 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFed-Signal: An ADR Prediction Model based on Federated Learning
Dec 29, 2025The adverse drug reactions (ADRs) predicted based on the biased records in FAERS (U.S. Food and Drug Administration Adverse Event Reporting System) may mislead diagnosis online. Generally, such problems are solved by optimizing reporting odds ratio (ROR) or proportional reporting ratio (PRR). However, these methods that rely on statistical methods cannot eliminate the biased data, leading to inaccurate signal prediction. In this paper, we propose PFed-signal, a federated learning-based signal prediction model of ADR, which utilizes the Euclidean distance to eliminate the biased data from FAERS, thereby improving the accuracy of ADR prediction. Specifically, we first propose Pfed-Split, a method to split the original dataset into a split dataset based on ADR. Then we propose ADR-signal, an ADR prediction model, including a biased data identification method based on federated learning and an ADR prediction model based on Transformer. The former identifies the biased data according to the Euclidean distance and generates a clean dataset by deleting the biased data. The latter is an ADR prediction model based on Transformer trained on the clean data set. The results show that the ROR and PRR on the clean dataset are better than those of the traditional methods. Furthermore, the accuracy rate, F1 score, recall rate and AUC of PFed-Signal are 0.887, 0.890, 0.913 and 0.957 respectively, which are higher than the baselines.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
SAS-Bench: A Fine-Grained Benchmark for Evaluating Short Answer Scoring with Large Language Models
May 15, 2025Subjective Answer Grading (SAG) plays a crucial role in education, standardized testing, and automated assessment systems, particularly for evaluating short-form responses in Short Answer Scoring (SAS). However, existing approaches often produce coarse-grained scores and lack detailed reasoning. Although large language models (LLMs) have demonstrated potential as zero-shot evaluators, they remain susceptible to bias, inconsistencies with human judgment, and limited transparency in scoring decisions. To overcome these limitations, we introduce SAS-Bench, a benchmark specifically designed for LLM-based SAS tasks. SAS-Bench provides fine-grained, step-wise scoring, expert-annotated error categories, and a diverse range of question types derived from real-world subject-specific exams. This benchmark facilitates detailed evaluation of model reasoning processes and explainability. We also release an open-source dataset containing 1,030 questions and 4,109 student responses, each annotated by domain experts. Furthermore, we conduct comprehensive experiments with various LLMs, identifying major challenges in scoring science-related questions and highlighting the effectiveness of few-shot prompting in improving scoring accuracy. Our work offers valuable insights into the development of more robust, fair, and educationally meaningful LLM-based evaluation systems.
A High-Dimensional Feature Selection Algorithm Based on Multiobjective Differential Evolution
May 09, 2025



Multiobjective feature selection seeks to determine the most discriminative feature subset by simultaneously optimizing two conflicting objectives: minimizing the number of selected features and the classification error rate. The goal is to enhance the model's predictive performance and computational efficiency. However, feature redundancy and interdependence in high-dimensional data present considerable obstacles to the search efficiency of optimization algorithms and the quality of the resulting solutions. To tackle these issues, we propose a high-dimensional feature selection algorithm based on multiobjective differential evolution. First, a population initialization strategy is designed by integrating feature weights and redundancy indices, where the population is divided into four subpopulations to improve the diversity and uniformity of the initial population. Then, a multiobjective selection mechanism is developed, in which feature weights guide the mutation process. The solution quality is further enhanced through nondominated sorting, with preference given to solutions with lower classification error, effectively balancing global exploration and local exploitation. Finally, an adaptive grid mechanism is applied in the objective space to identify densely populated regions and detect duplicated solutions. Experimental results on 11 UCI datasets of varying difficulty demonstrate that the proposed method significantly outperforms several state-of-the-art multiobjective feature selection approaches regarding feature selection performance.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Improving Low-Resource Sequence Labeling with Knowledge Fusion and Contextual Label Explanations
Jan 31, 2025



Sequence labeling remains a significant challenge in low-resource, domain-specific scenarios, particularly for character-dense languages like Chinese. Existing methods primarily focus on enhancing model comprehension and improving data diversity to boost performance. However, these approaches still struggle with inadequate model applicability and semantic distribution biases in domain-specific contexts. To overcome these limitations, we propose a novel framework that combines an LLM-based knowledge enhancement workflow with a span-based Knowledge Fusion for Rich and Efficient Extraction (KnowFREE) model. Our workflow employs explanation prompts to generate precise contextual interpretations of target entities, effectively mitigating semantic biases and enriching the model's contextual understanding. The KnowFREE model further integrates extension label features, enabling efficient nested entity extraction without relying on external knowledge during inference. Experiments on multiple Chinese domain-specific sequence labeling datasets demonstrate that our approach achieves state-of-the-art performance, effectively addressing the challenges posed by low-resource settings.
DSRC: Learning Density-insensitive and Semantic-aware Collaborative Representation against Corruptions
Dec 14, 2024



As a potential application of Vehicle-to-Everything (V2X) communication, multi-agent collaborative perception has achieved significant success in 3D object detection. While these methods have demonstrated impressive results on standard benchmarks, the robustness of such approaches in the face of complex real-world environments requires additional verification. To bridge this gap, we introduce the first comprehensive benchmark designed to evaluate the robustness of collaborative perception methods in the presence of natural corruptions typical of real-world environments. Furthermore, we propose DSRC, a robustness-enhanced collaborative perception method aiming to learn Density-insensitive and Semantic-aware collaborative Representation against Corruptions. DSRC consists of two key designs: i) a semantic-guided sparse-to-dense distillation framework, which constructs multi-view dense objects painted by ground truth bounding boxes to effectively learn density-insensitive and semantic-aware collaborative representation; ii) a feature-to-point cloud reconstruction approach to better fuse critical collaborative representation across agents. To thoroughly evaluate DSRC, we conduct extensive experiments on real-world and simulated datasets. The results demonstrate that our method outperforms SOTA collaborative perception methods in both clean and corrupted conditions. Code is available at https://github.com/Terry9a/DSRC.
MindScope: Exploring cognitive biases in large language models through Multi-Agent Systems
Oct 06, 2024



Detecting cognitive biases in large language models (LLMs) is a fascinating task that aims to probe the existing cognitive biases within these models. Current methods for detecting cognitive biases in language models generally suffer from incomplete detection capabilities and a restricted range of detectable bias types. To address this issue, we introduced the 'MindScope' dataset, which distinctively integrates static and dynamic elements. The static component comprises 5,170 open-ended questions spanning 72 cognitive bias categories. The dynamic component leverages a rule-based, multi-agent communication framework to facilitate the generation of multi-round dialogues. This framework is flexible and readily adaptable for various psychological experiments involving LLMs. In addition, we introduce a multi-agent detection method applicable to a wide range of detection tasks, which integrates Retrieval-Augmented Generation (RAG), competitive debate, and a reinforcement learning-based decision module. Demonstrating substantial effectiveness, this method has shown to improve detection accuracy by as much as 35.10% compared to GPT-4. Codes and appendix are available at https://github.com/2279072142/MindScope.
Feature Selection Based on Orthogonal Constraints and Polygon Area
Feb 25, 2024The goal of feature selection is to choose the optimal subset of features for a recognition task by evaluating the importance of each feature, thereby achieving effective dimensionality reduction. Currently, proposed feature selection methods often overlook the discriminative dependencies between features and labels. To address this problem, this paper introduces a novel orthogonal regression model incorporating the area of a polygon. The model can intuitively capture the discriminative dependencies between features and labels. Additionally, this paper employs a hybrid non-monotone linear search method to efficiently tackle the non-convex optimization challenge posed by orthogonal constraints. Experimental results demonstrate that our approach not only effectively captures discriminative dependency information but also surpasses traditional methods in reducing feature dimensions and enhancing classification performance.
EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education
Aug 05, 2023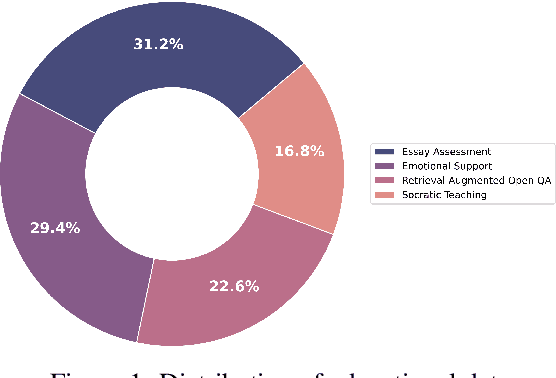



EduChat (https://www.educhat.top/) is a large-scale language model (LLM)-based chatbot system in the education domain. Its goal is to support personalized, fair, and compassionate intelligent education, serving teachers, students, and parents. Guided by theories from psychology and education, it further strengthens educational functions such as open question answering, essay assessment, Socratic teaching, and emotional support based on the existing basic LLMs. Particularly, we learn domain-specific knowledge by pre-training on the educational corpus and stimulate various skills with tool use by fine-tuning on designed system prompts and instructions. Currently, EduChat is available online as an open-source project, with its code, data, and model parameters available on platforms (e.g., GitHub https://github.com/icalk-nlp/EduChat, Hugging Face https://huggingface.co/ecnu-icalk ). We also prepare a demonstration of its capabilities online (https://vimeo.com/851004454). This initiative aims to promote research and applications of LLMs for intelligent education.