 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Matrix-form Equations and Implementation of Multilayer Perceptrons
Nov 14, 2025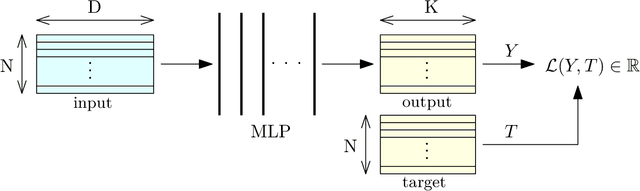

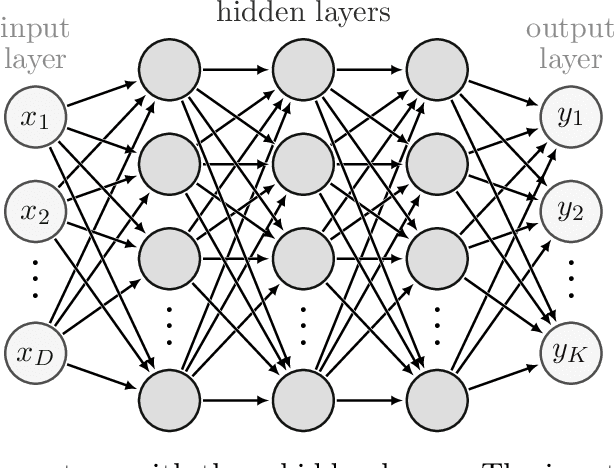
Multilayer perceptrons (MLPs) remain fundamental to modern deep learning, yet their algorithmic details are rarely presented in complete, explicit \emph{batch matrix-form}. Rather, most references express gradients per sample or rely on automatic differentiation. Although automatic differentiation can achieve equally high computational efficiency, the usage of batch matrix-form makes the computational structure explicit, which is essential for transparent, systematic analysis, and optimization in settings such as sparse neural networks. This paper fills that gap by providing a mathematically rigorous and implementation-ready specification of MLPs in batch matrix-form. We derive forward and backward equations for all standard and advanced layers, including batch normalization and softmax, and validate all equations using the symbolic mathematics library SymPy. From these specifications, we construct uniform reference implementations in NumPy, PyTorch, JAX, TensorFlow, and a high-performance C++ backend optimized for sparse operations. Our main contributions are: (1) a complete derivation of batch matrix-form backpropagation for MLPs, (2) symbolic validation of all gradient equations, (3) uniform Python and C++ reference implementations grounded in a small set of matrix primitives, and (4) demonstration of how explicit formulations enable efficient sparse computation. Together, these results establish a validated, extensible foundation for understanding, teaching, and researching neural network algorithms.
Leave it to the Specialist: Repair Sparse LLMs with Sparse Fine-Tuning via Sparsity Evolution
May 29, 2025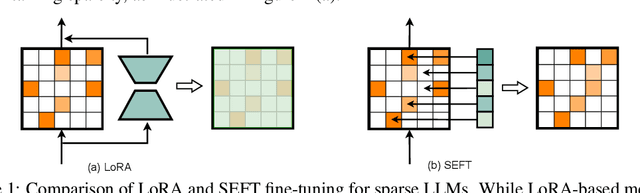
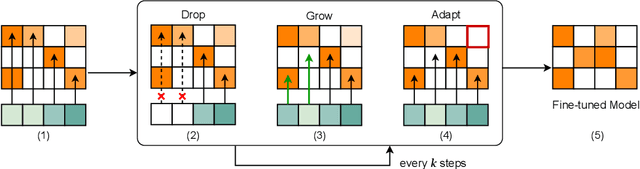
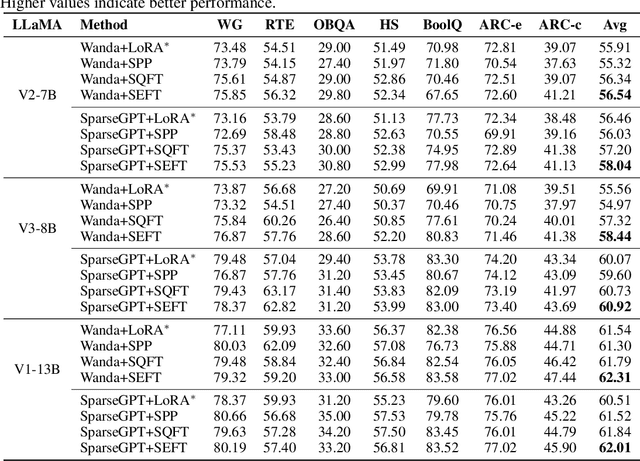
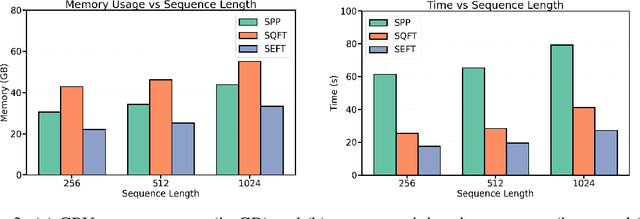
Large language models (LLMs) have achieved remarkable success across various tasks but face deployment challenges due to their massive computational demands. While post-training pruning methods like SparseGPT and Wanda can effectively reduce the model size, but struggle to maintain model performance at high sparsity levels, limiting their utility for downstream tasks. Existing fine-tuning methods, such as full fine-tuning and LoRA, fail to preserve sparsity as they require updating the whole dense metrics, not well-suited for sparse LLMs. In this paper, we propose Sparsity Evolution Fine-Tuning (SEFT), a novel method designed specifically for sparse LLMs. SEFT dynamically evolves the sparse topology of pruned models during fine-tuning, while preserving the overall sparsity throughout the process. The strengths of SEFT lie in its ability to perform task-specific adaptation through a weight drop-and-grow strategy, enabling the pruned model to self-adapt its sparse connectivity pattern based on the target dataset. Furthermore, a sensitivity-driven pruning criterion is employed to ensure that the desired sparsity level is consistently maintained throughout fine-tuning. Our experiments on various LLMs, including LLaMA families, DeepSeek, and Mistral, across a diverse set of benchmarks demonstrate that SEFT achieves stronger performance while offering superior memory and time efficiency compared to existing baselines. Our code is publicly available at: https://github.com/QiaoXiao7282/SEFT.
NeuroTrails: Training with Dynamic Sparse Heads as the Key to Effective Ensembling
May 23, 2025Model ensembles have long been a cornerstone for improving generalization and robustness in deep learning. However, their effectiveness often comes at the cost of substantial computational overhead. To address this issue, state-of-the-art methods aim to replicate ensemble-class performance without requiring multiple independently trained networks. Unfortunately, these algorithms often still demand considerable compute at inference. In response to these limitations, we introduce $\textbf{NeuroTrails}$, a sparse multi-head architecture with dynamically evolving topology. This unexplored model-agnostic training paradigm improves ensemble performance while reducing the required resources. We analyze the underlying reason for its effectiveness and observe that the various neural trails induced by dynamic sparsity attain a $\textit{Goldilocks zone}$ of prediction diversity. NeuroTrails displays efficacy with convolutional and transformer-based architectures on computer vision and language tasks. Experiments on ResNet-50/ImageNet, LLaMA-350M/C4, among many others, demonstrate increased accuracy and stronger robustness in zero-shot generalization, while requiring significantly fewer parameters.
Dynamic Sparse Training versus Dense Training: The Unexpected Winner in Image Corruption Robustness
Oct 03, 2024
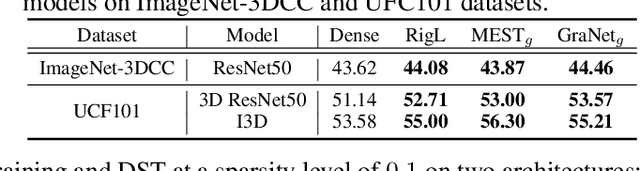
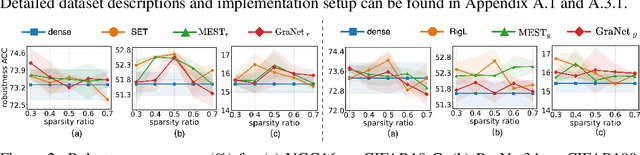

It is generally perceived that Dynamic Sparse Training opens the door to a new era of scalability and efficiency for artificial neural networks at, perhaps, some costs in accuracy performance for the classification task. At the same time, Dense Training is widely accepted as being the "de facto" approach to train artificial neural networks if one would like to maximize their robustness against image corruption. In this paper, we question this general practice. Consequently, we claim that, contrary to what is commonly thought, the Dynamic Sparse Training methods can consistently outperform Dense Training in terms of robustness accuracy, particularly if the efficiency aspect is not considered as a main objective (i.e., sparsity levels between 10% and up to 50%), without adding (or even reducing) resource cost. We validate our claim on two types of data, images and videos, using several traditional and modern deep learning architectures for computer vision and three widely studied Dynamic Sparse Training algorithms. Our findings reveal a new yet-unknown benefit of Dynamic Sparse Training and open new possibilities in improving deep learning robustness beyond the current state of the art.
Are Sparse Neural Networks Better Hard Sample Learners?
Sep 13, 2024



While deep learning has demonstrated impressive progress, it remains a daunting challenge to learn from hard samples as these samples are usually noisy and intricate. These hard samples play a crucial role in the optimal performance of deep neural networks. Most research on Sparse Neural Networks (SNNs) has focused on standard training data, leaving gaps in understanding their effectiveness on complex and challenging data. This paper's extensive investigation across scenarios reveals that most SNNs trained on challenging samples can often match or surpass dense models in accuracy at certain sparsity levels, especially with limited data. We observe that layer-wise density ratios tend to play an important role in SNN performance, particularly for methods that train from scratch without pre-trained initialization. These insights enhance our understanding of SNNs' behavior and potential for efficient learning approaches in data-centric AI. Our code is publicly available at: \url{https://github.com/QiaoXiao7282/hard_sample_learners}.
Nerva: a Truly Sparse Implementation of Neural Networks
Jul 24, 2024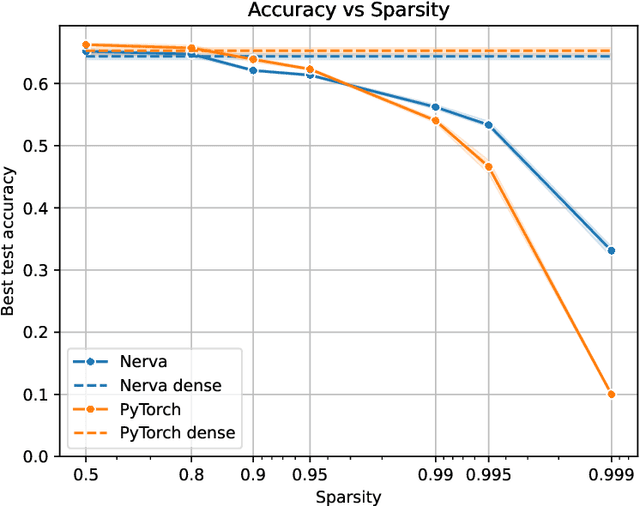

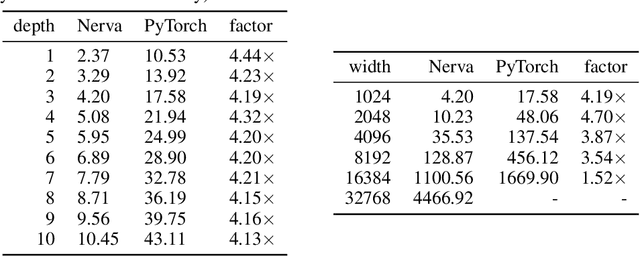

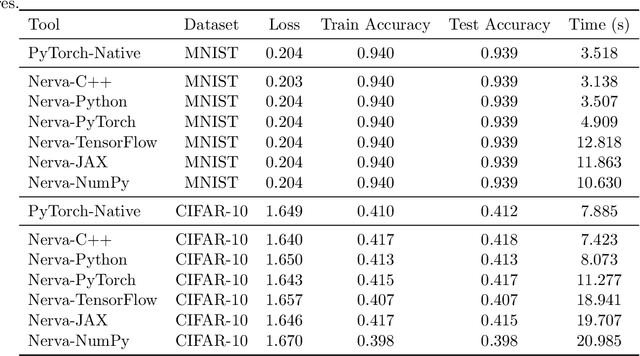
We introduce Nerva, a fast neural network library under development in C++. It supports sparsity by using the sparse matrix operations of Intel's Math Kernel Library (MKL), which eliminates the need for binary masks. We show that Nerva significantly decreases training time and memory usage while reaching equivalent accuracy to PyTorch. We run static sparse experiments with an MLP on CIFAR-10. On high sparsity levels like $99\%$, the runtime is reduced by a factor of $4\times$ compared to a PyTorch model using masks. Similar to other popular frameworks such as PyTorch and Keras, Nerva offers a Python interface for users to work with.
Dynamic Data Pruning for Automatic Speech Recognition
Jun 26, 2024
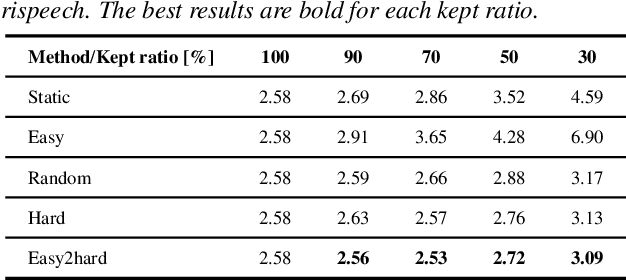
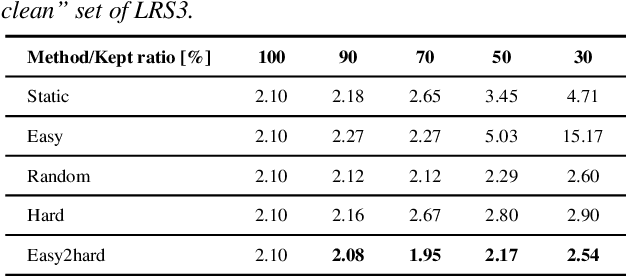
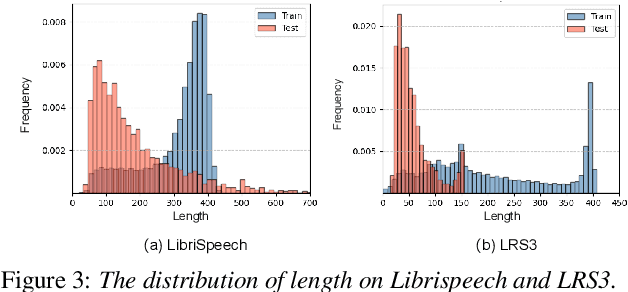
The recent success of Automatic Speech Recognition (ASR) is largely attributed to the ever-growing amount of training data. However, this trend has made model training prohibitively costly and imposed computational demands. While data pruning has been proposed to mitigate this issue by identifying a small subset of relevant data, its application in ASR has been barely explored, and existing works often entail significant overhead to achieve meaningful results. To fill this gap, this paper presents the first investigation of dynamic data pruning for ASR, finding that we can reach the full-data performance by dynamically selecting 70% of data. Furthermore, we introduce Dynamic Data Pruning for ASR (DDP-ASR), which offers several fine-grained pruning granularities specifically tailored for speech-related datasets, going beyond the conventional pruning of entire time sequences. Our intensive experiments show that DDP-ASR can save up to 1.6x training time with negligible performance loss.
MSRS: Training Multimodal Speech Recognition Models from Scratch with Sparse Mask Optimization
Jun 25, 2024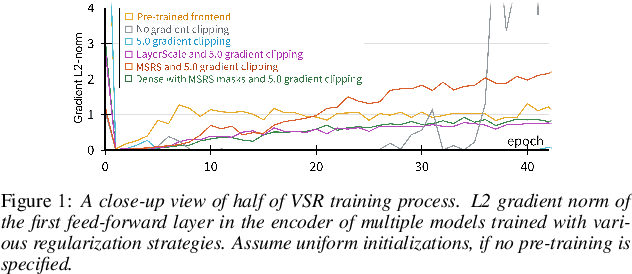
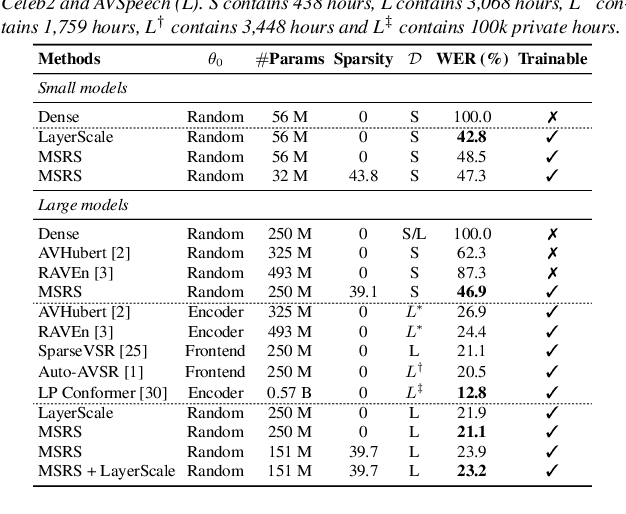
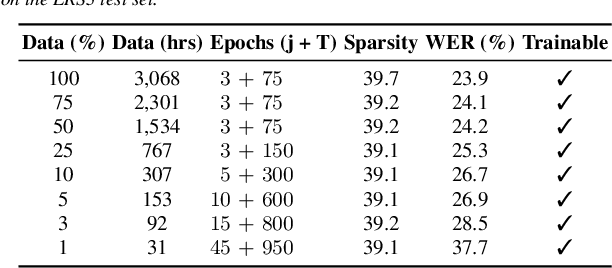
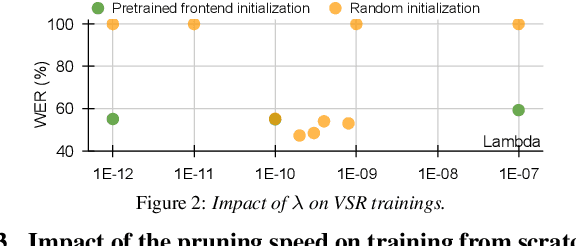
Pre-trained models have been a foundational approach in speech recognition, albeit with associated additional costs. In this study, we propose a regularization technique that facilitates the training of visual and audio-visual speech recognition models (VSR and AVSR) from scratch. This approach, abbreviated as \textbf{MSRS} (Multimodal Speech Recognition from Scratch), introduces a sparse regularization that rapidly learns sparse structures within the dense model at the very beginning of training, which receives healthier gradient flow than the dense equivalent. Once the sparse mask stabilizes, our method allows transitioning to a dense model or keeping a sparse model by updating non-zero values. MSRS achieves competitive results in VSR and AVSR with 21.1% and 0.9% WER on the LRS3 benchmark, while reducing training time by at least 2x. We explore other sparse approaches and show that only MSRS enables training from scratch by implicitly masking the weights affected by vanishing gradients.
A Unified Framework for Unsupervised Domain Adaptation based on Instance Weighting
Dec 08, 2023
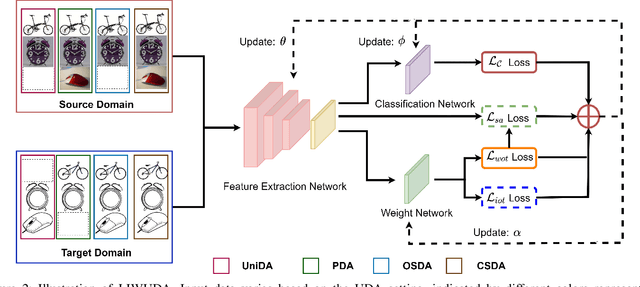
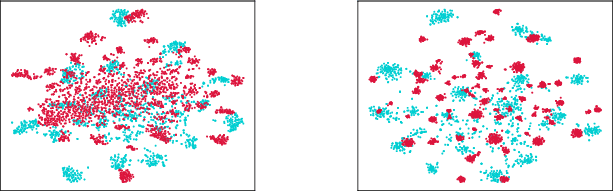
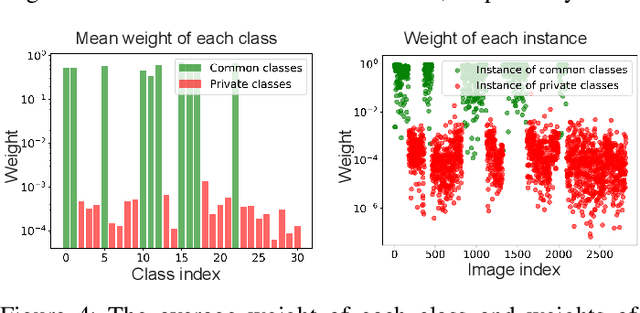
Despite the progress made in domain adaptation, solving Unsupervised Domain Adaptation (UDA) problems with a general method under complex conditions caused by label shifts between domains remains a formidable task. In this work, we comprehensively investigate four distinct UDA settings including closed set domain adaptation, partial domain adaptation, open set domain adaptation, and universal domain adaptation, where shared common classes between source and target domains coexist alongside domain-specific private classes. The prominent challenges inherent in diverse UDA settings center around the discrimination of common/private classes and the precise measurement of domain discrepancy. To surmount these challenges effectively, we propose a novel yet effective method called Learning Instance Weighting for Unsupervised Domain Adaptation (LIWUDA), which caters to various UDA settings. Specifically, the proposed LIWUDA method constructs a weight network to assign weights to each instance based on its probability of belonging to common classes, and designs Weighted Optimal Transport (WOT) for domain alignment by leveraging instance weights. Additionally, the proposed LIWUDA method devises a Separate and Align (SA) loss to separate instances with low similarities and align instances with high similarities. To guide the learning of the weight network, Intra-domain Optimal Transport (IOT) is proposed to enforce the weights of instances in common classes to follow a uniform distribution. Through the integration of those three components, the proposed LIWUDA method demonstrates its capability to address all four UDA settings in a unified manner. Experimental evaluations conducted on three benchmark datasets substantiate the effectiveness of the proposed LIWUDA method.
E2ENet: Dynamic Sparse Feature Fusion for Accurate and Efficient 3D Medical Image Segmentation
Dec 07, 2023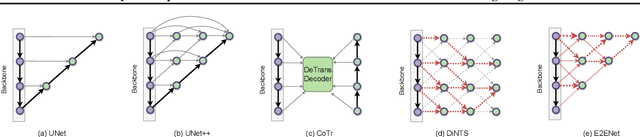
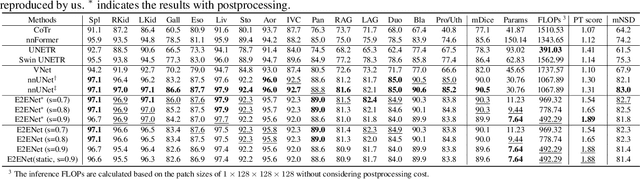
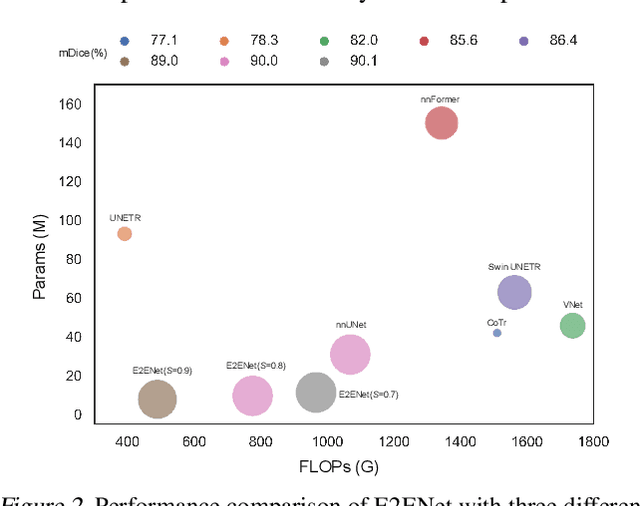
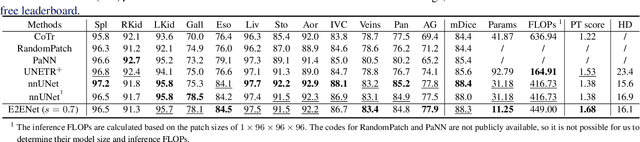
Deep neural networks have evolved as the leading approach in 3D medical image segmentation due to their outstanding performance. However, the ever-increasing model size and computation cost of deep neural networks have become the primary barrier to deploying them on real-world resource-limited hardware. In pursuit of improving performance and efficiency, we propose a 3D medical image segmentation model, named Efficient to Efficient Network (E2ENet), incorporating two parametrically and computationally efficient designs. i. Dynamic sparse feature fusion (DSFF) mechanism: it adaptively learns to fuse informative multi-scale features while reducing redundancy. ii. Restricted depth-shift in 3D convolution: it leverages the 3D spatial information while keeping the model and computational complexity as 2D-based methods. We conduct extensive experiments on BTCV, AMOS-CT and Brain Tumor Segmentation Challenge, demonstrating that E2ENet consistently achieves a superior trade-off between accuracy and efficiency than prior arts across various resource constraints. E2ENet achieves comparable accuracy on the large-scale challenge AMOS-CT, while saving over 68\% parameter count and 29\% FLOPs in the inference phase, compared with the previous best-performing method. Our code has been made available at: https://github.com/boqian333/E2ENet-Medical.