 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoX: Low-Rank Extrapolation Robustifies LLM Safety Against Fine-tuning
Jun 18, 2025Large Language Models (LLMs) have become indispensable in real-world applications. However, their widespread adoption raises significant safety concerns, particularly in responding to socially harmful questions. Despite substantial efforts to improve model safety through alignment, aligned models can still have their safety protections undermined by subsequent fine-tuning - even when the additional training data appears benign. In this paper, we empirically demonstrate that this vulnerability stems from the sensitivity of safety-critical low-rank subspaces in LLM parameters to fine-tuning. Building on this insight, we propose a novel training-free method, termed Low-Rank Extrapolation (LoX), to enhance safety robustness by extrapolating the safety subspace of an aligned LLM. Our experimental results confirm the effectiveness of LoX, demonstrating significant improvements in robustness against both benign and malicious fine-tuning attacks while preserving the model's adaptability to new tasks. For instance, LoX leads to 11% to 54% absolute reductions in attack success rates (ASR) facing benign or malicious fine-tuning attacks. By investigating the ASR landscape of parameters, we attribute the success of LoX to that the extrapolation moves LLM parameters to a flatter zone, thereby less sensitive to perturbations. The code is available at github.com/VITA-Group/LoX.
Make Optimization Once and for All with Fine-grained Guidance
Mar 14, 2025Learning to Optimize (L2O) enhances optimization efficiency with integrated neural networks. L2O paradigms achieve great outcomes, e.g., refitting optimizer, generating unseen solutions iteratively or directly. However, conventional L2O methods require intricate design and rely on specific optimization processes, limiting scalability and generalization. Our analyses explore general framework for learning optimization, called Diff-L2O, focusing on augmenting sampled solutions from a wider view rather than local updates in real optimization process only. Meanwhile, we give the related generalization bound, showing that the sample diversity of Diff-L2O brings better performance. This bound can be simply applied to other fields, discussing diversity, mean-variance, and different tasks. Diff-L2O's strong compatibility is empirically verified with only minute-level training, comparing with other hour-levels.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
Take the Bull by the Horns: Hard Sample-Reweighted Continual Training Improves LLM Generalization
Mar 01, 2024In the rapidly advancing arena of large language models (LLMs), a key challenge is to enhance their capabilities amid a looming shortage of high-quality training data. Our study starts from an empirical strategy for the light continual training of LLMs using their original pre-training data sets, with a specific focus on selective retention of samples that incur moderately high losses. These samples are deemed informative and beneficial for model refinement, contrasting with the highest-loss samples, which would be discarded due to their correlation with data noise and complexity. We then formalize this strategy into a principled framework of Instance-Reweighted Distributionally Robust Optimization (IR-DRO). IR-DRO is designed to dynamically prioritize the training focus on informative samples through an instance reweighting mechanism, streamlined by a closed-form solution for straightforward integration into established training protocols. Through rigorous experimentation with various models and datasets, our findings indicate that our sample-targeted methods significantly improve LLM performance across multiple benchmarks, in both continual pre-training and instruction tuning scenarios. Our codes are available at https://github.com/VITA-Group/HardFocusTraining.
Rethinking PGD Attack: Is Sign Function Necessary?
Dec 03, 2023



Neural networks have demonstrated success in various domains, yet their performance can be significantly degraded by even a small input perturbation. Consequently, the construction of such perturbations, known as adversarial attacks, has gained significant attention, many of which fall within "white-box" scenarios where we have full access to the neural network. Existing attack algorithms, such as the projected gradient descent (PGD), commonly take the sign function on the raw gradient before updating adversarial inputs, thereby neglecting gradient magnitude information. In this paper, we present a theoretical analysis of how such sign-based update algorithm influences step-wise attack performance, as well as its caveat. We also interpret why previous attempts of directly using raw gradients failed. Based on that, we further propose a new raw gradient descent (RGD) algorithm that eliminates the use of sign. Specifically, we convert the constrained optimization problem into an unconstrained one, by introducing a new hidden variable of non-clipped perturbation that can move beyond the constraint. The effectiveness of the proposed RGD algorithm has been demonstrated extensively in experiments, outperforming PGD and other competitors in various settings, without incurring any additional computational overhead. The codes is available in https://github.com/JunjieYang97/RGD.
Orca 2: Teaching Small Language Models How to Reason
Nov 21, 2023



Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
Data Distillation Can Be Like Vodka: Distilling More Times For Better Quality
Oct 10, 2023Dataset distillation aims to minimize the time and memory needed for training deep networks on large datasets, by creating a small set of synthetic images that has a similar generalization performance to that of the full dataset. However, current dataset distillation techniques fall short, showing a notable performance gap when compared to training on the original data. In this work, we are the first to argue that using just one synthetic subset for distillation will not yield optimal generalization performance. This is because the training dynamics of deep networks drastically change during the training. Hence, multiple synthetic subsets are required to capture the training dynamics at different phases of training. To address this issue, we propose Progressive Dataset Distillation (PDD). PDD synthesizes multiple small sets of synthetic images, each conditioned on the previous sets, and trains the model on the cumulative union of these subsets without requiring additional training time. Our extensive experiments show that PDD can effectively improve the performance of existing dataset distillation methods by up to 4.3%. In addition, our method for the first time enable generating considerably larger synthetic datasets.
Sparsity May Cry: Let Us Fail Sparse Neural Networks Together!
Mar 03, 2023

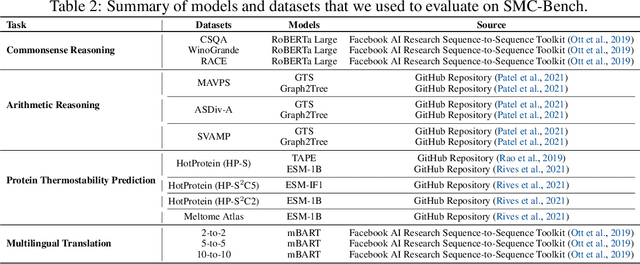

Sparse Neural Networks (SNNs) have received voluminous attention predominantly due to growing computational and memory footprints of consistently exploding parameter count in large-scale models. Similar to their dense counterparts, recent SNNs generalize just as well and are equipped with numerous favorable benefits (e.g., low complexity, high scalability, and robustness), sometimes even better than the original dense networks. As research effort is focused on developing increasingly sophisticated sparse algorithms, it is startling that a comprehensive benchmark to evaluate the effectiveness of these algorithms has been highly overlooked. In absence of a carefully crafted evaluation benchmark, most if not all, sparse algorithms are evaluated against fairly simple and naive tasks (eg. CIFAR, ImageNet, GLUE, etc.), which can potentially camouflage many advantages as well unexpected predicaments of SNNs. In pursuit of a more general evaluation and unveiling the true potential of sparse algorithms, we introduce "Sparsity May Cry" Benchmark (SMC-Bench), a collection of carefully-curated 4 diverse tasks with 10 datasets, that accounts for capturing a wide range of domain-specific and sophisticated knowledge. Our systemic evaluation of the most representative sparse algorithms reveals an important obscured observation: the state-of-the-art magnitude- and/or gradient-based sparse algorithms seemingly fail to perform on SMC-Bench when applied out-of-the-box, sometimes at significantly trivial sparsity as low as 5%. By incorporating these well-thought and diverse tasks, SMC-Bench is designed to favor and encourage the development of more scalable and generalizable sparse algorithms.
M-L2O: Towards Generalizable Learning-to-Optimize by Test-Time Fast Self-Adaptation
Feb 28, 2023
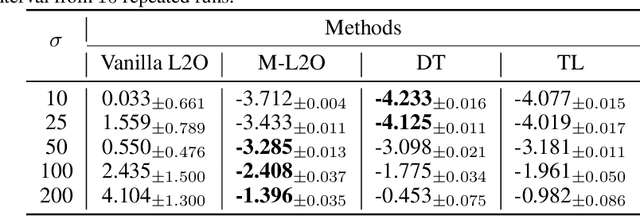


Learning to Optimize (L2O) has drawn increasing attention as it often remarkably accelerates the optimization procedure of complex tasks by ``overfitting" specific task type, leading to enhanced performance compared to analytical optimizers. Generally, L2O develops a parameterized optimization method (i.e., ``optimizer") by learning from solving sample problems. This data-driven procedure yields L2O that can efficiently solve problems similar to those seen in training, that is, drawn from the same ``task distribution". However, such learned optimizers often struggle when new test problems come with a substantially deviation from the training task distribution. This paper investigates a potential solution to this open challenge, by meta-training an L2O optimizer that can perform fast test-time self-adaptation to an out-of-distribution task, in only a few steps. We theoretically characterize the generalization of L2O, and further show that our proposed framework (termed as M-L2O) provably facilitates rapid task adaptation by locating well-adapted initial points for the optimizer weight. Empirical observations on several classic tasks like LASSO and Quadratic, demonstrate that M-L2O converges significantly faster than vanilla L2O with only $5$ steps of adaptation, echoing our theoretical results. Codes are available in https://github.com/VITA-Group/M-L2O.
Is Attention All NeRF Needs?
Jul 27, 2022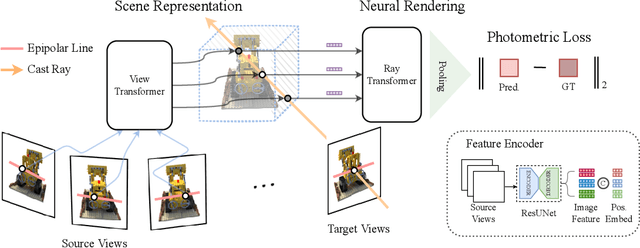
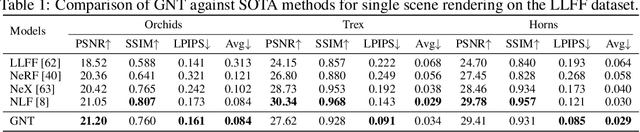
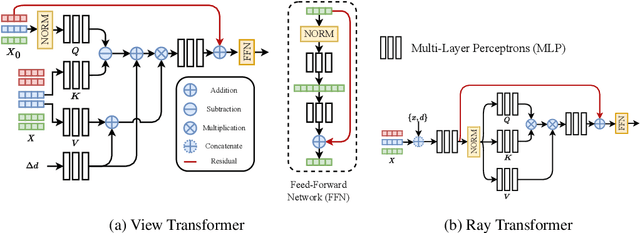

We present Generalizable NeRF Transformer (GNT), a pure, unified transformer-based architecture that efficiently reconstructs Neural Radiance Fields (NeRFs) on the fly from source views. Unlike prior works on NeRF that optimize a per-scene implicit representation by inverting a handcrafted rendering equation, GNT achieves generalizable neural scene representation and rendering, by encapsulating two transformer-based stages. The first stage of GNT, called view transformer, leverages multi-view geometry as an inductive bias for attention-based scene representation, and predicts coordinate-aligned features by aggregating information from epipolar lines on the neighboring views. The second stage of GNT, named ray transformer, renders novel views by ray marching and directly decodes the sequence of sampled point features using the attention mechanism. Our experiments demonstrate that when optimized on a single scene, GNT can successfully reconstruct NeRF without explicit rendering formula, and even improve the PSNR by ~1.3dB on complex scenes due to the learnable ray renderer. When trained across various scenes, GNT consistently achieves the state-of-the-art performance when transferring to forward-facing LLFF dataset (LPIPS ~20%, SSIM ~25%$) and synthetic blender dataset (LPIPS ~20%, SSIM ~4%). In addition, we show that depth and occlusion can be inferred from the learned attention maps, which implies that the pure attention mechanism is capable of learning a physically-grounded rendering process. All these results bring us one step closer to the tantalizing hope of utilizing transformers as the "universal modeling tool" even for graphics. Please refer to our project page for video results: https://vita-group.github.io/GNT/.