 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovieTeller: Tool-augmented Movie Synopsis with ID Consistent Progressive Abstraction
Feb 26, 2026With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external "tool" to establish Factual Groundings--precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM's reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines.
$M^3-Verse$: A "Spot the Difference" Challenge for Large Multimodal Models
Dec 21, 2025Modern Large Multimodal Models (LMMs) have demonstrated extraordinary ability in static image and single-state spatial-temporal understanding. However, their capacity to comprehend the dynamic changes of objects within a shared spatial context between two distinct video observations, remains largely unexplored. This ability to reason about transformations within a consistent environment is particularly crucial for advancements in the field of spatial intelligence. In this paper, we introduce $M^3-Verse$, a Multi-Modal, Multi-State, Multi-Dimensional benchmark, to formally evaluate this capability. It is built upon paired videos that provide multi-perspective observations of an indoor scene before and after a state change. The benchmark contains a total of 270 scenes and 2,932 questions, which are categorized into over 50 subtasks that probe 4 core capabilities. We evaluate 16 state-of-the-art LMMs and observe their limitations in tracking state transitions. To address these challenges, we further propose a simple yet effective baseline that achieves significant performance improvements in multi-state perception. $M^3-Verse$ thus provides a challenging new testbed to catalyze the development of next-generation models with a more holistic understanding of our dynamic visual world. You can get the construction pipeline from https://github.com/Wal-K-aWay/M3-Verse_pipeline and full benchmark data from https://www.modelscope.cn/datasets/WalKaWay/M3-Verse.
Chasing Better Deep Image Priors between Over- and Under-parameterization
Oct 31, 2024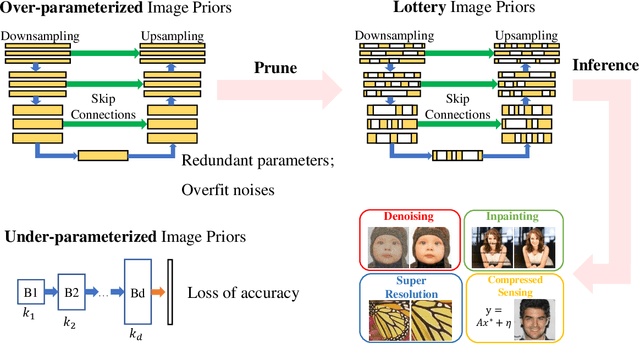


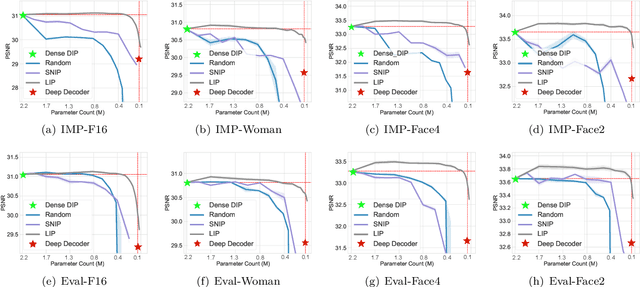
Deep Neural Networks (DNNs) are well-known to act as over-parameterized deep image priors (DIP) that regularize various image inverse problems. Meanwhile, researchers also proposed extremely compact, under-parameterized image priors (e.g., deep decoder) that are strikingly competent for image restoration too, despite a loss of accuracy. These two extremes push us to think whether there exists a better solution in the middle: between over- and under-parameterized image priors, can one identify "intermediate" parameterized image priors that achieve better trade-offs between performance, efficiency, and even preserving strong transferability? Drawing inspirations from the lottery ticket hypothesis (LTH), we conjecture and study a novel "lottery image prior" (LIP) by exploiting DNN inherent sparsity, stated as: given an over-parameterized DNN-based image prior, it will contain a sparse subnetwork that can be trained in isolation, to match the original DNN's performance when being applied as a prior to various image inverse problems. Our results validate the superiority of LIPs: we can successfully locate the LIP subnetworks from over-parameterized DIPs at substantial sparsity ranges. Those LIP subnetworks significantly outperform deep decoders under comparably compact model sizes (by often fully preserving the effectiveness of their over-parameterized counterparts), and they also possess high transferability across different images as well as restoration task types. Besides, we also extend LIP to compressive sensing image reconstruction, where a pre-trained GAN generator is used as the prior (in contrast to untrained DIP or deep decoder), and confirm its validity in this setting too. To our best knowledge, this is the first time that LTH is demonstrated to be relevant in the context of inverse problems or image priors.
* Codes are available at https://github.com/VITA-Group/Chasing-Better-DIPs
Expressive Power of Graph Neural Networks for Quadratic Programs
Jun 09, 2024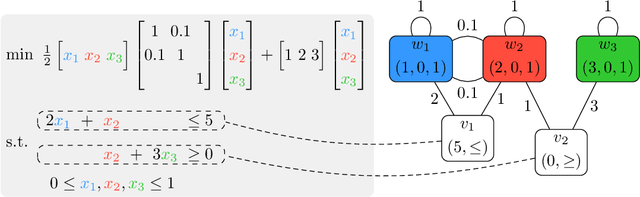
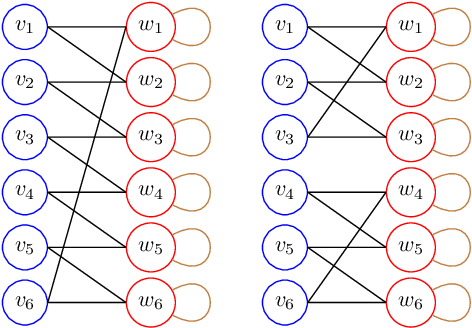
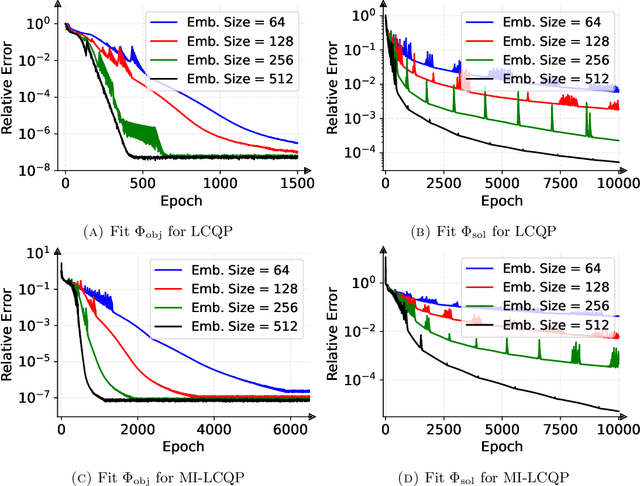
Quadratic programming (QP) is the most widely applied category of problems in nonlinear programming. Many applications require real-time/fast solutions, though not necessarily with high precision. Existing methods either involve matrix decomposition or use the preconditioned conjugate gradient method. For relatively large instances, these methods cannot achieve the real-time requirement unless there is an effective precondition. Recently, graph neural networks (GNNs) opened new possibilities for QP. Some promising empirical studies of applying GNNs for QP tasks show that GNNs can capture key characteristics of an optimization instance and provide adaptive guidance accordingly to crucial configurations during the solving process, or directly provide an approximate solution. Despite notable empirical observations, theoretical foundations are still lacking. In this work, we investigate the expressive or representative power of GNNs, a crucial aspect of neural network theory, specifically in the context of QP tasks, with both continuous and mixed-integer settings. We prove the existence of message-passing GNNs that can reliably represent key properties of quadratic programs, including feasibility, optimal objective value, and optimal solution. Our theory is validated by numerical results.
Learning to optimize: A tutorial for continuous and mixed-integer optimization
May 24, 2024Learning to Optimize (L2O) stands at the intersection of traditional optimization and machine learning, utilizing the capabilities of machine learning to enhance conventional optimization techniques. As real-world optimization problems frequently share common structures, L2O provides a tool to exploit these structures for better or faster solutions. This tutorial dives deep into L2O techniques, introducing how to accelerate optimization algorithms, promptly estimate the solutions, or even reshape the optimization problem itself, making it more adaptive to real-world applications. By considering the prerequisites for successful applications of L2O and the structure of the optimization problems at hand, this tutorial provides a comprehensive guide for practitioners and researchers alike.
Rethinking the Capacity of Graph Neural Networks for Branching Strategy
Feb 11, 2024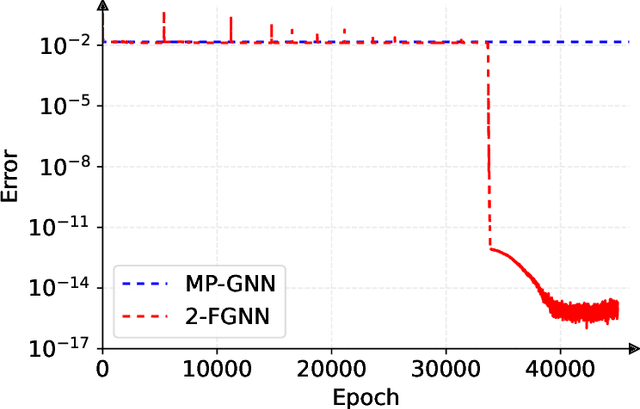
Graph neural networks (GNNs) have been widely used to predict properties and heuristics of mixed-integer linear programs (MILPs) and hence accelerate MILP solvers. This paper investigates the capacity of GNNs to represent strong branching (SB) scores that provide an efficient strategy in the branch-and-bound algorithm. Although message-passing GNN (MP-GNN), as the simplest GNN structure, is frequently employed in the existing literature to learn SB scores, we prove a fundamental limitation in its expressive power -- there exist two MILP instances with different SB scores that cannot be distinguished by any MP-GNN, regardless of the number of parameters. In addition, we establish a universal approximation theorem for another GNN structure called the second-order folklore GNN (2-FGNN). We show that for any data distribution over MILPs, there always exists a 2-FGNN that can approximate the SB score with arbitrarily high accuracy and arbitrarily high probability. A small-scale numerical experiment is conducted to directly validate our theoretical findings.
DIG-MILP: a Deep Instance Generator for Mixed-Integer Linear Programming with Feasibility Guarantee
Oct 20, 2023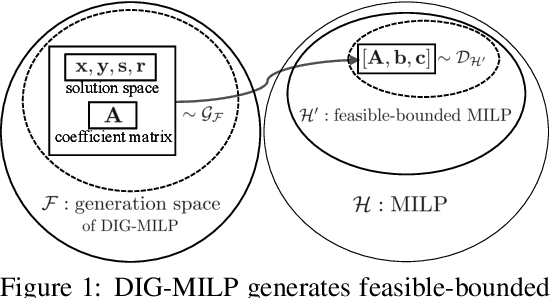

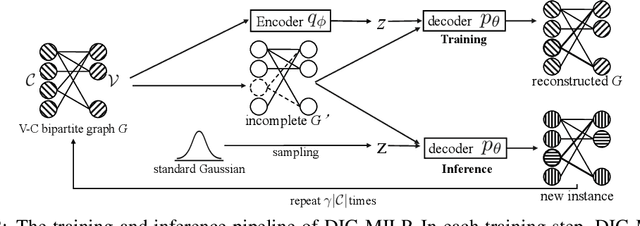

Mixed-integer linear programming (MILP) stands as a notable NP-hard problem pivotal to numerous crucial industrial applications. The development of effective algorithms, the tuning of solvers, and the training of machine learning models for MILP resolution all hinge on access to extensive, diverse, and representative data. Yet compared to the abundant naturally occurring data in image and text realms, MILP is markedly data deficient, underscoring the vital role of synthetic MILP generation. We present DIG-MILP, a deep generative framework based on variational auto-encoder (VAE), adept at extracting deep-level structural features from highly limited MILP data and producing instances that closely mirror the target data. Notably, by leveraging the MILP duality, DIG-MILP guarantees a correct and complete generation space as well as ensures the boundedness and feasibility of the generated instances. Our empirical study highlights the novelty and quality of the instances generated by DIG-MILP through two distinct downstream tasks: (S1) Data sharing, where solver solution times correlate highly positive between original and DIG-MILP-generated instances, allowing data sharing for solver tuning without publishing the original data; (S2) Data Augmentation, wherein the DIG-MILP-generated instances bolster the generalization performance of machine learning models tasked with resolving MILP problems.
Towards Constituting Mathematical Structures for Learning to Optimize
May 29, 2023
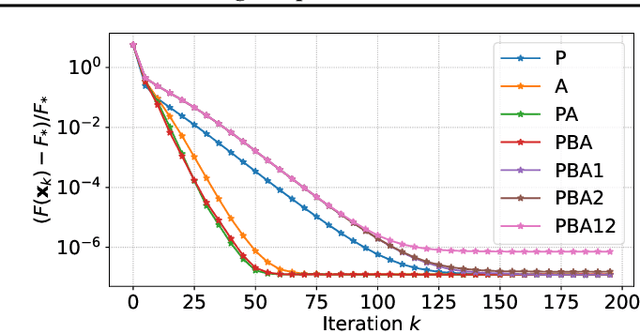

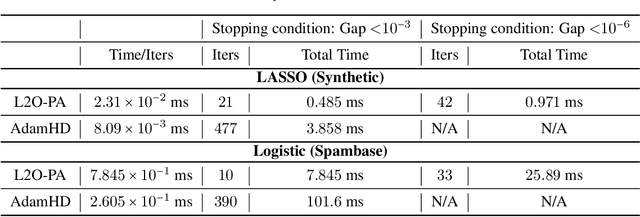
Learning to Optimize (L2O), a technique that utilizes machine learning to learn an optimization algorithm automatically from data, has gained arising attention in recent years. A generic L2O approach parameterizes the iterative update rule and learns the update direction as a black-box network. While the generic approach is widely applicable, the learned model can overfit and may not generalize well to out-of-distribution test sets. In this paper, we derive the basic mathematical conditions that successful update rules commonly satisfy. Consequently, we propose a novel L2O model with a mathematics-inspired structure that is broadly applicable and generalized well to out-of-distribution problems. Numerical simulations validate our theoretical findings and demonstrate the superior empirical performance of the proposed L2O model.
More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity
Jul 07, 2022
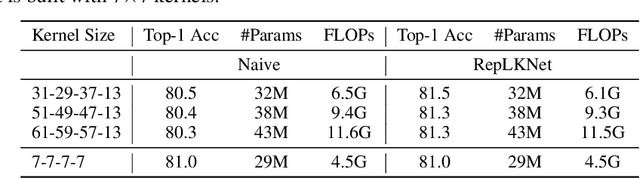
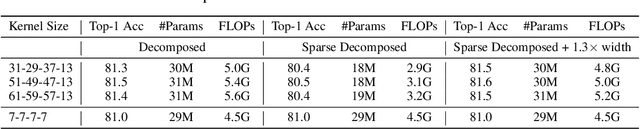
Transformers have quickly shined in the computer vision world since the emergence of Vision Transformers (ViTs). The dominant role of convolutional neural networks (CNNs) seems to be challenged by increasingly effective transformer-based models. Very recently, a couple of advanced convolutional models strike back with large kernels motivated by the local but large attention mechanism, showing appealing performance and efficiency. While one of them, i.e. RepLKNet, impressively manages to scale the kernel size to 31x31 with improved performance, the performance starts to saturate as the kernel size continues growing, compared to the scaling trend of advanced ViTs such as Swin Transformer. In this paper, we explore the possibility of training extreme convolutions larger than 31x31 and test whether the performance gap can be eliminated by strategically enlarging convolutions. This study ends up with a recipe for applying extremely large kernels from the perspective of sparsity, which can smoothly scale up kernels to 61x61 with better performance. Built on this recipe, we propose Sparse Large Kernel Network (SLaK), a pure CNN architecture equipped with 51x51 kernels that can perform on par with or better than state-of-the-art hierarchical Transformers and modern ConvNet architectures like ConvNeXt and RepLKNet, on ImageNet classification as well as typical downstream tasks. Our code is available here https://github.com/VITA-Group/SLaK.
The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training
Feb 05, 2022
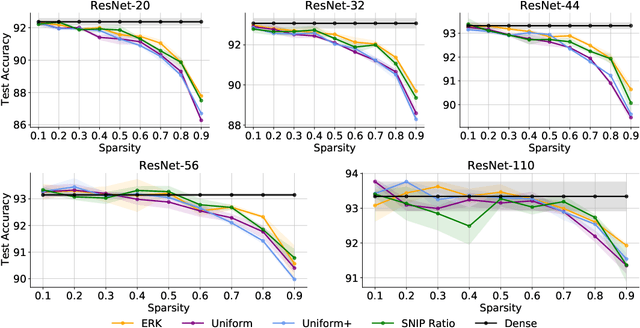
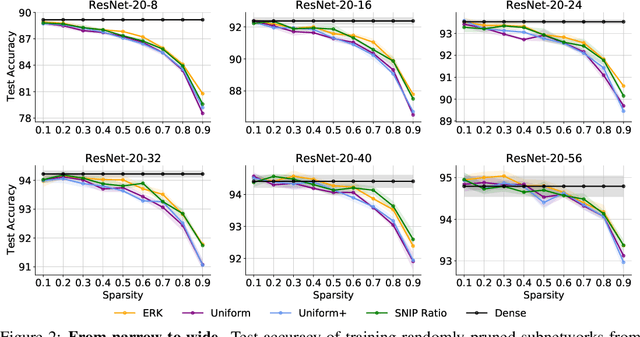
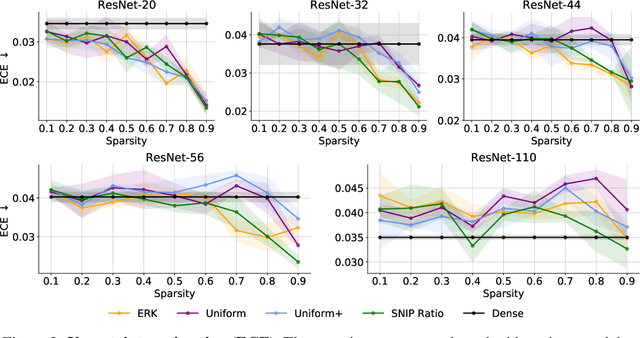
Random pruning is arguably the most naive way to attain sparsity in neural networks, but has been deemed uncompetitive by either post-training pruning or sparse training. In this paper, we focus on sparse training and highlight a perhaps counter-intuitive finding, that random pruning at initialization can be quite powerful for the sparse training of modern neural networks. Without any delicate pruning criteria or carefully pursued sparsity structures, we empirically demonstrate that sparsely training a randomly pruned network from scratch can match the performance of its dense equivalent. There are two key factors that contribute to this revival: (i) the network sizes matter: as the original dense networks grow wider and deeper, the performance of training a randomly pruned sparse network will quickly grow to matching that of its dense equivalent, even at high sparsity ratios; (ii) appropriate layer-wise sparsity ratios can be pre-chosen for sparse training, which shows to be another important performance booster. Simple as it looks, a randomly pruned subnetwork of Wide ResNet-50 can be sparsely trained to outperforming a dense Wide ResNet-50, on ImageNet. We also observed such randomly pruned networks outperform dense counterparts in other favorable aspects, such as out-of-distribution detection, uncertainty estimation, and adversarial robustness. Overall, our results strongly suggest there is larger-than-expected room for sparse training at scale, and the benefits of sparsity might be more universal beyond carefully designed pruning. Our source code can be found at https://github.com/VITA-Group/Random_Pruning.