 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroTrails: Training with Dynamic Sparse Heads as the Key to Effective Ensembling
May 23, 2025Model ensembles have long been a cornerstone for improving generalization and robustness in deep learning. However, their effectiveness often comes at the cost of substantial computational overhead. To address this issue, state-of-the-art methods aim to replicate ensemble-class performance without requiring multiple independently trained networks. Unfortunately, these algorithms often still demand considerable compute at inference. In response to these limitations, we introduce $\textbf{NeuroTrails}$, a sparse multi-head architecture with dynamically evolving topology. This unexplored model-agnostic training paradigm improves ensemble performance while reducing the required resources. We analyze the underlying reason for its effectiveness and observe that the various neural trails induced by dynamic sparsity attain a $\textit{Goldilocks zone}$ of prediction diversity. NeuroTrails displays efficacy with convolutional and transformer-based architectures on computer vision and language tasks. Experiments on ResNet-50/ImageNet, LLaMA-350M/C4, among many others, demonstrate increased accuracy and stronger robustness in zero-shot generalization, while requiring significantly fewer parameters.
Unveiling the Power of Sparse Neural Networks for Feature Selection
Aug 08, 2024



Sparse Neural Networks (SNNs) have emerged as powerful tools for efficient feature selection. Leveraging the dynamic sparse training (DST) algorithms within SNNs has demonstrated promising feature selection capabilities while drastically reducing computational overheads. Despite these advancements, several critical aspects remain insufficiently explored for feature selection. Questions persist regarding the choice of the DST algorithm for network training, the choice of metric for ranking features/neurons, and the comparative performance of these methods across diverse datasets when compared to dense networks. This paper addresses these gaps by presenting a comprehensive systematic analysis of feature selection with sparse neural networks. Moreover, we introduce a novel metric considering sparse neural network characteristics, which is designed to quantify feature importance within the context of SNNs. Our findings show that feature selection with SNNs trained with DST algorithms can achieve, on average, more than $50\%$ memory and $55\%$ FLOPs reduction compared to the dense networks, while outperforming them in terms of the quality of the selected features. Our code and the supplementary material are available on GitHub (\url{https://github.com/zahraatashgahi/Neuron-Attribution}).
Adaptive Sparsity Level during Training for Efficient Time Series Forecasting with Transformers
May 28, 2023Efficient time series forecasting has become critical for real-world applications, particularly with deep neural networks (DNNs). Efficiency in DNNs can be achieved through sparse connectivity and reducing the model size. However, finding the sparsity level automatically during training remains a challenging task due to the heterogeneity in the loss-sparsity tradeoffs across the datasets. In this paper, we propose \enquote{\textbf{P}runing with \textbf{A}daptive \textbf{S}parsity \textbf{L}evel} (\textbf{PALS}), to automatically seek an optimal balance between loss and sparsity, all without the need for a predefined sparsity level. PALS draws inspiration from both sparse training and during-training methods. It introduces the novel "expand" mechanism in training sparse neural networks, allowing the model to dynamically shrink, expand, or remain stable to find a proper sparsity level. In this paper, we focus on achieving efficiency in transformers known for their excellent time series forecasting performance but high computational cost. Nevertheless, PALS can be applied directly to any DNN. In the scope of these arguments, we demonstrate its effectiveness also on the DLinear model. Experimental results on six benchmark datasets and five state-of-the-art transformer variants show that PALS substantially reduces model size while maintaining comparable performance to the dense model. More interestingly, PALS even outperforms the dense model, in 12 and 14 cases out of 30 cases in terms of MSE and MAE loss, respectively, while reducing 65% parameter count and 63% FLOPs on average. Our code will be publicly available upon acceptance of the paper.
Supervised Feature Selection with Neuron Evolution in Sparse Neural Networks
Mar 14, 2023



Feature selection that selects an informative subset of variables from data not only enhances the model interpretability and performance but also alleviates the resource demands. Recently, there has been growing attention on feature selection using neural networks. However, existing methods usually suffer from high computational costs when applied to high-dimensional datasets. In this paper, inspired by evolution processes, we propose a novel resource-efficient supervised feature selection method using sparse neural networks, named \enquote{NeuroFS}. By gradually pruning the uninformative features from the input layer of a sparse neural network trained from scratch, NeuroFS derives an informative subset of features efficiently. By performing several experiments on $11$ low and high-dimensional real-world benchmarks of different types, we demonstrate that NeuroFS achieves the highest ranking-based score among the considered state-of-the-art supervised feature selection models. The code is available on GitHub.
Where to Pay Attention in Sparse Training for Feature Selection?
Nov 26, 2022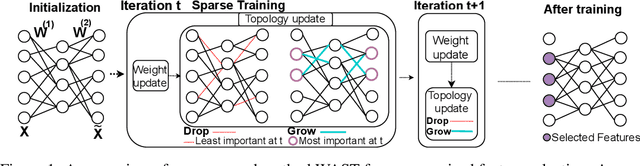
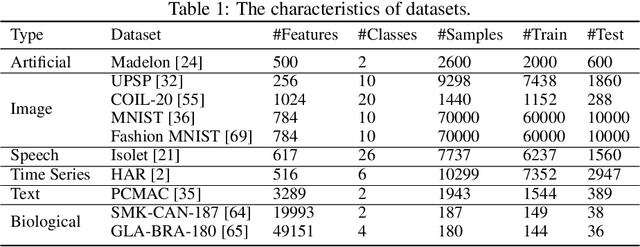
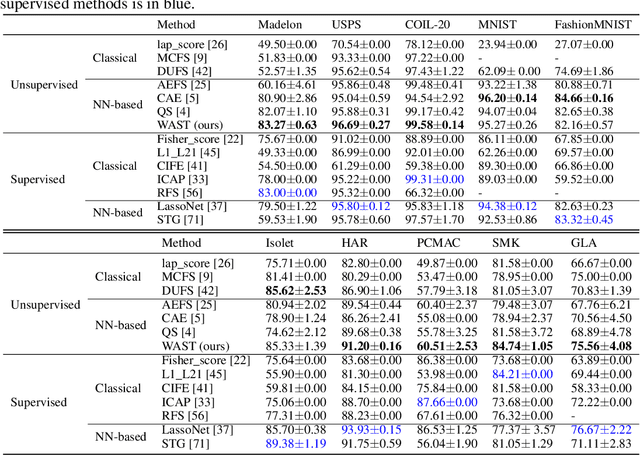
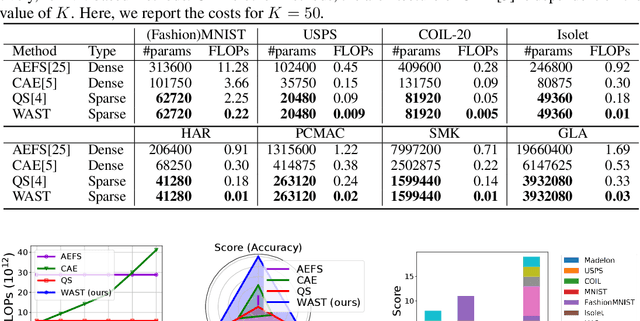
A new line of research for feature selection based on neural networks has recently emerged. Despite its superiority to classical methods, it requires many training iterations to converge and detect informative features. The computational time becomes prohibitively long for datasets with a large number of samples or a very high dimensional feature space. In this paper, we present a new efficient unsupervised method for feature selection based on sparse autoencoders. In particular, we propose a new sparse training algorithm that optimizes a model's sparse topology during training to pay attention to informative features quickly. The attention-based adaptation of the sparse topology enables fast detection of informative features after a few training iterations. We performed extensive experiments on 10 datasets of different types, including image, speech, text, artificial, and biological. They cover a wide range of characteristics, such as low and high-dimensional feature spaces, and few and large training samples. Our proposed approach outperforms the state-of-the-art methods in terms of selecting informative features while reducing training iterations and computational costs substantially. Moreover, the experiments show the robustness of our method in extremely noisy environments.
Memory-free Online Change-point Detection: A Novel Neural Network Approach
Jul 08, 2022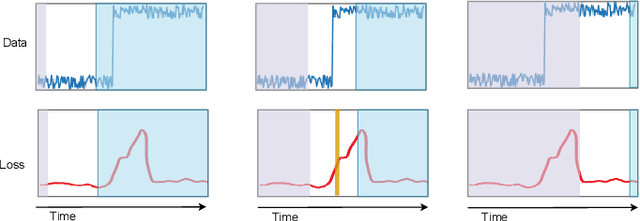
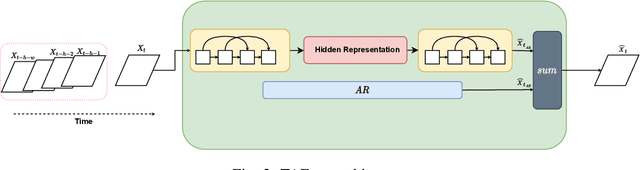
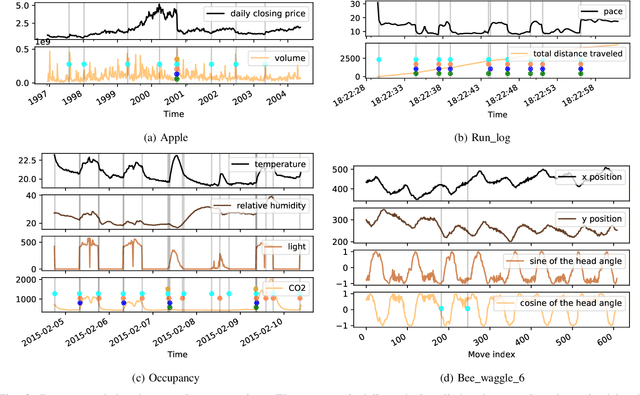
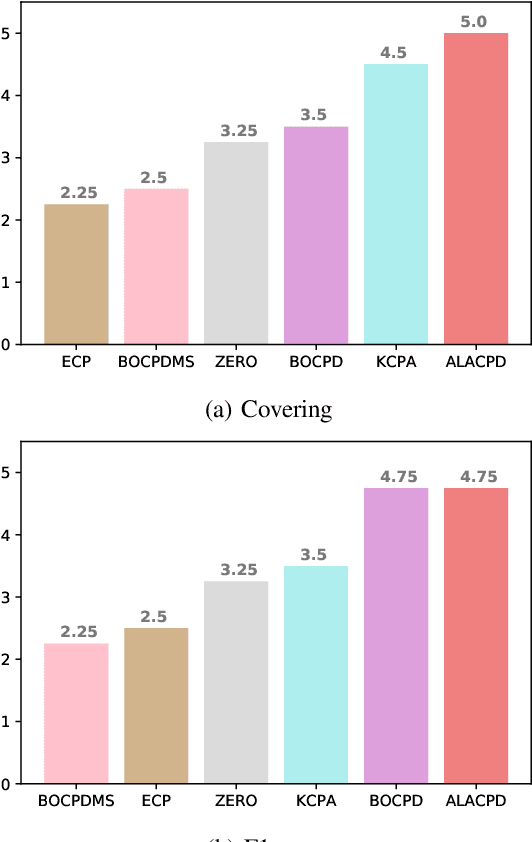
Change-point detection (CPD), which detects abrupt changes in the data distribution, is recognized as one of the most significant tasks in time series analysis. Despite the extensive literature on offline CPD, unsupervised online CPD still suffers from major challenges, including scalability, hyperparameter tuning, and learning constraints. To mitigate some of these challenges, in this paper, we propose a novel deep learning approach for unsupervised online CPD from multi-dimensional time series, named Adaptive LSTM-Autoencoder Change-Point Detection (ALACPD). ALACPD exploits an LSTM-autoencoder-based neural network to perform unsupervised online CPD. It continuously adapts to the incoming samples without keeping the previously received input, thus being memory-free. We perform an extensive evaluation on several real-world time series CPD benchmarks. We show that ALACPD, on average, ranks first among state-of-the-art CPD algorithms in terms of quality of the time series segmentation, and it is on par with the best performer in terms of the accuracy of the estimated change-points. The implementation of ALACPD is available online on Github\footnote{\url{https://github.com/zahraatashgahi/ALACPD}}.
FreeTickets: Accurate, Robust and Efficient Deep Ensemble by Training with Dynamic Sparsity
Jun 28, 2021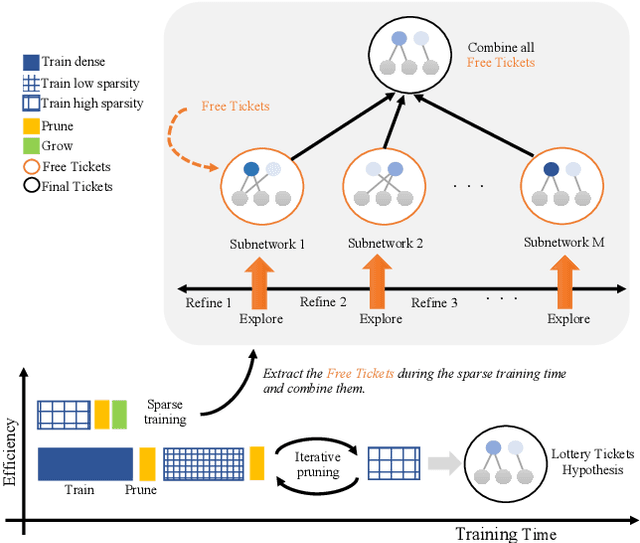
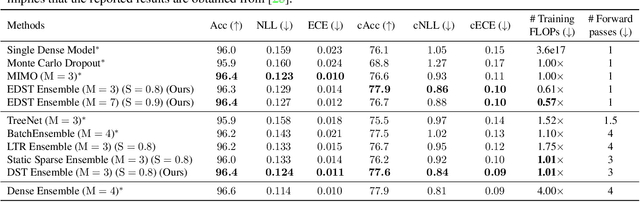
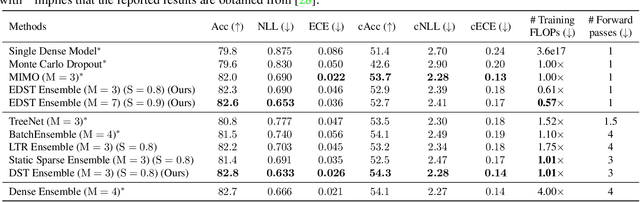
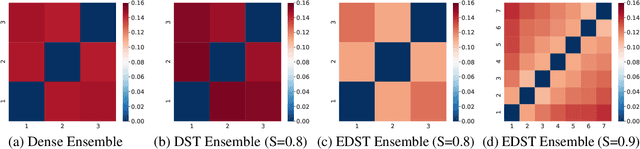
Recent works on sparse neural networks have demonstrated that it is possible to train a sparse network in isolation to match the performance of the corresponding dense networks with a fraction of parameters. However, the identification of these performant sparse neural networks (winning tickets) either involves a costly iterative train-prune-retrain process (e.g., Lottery Ticket Hypothesis) or an over-extended sparse training time (e.g., Training with Dynamic Sparsity), both of which would raise financial and environmental concerns. In this work, we attempt to address this cost-reducing problem by introducing the FreeTickets concept, as the first solution which can boost the performance of sparse convolutional neural networks over their dense network equivalents by a large margin, while using for complete training only a fraction of the computational resources required by the latter. Concretely, we instantiate the FreeTickets concept, by proposing two novel efficient ensemble methods with dynamic sparsity, which yield in one shot many diverse and accurate tickets "for free" during the sparse training process. The combination of these free tickets into an ensemble demonstrates a significant improvement in accuracy, uncertainty estimation, robustness, and efficiency over the corresponding dense (ensemble) networks. Our results provide new insights into the strength of sparse neural networks and suggest that the benefits of sparsity go way beyond the usual training/inference expected efficiency. We will release all codes in https://github.com/Shiweiliuiiiiiii/FreeTickets.
Sparse Training via Boosting Pruning Plasticity with Neuroregeneration
Jun 19, 2021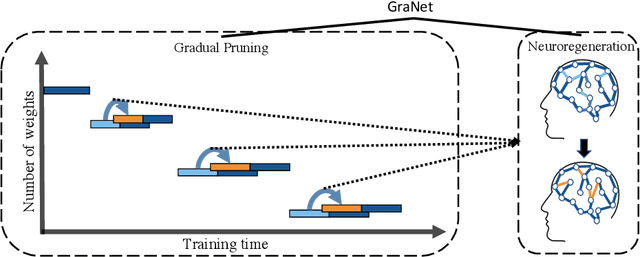
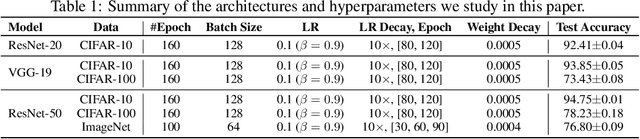
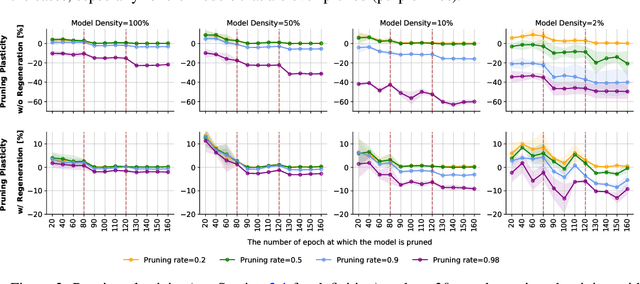
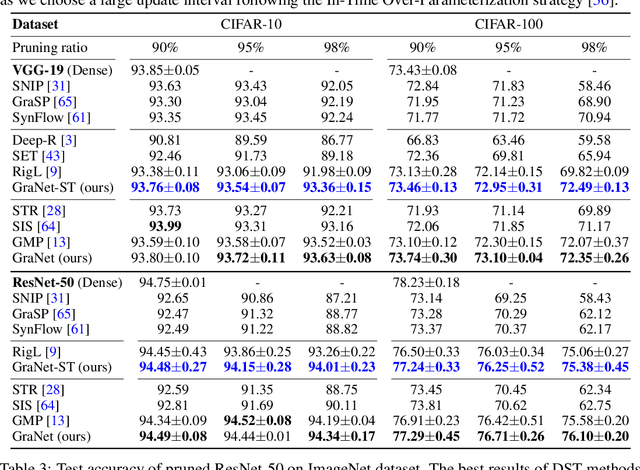
Works on lottery ticket hypothesis (LTH) and single-shot network pruning (SNIP) have raised a lot of attention currently on post-training pruning (iterative magnitude pruning), and before-training pruning (pruning at initialization). The former method suffers from an extremely large computation cost and the latter category of methods usually struggles with insufficient performance. In comparison, during-training pruning, a class of pruning methods that simultaneously enjoys the training/inference efficiency and the comparable performance, temporarily, has been less explored. To better understand during-training pruning, we quantitatively study the effect of pruning throughout training from the perspective of pruning plasticity (the ability of the pruned networks to recover the original performance). Pruning plasticity can help explain several other empirical observations about neural network pruning in literature. We further find that pruning plasticity can be substantially improved by injecting a brain-inspired mechanism called neuroregeneration, i.e., to regenerate the same number of connections as pruned. Based on the insights from pruning plasticity, we design a novel gradual magnitude pruning (GMP) method, named gradual pruning with zero-cost neuroregeneration (GraNet), and its dynamic sparse training (DST) variant (GraNet-ST). Both of them advance state of the art. Perhaps most impressively, the latter for the first time boosts the sparse-to-sparse training performance over various dense-to-sparse methods by a large margin with ResNet-50 on ImageNet. We will release all codes.
Quick and Robust Feature Selection: the Strength of Energy-efficient Sparse Training for Autoencoders
Dec 01, 2020

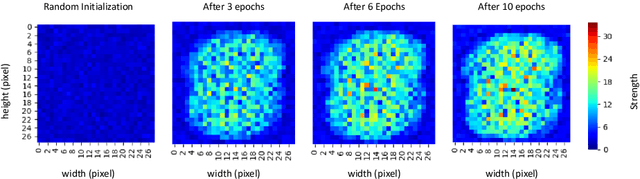

Major complications arise from the recent increase in the amount of high-dimensional data, including high computational costs and memory requirements. Feature selection, which identifies the most relevant and informative attributes of a dataset, has been introduced as a solution to this problem. Most of the existing feature selection methods are computationally inefficient; inefficient algorithms lead to high energy consumption, which is not desirable for devices with limited computational and energy resources. In this paper, a novel and flexible method for unsupervised feature selection is proposed. This method, named QuickSelection, introduces the strength of the neuron in sparse neural networks as a criterion to measure the feature importance. This criterion, blended with sparsely connected denoising autoencoders trained with the sparse evolutionary training procedure, derives the importance of all input features simultaneously. We implement QuickSelection in a purely sparse manner as opposed to the typical approach of using a binary mask over connections to simulate sparsity. It results in a considerable speed increase and memory reduction. When tested on several benchmark datasets, including five low-dimensional and three high-dimensional datasets, the proposed method is able to achieve the best trade-off of classification and clustering accuracy, running time, and maximum memory usage, among widely used approaches for feature selection. Besides, our proposed method requires the least amount of energy among the state-of-the-art autoencoder-based feature selection methods.
Topological Insights into Sparse Neural Networks
Jul 04, 2020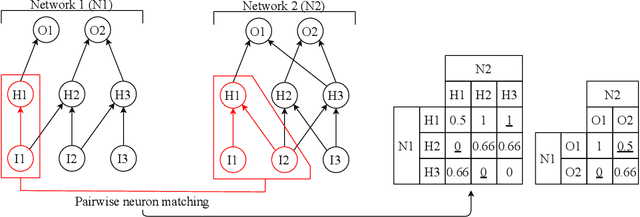

Sparse neural networks are effective approaches to reduce the resource requirements for the deployment of deep neural networks. Recently, the concept of adaptive sparse connectivity, has emerged to allow training sparse neural networks from scratch by optimizing the sparse structure during training. However, comparing different sparse topologies and determining how sparse topologies evolve during training, especially for the situation in which the sparse structure optimization is involved, remain as challenging open questions. This comparison becomes increasingly complex as the number of possible topological comparisons increases exponentially with the size of networks. In this work, we introduce an approach to understand and compare sparse neural network topologies from the perspective of graph theory. We first propose Neural Network Sparse Topology Distance (NNSTD) to measure the distance between different sparse neural networks. Further, we demonstrate that sparse neural networks can outperform over-parameterized models in terms of performance, even without any further structure optimization. To the end, we also show that adaptive sparse connectivity can always unveil a plenitude of sparse sub-networks with very different topologies which outperform the dense model, by quantifying and comparing their topological evolutionary processes. The latter findings complement the Lottery Ticket Hypothesis by showing that there is a much more efficient and robust way to find "winning tickets". Altogether, our results start enabling a better theoretical understanding of sparse neural networks, and demonstrate the utility of using graph theory to analyze them.