aspects, with limited exploration of its emotional dimensions and their integration with visual arts. To address these gaps, we introduce EmoMV, an emotion-driven music-to-visual manipulation method that manipulates images based on musical emotions. EmoMV combines bottom-up processing of music elements-such as pitch and rhythm-with top-down application of these emotions to visual aspects like color and lighting. We evaluate EmoMV using a multi-scale framework that includes image quality metrics, aesthetic assessments, and EEG measurements to capture real-time emotional responses. Our results demonstrate that EmoMV effectively translates music's emotional content into visually compelling images, advancing multimodal emotional integration and opening new avenues for creative industries and interactive technologies.
Moyun: A Diffusion-Based Model for Style-Specific Chinese Calligraphy Generation
Oct 10, 2024



Although Chinese calligraphy generation has achieved style transfer, generating calligraphy by specifying the calligrapher, font, and character style remains challenging. To address this, we propose a new Chinese calligraphy generation model 'Moyun' , which replaces the Unet in the Diffusion model with Vision Mamba and introduces the TripleLabel control mechanism to achieve controllable calligraphy generation. The model was tested on our large-scale dataset 'Mobao' of over 1.9 million images, and the results demonstrate that 'Moyun' can effectively control the generation process and produce calligraphy in the specified style. Even for calligraphy the calligrapher has not written, 'Moyun' can generate calligraphy that matches the style of the calligrapher.
MindScope: Exploring cognitive biases in large language models through Multi-Agent Systems
Oct 06, 2024



Detecting cognitive biases in large language models (LLMs) is a fascinating task that aims to probe the existing cognitive biases within these models. Current methods for detecting cognitive biases in language models generally suffer from incomplete detection capabilities and a restricted range of detectable bias types. To address this issue, we introduced the 'MindScope' dataset, which distinctively integrates static and dynamic elements. The static component comprises 5,170 open-ended questions spanning 72 cognitive bias categories. The dynamic component leverages a rule-based, multi-agent communication framework to facilitate the generation of multi-round dialogues. This framework is flexible and readily adaptable for various psychological experiments involving LLMs. In addition, we introduce a multi-agent detection method applicable to a wide range of detection tasks, which integrates Retrieval-Augmented Generation (RAG), competitive debate, and a reinforcement learning-based decision module. Demonstrating substantial effectiveness, this method has shown to improve detection accuracy by as much as 35.10% compared to GPT-4. Codes and appendix are available at https://github.com/2279072142/MindScope.
Multi-Type Preference Learning: Empowering Preference-Based Reinforcement Learning with Equal Preferences
Sep 11, 2024

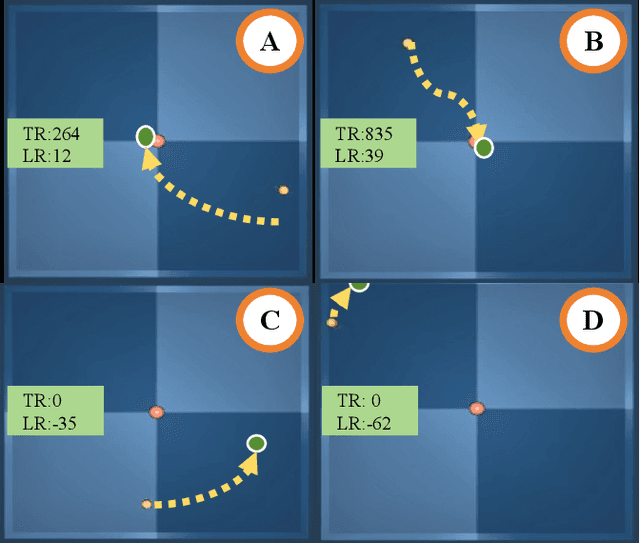
Preference-Based reinforcement learning (PBRL) learns directly from the preferences of human teachers regarding agent behaviors without needing meticulously designed reward functions. However, existing PBRL methods often learn primarily from explicit preferences, neglecting the possibility that teachers may choose equal preferences. This neglect may hinder the understanding of the agent regarding the task perspective of the teacher, leading to the loss of important information. To address this issue, we introduce the Equal Preference Learning Task, which optimizes the neural network by promoting similar reward predictions when the behaviors of two agents are labeled as equal preferences. Building on this task, we propose a novel PBRL method, Multi-Type Preference Learning (MTPL), which allows simultaneous learning from equal preferences while leveraging existing methods for learning from explicit preferences. To validate our approach, we design experiments applying MTPL to four existing state-of-the-art baselines across ten locomotion and robotic manipulation tasks in the DeepMind Control Suite. The experimental results indicate that simultaneous learning from both equal and explicit preferences enables the PBRL method to more comprehensively understand the feedback from teachers, thereby enhancing feedback efficiency.
Fine-Grained Scene Image Classification with Modality-Agnostic Adapter
Jul 03, 2024



When dealing with the task of fine-grained scene image classification, most previous works lay much emphasis on global visual features when doing multi-modal feature fusion. In other words, models are deliberately designed based on prior intuitions about the importance of different modalities. In this paper, we present a new multi-modal feature fusion approach named MAA (Modality-Agnostic Adapter), trying to make the model learn the importance of different modalities in different cases adaptively, without giving a prior setting in the model architecture. More specifically, we eliminate the modal differences in distribution and then use a modality-agnostic Transformer encoder for a semantic-level feature fusion. Our experiments demonstrate that MAA achieves state-of-the-art results on benchmarks by applying the same modalities with previous methods. Besides, it is worth mentioning that new modalities can be easily added when using MAA and further boost the performance. Code is available at https://github.com/quniLcs/MAA.