 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Step: Faster and Better Alignment for Flow Matching Models via Step-aware Advantages
Feb 02, 2026Recent advances in flow matching models, particularly with reinforcement learning (RL), have significantly enhanced human preference alignment in few step text to image generators. However, existing RL based approaches for flow matching models typically rely on numerous denoising steps, while suffering from sparse and imprecise reward signals that often lead to suboptimal alignment. To address these limitations, we propose Temperature Annealed Few step Sampling with Group Relative Policy Optimization (TAFS GRPO), a novel framework for training flow matching text to image models into efficient few step generators well aligned with human preferences. Our method iteratively injects adaptive temporal noise onto the results of one step samples. By repeatedly annealing the model's sampled outputs, it introduces stochasticity into the sampling process while preserving the semantic integrity of each generated image. Moreover, its step aware advantage integration mechanism combines the GRPO to avoid the need for the differentiable of reward function and provide dense and step specific rewards for stable policy optimization. Extensive experiments demonstrate that TAFS GRPO achieves strong performance in few step text to image generation and significantly improves the alignment of generated images with human preferences. The code and models of this work will be available to facilitate further research.
SAS-Bench: A Fine-Grained Benchmark for Evaluating Short Answer Scoring with Large Language Models
May 15, 2025Subjective Answer Grading (SAG) plays a crucial role in education, standardized testing, and automated assessment systems, particularly for evaluating short-form responses in Short Answer Scoring (SAS). However, existing approaches often produce coarse-grained scores and lack detailed reasoning. Although large language models (LLMs) have demonstrated potential as zero-shot evaluators, they remain susceptible to bias, inconsistencies with human judgment, and limited transparency in scoring decisions. To overcome these limitations, we introduce SAS-Bench, a benchmark specifically designed for LLM-based SAS tasks. SAS-Bench provides fine-grained, step-wise scoring, expert-annotated error categories, and a diverse range of question types derived from real-world subject-specific exams. This benchmark facilitates detailed evaluation of model reasoning processes and explainability. We also release an open-source dataset containing 1,030 questions and 4,109 student responses, each annotated by domain experts. Furthermore, we conduct comprehensive experiments with various LLMs, identifying major challenges in scoring science-related questions and highlighting the effectiveness of few-shot prompting in improving scoring accuracy. Our work offers valuable insights into the development of more robust, fair, and educationally meaningful LLM-based evaluation systems.
Improving Low-Resource Sequence Labeling with Knowledge Fusion and Contextual Label Explanations
Jan 31, 2025



Sequence labeling remains a significant challenge in low-resource, domain-specific scenarios, particularly for character-dense languages like Chinese. Existing methods primarily focus on enhancing model comprehension and improving data diversity to boost performance. However, these approaches still struggle with inadequate model applicability and semantic distribution biases in domain-specific contexts. To overcome these limitations, we propose a novel framework that combines an LLM-based knowledge enhancement workflow with a span-based Knowledge Fusion for Rich and Efficient Extraction (KnowFREE) model. Our workflow employs explanation prompts to generate precise contextual interpretations of target entities, effectively mitigating semantic biases and enriching the model's contextual understanding. The KnowFREE model further integrates extension label features, enabling efficient nested entity extraction without relying on external knowledge during inference. Experiments on multiple Chinese domain-specific sequence labeling datasets demonstrate that our approach achieves state-of-the-art performance, effectively addressing the challenges posed by low-resource settings.
Sharpness-Aware Black-Box Optimization
Oct 16, 2024
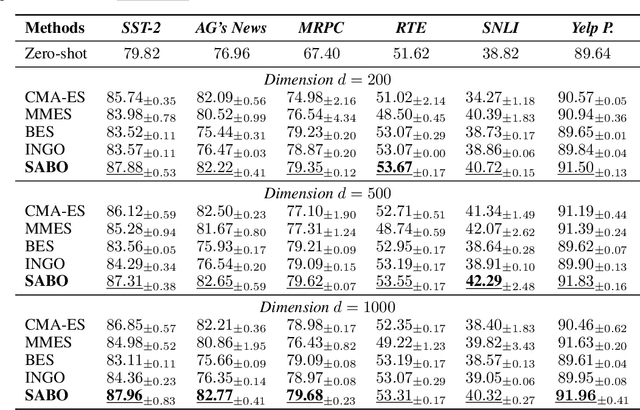


Black-box optimization algorithms have been widely used in various machine learning problems, including reinforcement learning and prompt fine-tuning. However, directly optimizing the training loss value, as commonly done in existing black-box optimization methods, could lead to suboptimal model quality and generalization performance. To address those problems in black-box optimization, we propose a novel Sharpness-Aware Black-box Optimization (SABO) algorithm, which applies a sharpness-aware minimization strategy to improve the model generalization. Specifically, the proposed SABO method first reparameterizes the objective function by its expectation over a Gaussian distribution. Then it iteratively updates the parameterized distribution by approximated stochastic gradients of the maximum objective value within a small neighborhood around the current solution in the Gaussian distribution space. Theoretically, we prove the convergence rate and generalization bound of the proposed SABO algorithm. Empirically, extensive experiments on the black-box prompt fine-tuning tasks demonstrate the effectiveness of the proposed SABO method in improving model generalization performance.
Task-Aware Low-Rank Adaptation of Segment Anything Model
Mar 16, 2024The Segment Anything Model (SAM), with its remarkable zero-shot capability, has been proven to be a powerful foundation model for image segmentation tasks, which is an important task in computer vision. However, the transfer of its rich semantic information to multiple different downstream tasks remains unexplored. In this paper, we propose the Task-Aware Low-Rank Adaptation (TA-LoRA) method, which enables SAM to work as a foundation model for multi-task learning. Specifically, TA-LoRA injects an update parameter tensor into each layer of the encoder in SAM and leverages a low-rank tensor decomposition method to incorporate both task-shared and task-specific information. Furthermore, we introduce modified SAM (mSAM) for multi-task learning where we remove the prompt encoder of SAM and use task-specific no mask embeddings and mask decoder for each task. Extensive experiments conducted on benchmark datasets substantiate the efficacy of TA-LoRA in enhancing the performance of mSAM across multiple downstream tasks.
A First-Order Multi-Gradient Algorithm for Multi-Objective Bi-Level Optimization
Jan 17, 2024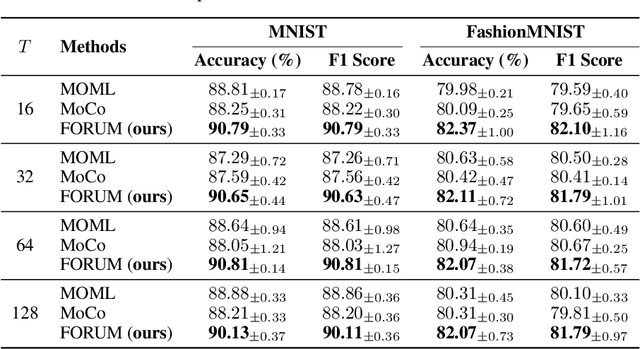



In this paper, we study the Multi-Objective Bi-Level Optimization (MOBLO) problem, where the upper-level subproblem is a multi-objective optimization problem and the lower-level subproblem is for scalar optimization. Existing gradient-based MOBLO algorithms need to compute the Hessian matrix, causing the computational inefficient problem. To address this, we propose an efficient first-order multi-gradient method for MOBLO, called FORUM. Specifically, we reformulate MOBLO problems as a constrained multi-objective optimization (MOO) problem via the value-function approach. Then we propose a novel multi-gradient aggregation method to solve the challenging constrained MOO problem. Theoretically, we provide the complexity analysis to show the efficiency of the proposed method and a non-asymptotic convergence result. Empirically, extensive experiments demonstrate the effectiveness and efficiency of the proposed FORUM method in different learning problems. In particular, it achieves state-of-the-art performance on three multi-task learning benchmark datasets.
A Unified Framework for Unsupervised Domain Adaptation based on Instance Weighting
Dec 08, 2023
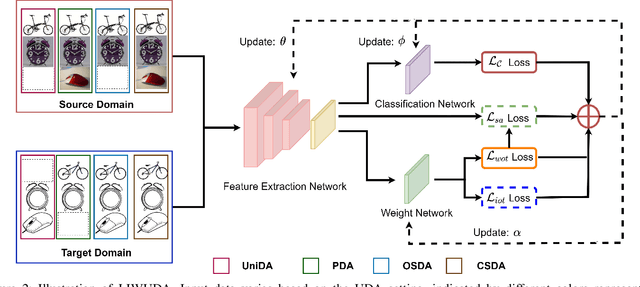
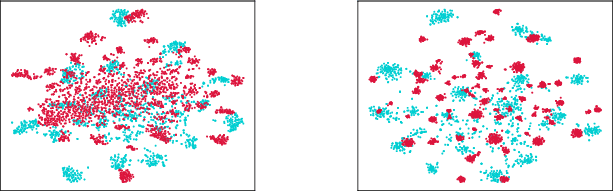
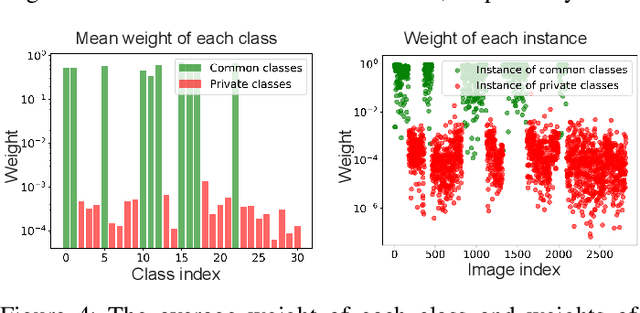
Despite the progress made in domain adaptation, solving Unsupervised Domain Adaptation (UDA) problems with a general method under complex conditions caused by label shifts between domains remains a formidable task. In this work, we comprehensively investigate four distinct UDA settings including closed set domain adaptation, partial domain adaptation, open set domain adaptation, and universal domain adaptation, where shared common classes between source and target domains coexist alongside domain-specific private classes. The prominent challenges inherent in diverse UDA settings center around the discrimination of common/private classes and the precise measurement of domain discrepancy. To surmount these challenges effectively, we propose a novel yet effective method called Learning Instance Weighting for Unsupervised Domain Adaptation (LIWUDA), which caters to various UDA settings. Specifically, the proposed LIWUDA method constructs a weight network to assign weights to each instance based on its probability of belonging to common classes, and designs Weighted Optimal Transport (WOT) for domain alignment by leveraging instance weights. Additionally, the proposed LIWUDA method devises a Separate and Align (SA) loss to separate instances with low similarities and align instances with high similarities. To guide the learning of the weight network, Intra-domain Optimal Transport (IOT) is proposed to enforce the weights of instances in common classes to follow a uniform distribution. Through the integration of those three components, the proposed LIWUDA method demonstrates its capability to address all four UDA settings in a unified manner. Experimental evaluations conducted on three benchmark datasets substantiate the effectiveness of the proposed LIWUDA method.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023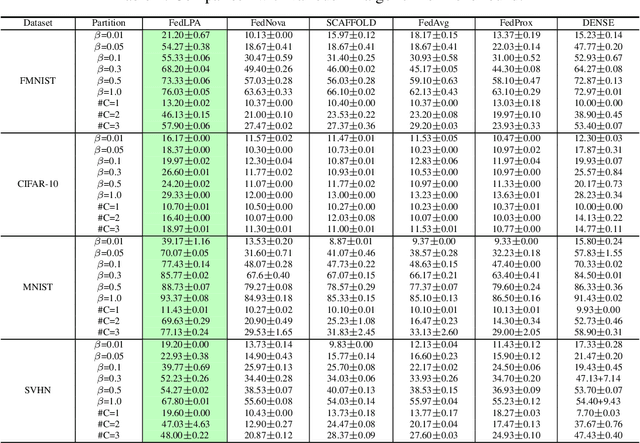
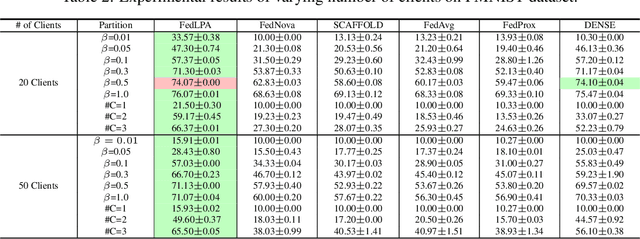
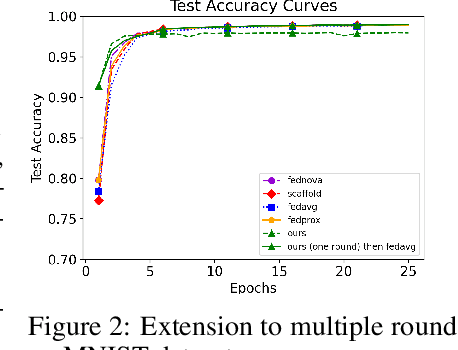
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
A Scale-Invariant Task Balancing Approach for Multi-Task Learning
Aug 23, 2023Multi-task learning (MTL), a learning paradigm to learn multiple related tasks simultaneously, has achieved great success in various fields. However, task-balancing remains a significant challenge in MTL, with the disparity in loss/gradient scales often leading to performance compromises. In this paper, we propose a Scale-Invariant Multi-Task Learning (SI-MTL) method to alleviate the task-balancing problem from both loss and gradient perspectives. Specifically, SI-MTL contains a logarithm transformation which is performed on all task losses to ensure scale-invariant at the loss level, and a gradient balancing method, SI-G, which normalizes all task gradients to the same magnitude as the maximum gradient norm. Extensive experiments conducted on several benchmark datasets consistently demonstrate the effectiveness of SI-G and the state-of-the-art performance of SI-MTL.
A Fast Attention Network for Joint Intent Detection and Slot Filling on Edge Devices
May 16, 2022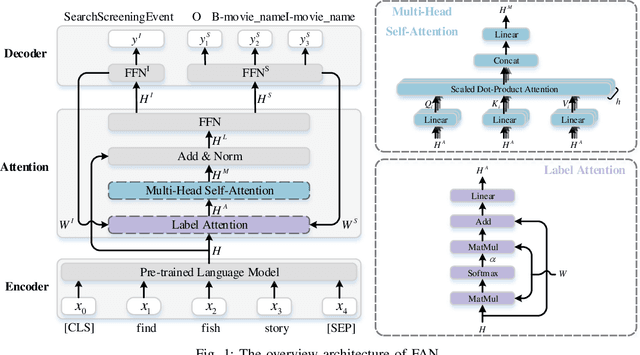



Intent detection and slot filling are two main tasks in natural language understanding and play an essential role in task-oriented dialogue systems. The joint learning of both tasks can improve inference accuracy and is popular in recent works. However, most joint models ignore the inference latency and cannot meet the need to deploy dialogue systems at the edge. In this paper, we propose a Fast Attention Network (FAN) for joint intent detection and slot filling tasks, guaranteeing both accuracy and latency. Specifically, we introduce a clean and parameter-refined attention module to enhance the information exchange between intent and slot, improving semantic accuracy by more than 2%. FAN can be implemented on different encoders and delivers more accurate models at every speed level. Our experiments on the Jetson Nano platform show that FAN inferences fifteen utterances per second with a small accuracy drop, showing its effectiveness and efficiency on edge devices.