 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining
Feb 10, 2025



Pretraining large language models (LLMs) on vast and heterogeneous datasets is crucial for achieving state-of-the-art performance across diverse downstream tasks. However, current training paradigms treat all samples equally, overlooking the importance or relevance of individual samples throughout the training process. Existing reweighting strategies, which primarily focus on group-level data importance, fail to leverage fine-grained instance-level information and do not adapt dynamically to individual sample importance as training progresses. In this paper, we introduce novel algorithms for dynamic, instance-level data reweighting aimed at improving both the efficiency and effectiveness of LLM pretraining. Our methods adjust the weight of each training sample based on its loss value in an online fashion, allowing the model to dynamically focus on more informative or important samples at the current training stage. In particular, our framework allows us to systematically devise reweighting strategies deprioritizing redundant or uninformative data, which we find tend to work best. Furthermore, we develop a new theoretical framework for analyzing the impact of loss-based reweighting on the convergence of gradient-based optimization, providing the first formal characterization of how these strategies affect convergence bounds. We empirically validate our approach across a spectrum of tasks, from pretraining 7B and 1.4B parameter LLMs to smaller-scale language models and linear regression problems, demonstrating that our loss-based reweighting approach can lead to faster convergence and significantly improved performance.
Take the Bull by the Horns: Hard Sample-Reweighted Continual Training Improves LLM Generalization
Mar 01, 2024In the rapidly advancing arena of large language models (LLMs), a key challenge is to enhance their capabilities amid a looming shortage of high-quality training data. Our study starts from an empirical strategy for the light continual training of LLMs using their original pre-training data sets, with a specific focus on selective retention of samples that incur moderately high losses. These samples are deemed informative and beneficial for model refinement, contrasting with the highest-loss samples, which would be discarded due to their correlation with data noise and complexity. We then formalize this strategy into a principled framework of Instance-Reweighted Distributionally Robust Optimization (IR-DRO). IR-DRO is designed to dynamically prioritize the training focus on informative samples through an instance reweighting mechanism, streamlined by a closed-form solution for straightforward integration into established training protocols. Through rigorous experimentation with various models and datasets, our findings indicate that our sample-targeted methods significantly improve LLM performance across multiple benchmarks, in both continual pre-training and instruction tuning scenarios. Our codes are available at https://github.com/VITA-Group/HardFocusTraining.
Non-Convex Bilevel Optimization with Time-Varying Objective Functions
Aug 07, 2023Bilevel optimization has become a powerful tool in a wide variety of machine learning problems. However, the current nonconvex bilevel optimization considers an offline dataset and static functions, which may not work well in emerging online applications with streaming data and time-varying functions. In this work, we study online bilevel optimization (OBO) where the functions can be time-varying and the agent continuously updates the decisions with online streaming data. To deal with the function variations and the unavailability of the true hypergradients in OBO, we propose a single-loop online bilevel optimizer with window averaging (SOBOW), which updates the outer-level decision based on a window average of the most recent hypergradient estimations stored in the memory. Compared to existing algorithms, SOBOW is computationally efficient and does not need to know previous functions. To handle the unique technical difficulties rooted in single-loop update and function variations for OBO, we develop a novel analytical technique that disentangles the complex couplings between decision variables, and carefully controls the hypergradient estimation error. We show that SOBOW can achieve a sublinear bilevel local regret under mild conditions. Extensive experiments across multiple domains corroborate the effectiveness of SOBOW.
Doubly Robust Instance-Reweighted Adversarial Training
Aug 01, 2023



Assigning importance weights to adversarial data has achieved great success in training adversarially robust networks under limited model capacity. However, existing instance-reweighted adversarial training (AT) methods heavily depend on heuristics and/or geometric interpretations to determine those importance weights, making these algorithms lack rigorous theoretical justification/guarantee. Moreover, recent research has shown that adversarial training suffers from a severe non-uniform robust performance across the training distribution, e.g., data points belonging to some classes can be much more vulnerable to adversarial attacks than others. To address both issues, in this paper, we propose a novel doubly-robust instance reweighted AT framework, which allows to obtain the importance weights via exploring distributionally robust optimization (DRO) techniques, and at the same time boosts the robustness on the most vulnerable examples. In particular, our importance weights are obtained by optimizing the KL-divergence regularized loss function, which allows us to devise new algorithms with a theoretical convergence guarantee. Experiments on standard classification datasets demonstrate that our proposed approach outperforms related state-of-the-art baseline methods in terms of average robust performance, and at the same time improves the robustness against attacks on the weakest data points. Codes will be available soon.
Algorithm Design for Online Meta-Learning with Task Boundary Detection
Feb 02, 2023Online meta-learning has recently emerged as a marriage between batch meta-learning and online learning, for achieving the capability of quick adaptation on new tasks in a lifelong manner. However, most existing approaches focus on the restrictive setting where the distribution of the online tasks remains fixed with known task boundaries. In this work, we relax these assumptions and propose a novel algorithm for task-agnostic online meta-learning in non-stationary environments. More specifically, we first propose two simple but effective detection mechanisms of task switches and distribution shift based on empirical observations, which serve as a key building block for more elegant online model updates in our algorithm: the task switch detection mechanism allows reusing of the best model available for the current task at hand, and the distribution shift detection mechanism differentiates the meta model update in order to preserve the knowledge for in-distribution tasks and quickly learn the new knowledge for out-of-distribution tasks. In particular, our online meta model updates are based only on the current data, which eliminates the need of storing previous data as required in most existing methods. We further show that a sublinear task-averaged regret can be achieved for our algorithm under mild conditions. Empirical studies on three different benchmarks clearly demonstrate the significant advantage of our algorithm over related baseline approaches.
A Constrained Optimization Approach to Bilevel Optimization with Multiple Inner Minima
Mar 01, 2022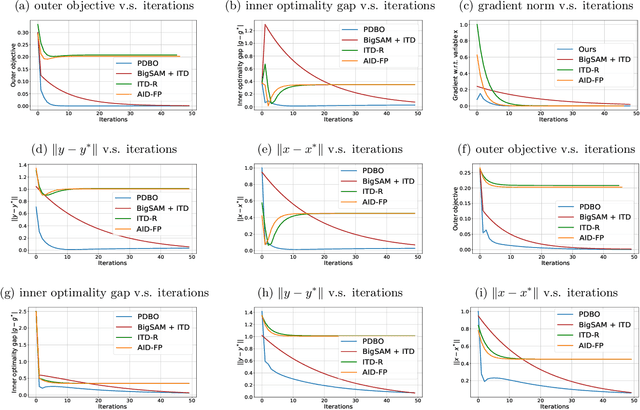
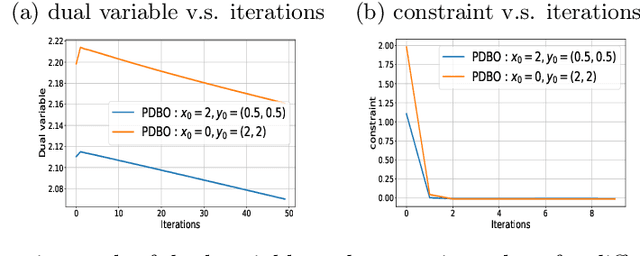
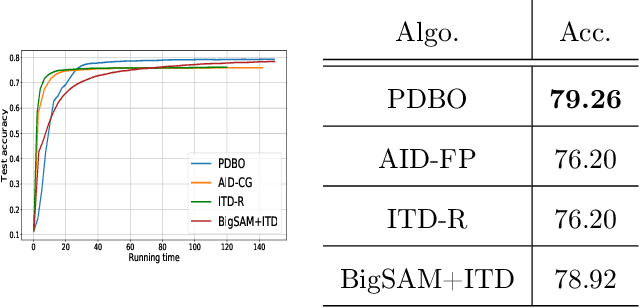
Bilevel optimization has found extensive applications in modern machine learning problems such as hyperparameter optimization, neural architecture search, meta-learning, etc. While bilevel problems with a unique inner minimal point (e.g., where the inner function is strongly convex) are well understood, bilevel problems with multiple inner minimal points remains to be a challenging and open problem. Existing algorithms designed for such a problem were applicable to restricted situations and do not come with the full guarantee of convergence. In this paper, we propose a new approach, which convert the bilevel problem to an equivalent constrained optimization, and then the primal-dual algorithm can be used to solve the problem. Such an approach enjoys a few advantages including (a) addresses the multiple inner minima challenge; (b) features fully first-order efficiency without involving second-order Hessian and Jacobian computations, as opposed to most existing gradient-based bilevel algorithms; (c) admits the convergence guarantee via constrained nonconvex optimization. Our experiments further demonstrate the desired performance of the proposed approach.
ES-Based Jacobian Enables Faster Bilevel Optimization
Oct 13, 2021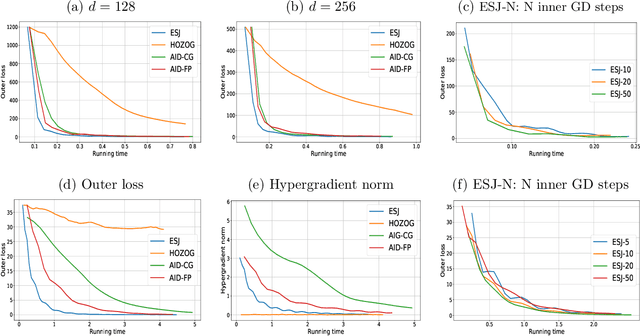

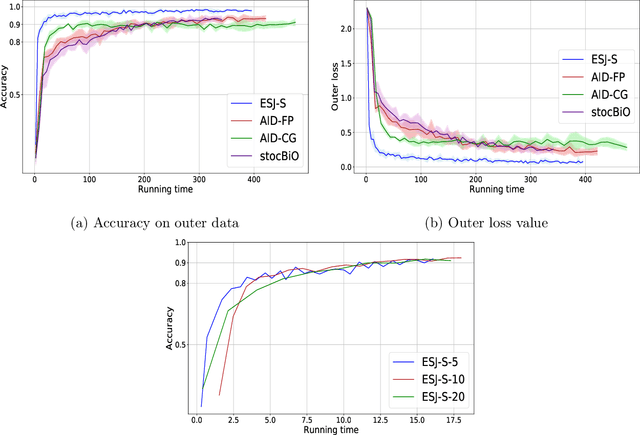
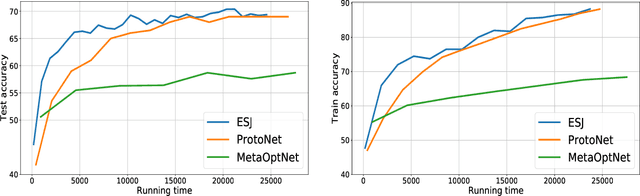
Bilevel optimization (BO) has arisen as a powerful tool for solving many modern machine learning problems. However, due to the nested structure of BO, existing gradient-based methods require second-order derivative approximations via Jacobian- or/and Hessian-vector computations, which can be very costly in practice, especially with large neural network models. In this work, we propose a novel BO algorithm, which adopts Evolution Strategies (ES) based method to approximate the response Jacobian matrix in the hypergradient of BO, and hence fully eliminates all second-order computations. We call our algorithm as ESJ (which stands for the ES-based Jacobian method) and further extend it to the stochastic setting as ESJ-S. Theoretically, we characterize the convergence guarantee and computational complexity for our algorithms. Experimentally, we demonstrate the superiority of our proposed algorithms compared to the state of the art methods on various bilevel problems. Particularly, in our experiment in the few-shot meta-learning problem, we meta-learn the twelve millions parameters of a ResNet-12 network over the miniImageNet dataset, which evidently demonstrates the scalability of our ES-based bilevel approach and its feasibility in the large-scale setting.
A sequential guiding network with attention for image captioning
Nov 01, 2018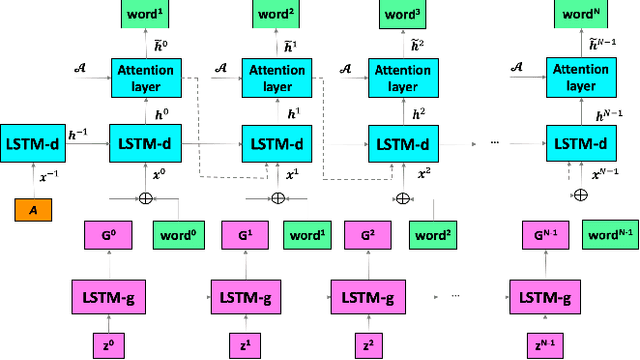
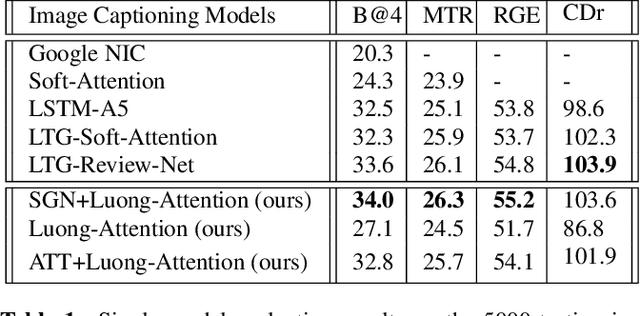
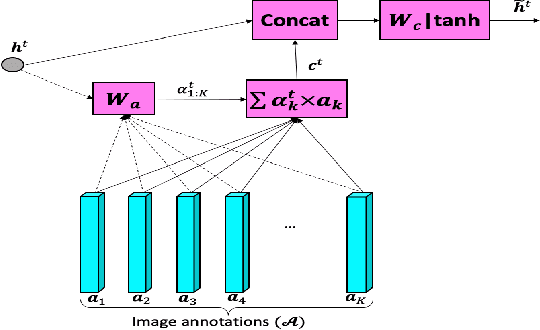
The recent advances of deep learning in both computer vision (CV)and natural language processing (NLP) provide us a new way of un-derstanding semantics, by which we can deal with more challeng-ing tasks such as automatic description generation from natural im-ages. In this challenge, the encoder-decoder framework has achievedpromising performance when a convolutional neural network (CNN)is used as image encoder and a recurrent neural network (RNN) asdecoder. In this paper, we introduce a sequential guiding networkthat guides the decoder during word generation. The new model is anextension of the encoder-decoder framework with attention that hasan additional guiding long short-term memory (LSTM) and can betrained in an end-to-end manner by using image/descriptions pairs.We validate our approach by conducting extensive experiments on abenchmark dataset, i.e., MS COCO Captions. The proposed model achieves significant improvement comparing to the other state-of-the-art deep learning models.