 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining
Feb 10, 2025



Pretraining large language models (LLMs) on vast and heterogeneous datasets is crucial for achieving state-of-the-art performance across diverse downstream tasks. However, current training paradigms treat all samples equally, overlooking the importance or relevance of individual samples throughout the training process. Existing reweighting strategies, which primarily focus on group-level data importance, fail to leverage fine-grained instance-level information and do not adapt dynamically to individual sample importance as training progresses. In this paper, we introduce novel algorithms for dynamic, instance-level data reweighting aimed at improving both the efficiency and effectiveness of LLM pretraining. Our methods adjust the weight of each training sample based on its loss value in an online fashion, allowing the model to dynamically focus on more informative or important samples at the current training stage. In particular, our framework allows us to systematically devise reweighting strategies deprioritizing redundant or uninformative data, which we find tend to work best. Furthermore, we develop a new theoretical framework for analyzing the impact of loss-based reweighting on the convergence of gradient-based optimization, providing the first formal characterization of how these strategies affect convergence bounds. We empirically validate our approach across a spectrum of tasks, from pretraining 7B and 1.4B parameter LLMs to smaller-scale language models and linear regression problems, demonstrating that our loss-based reweighting approach can lead to faster convergence and significantly improved performance.
On Distributed and Asynchronous Sampling of Gaussian Processes for Sequential Binary Hypothesis Testing
Sep 14, 2023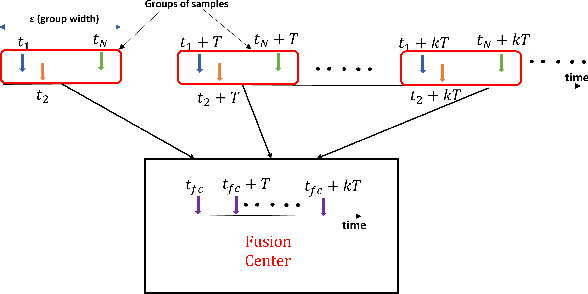
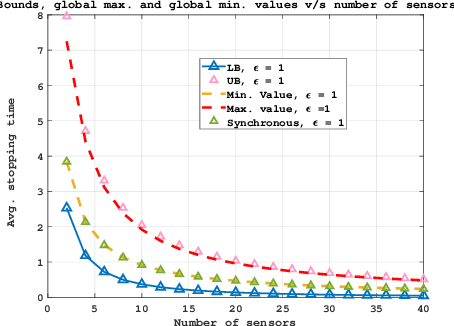
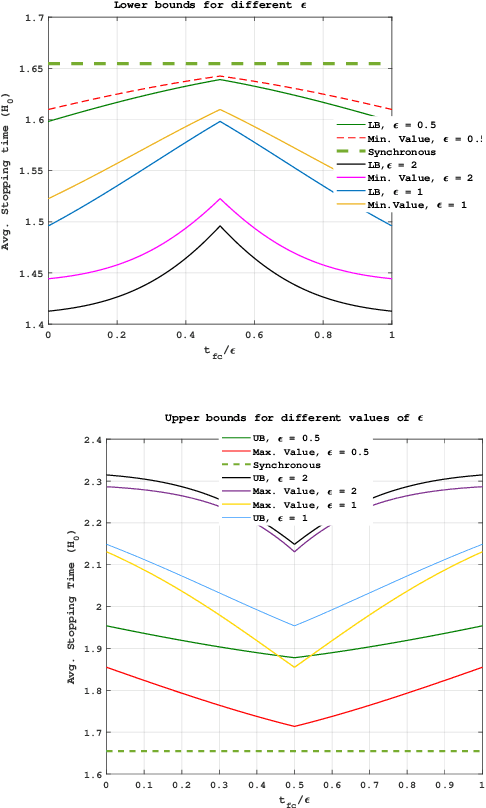
In this work, we consider a binary sequential hypothesis testing problem with distributed and asynchronous measurements. The aim is to analyze the effect of sampling times of jointly \textit{wide-sense stationary} (WSS) Gaussian observation processes at distributed sensors on the expected stopping time of the sequential test at the fusion center (FC). The distributed system is such that the sensors and the FC sample observations periodically, where the sampling times are not necessarily synchronous, i.e., the sampling times at different sensors and the FC may be different from each other. \color{black} The sampling times, however, are restricted to be within a time window and a sample obtained within the window is assumed to be \textit{uncorrelated} with samples outside the window. We also assume that correlations may exist only between the observations sampled at the FC and those at the sensors in a pairwise manner (sensor pairs not including the FC have independent observations). The effect of \textit{asynchronous} sampling on the SPRT performance is analyzed by obtaining bounds for the expected stopping time. We illustrate the validity of the theoretical results with numerical results.
Ordered Transmission-based Detection in Distributed Networks in the Presence of Byzantines
Jan 21, 2022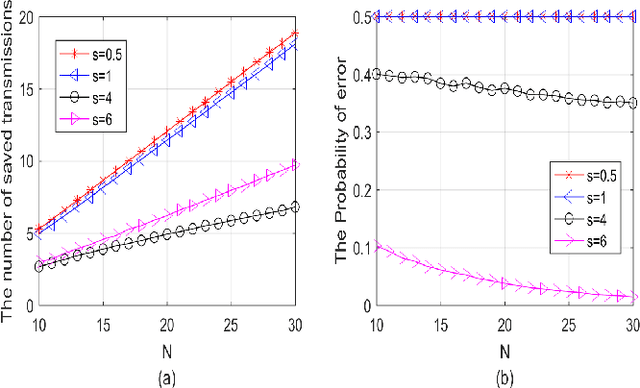
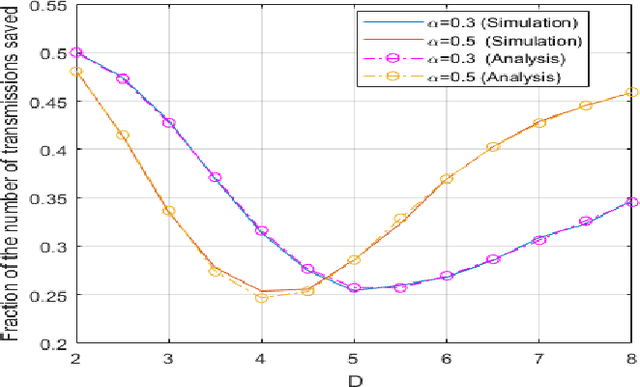
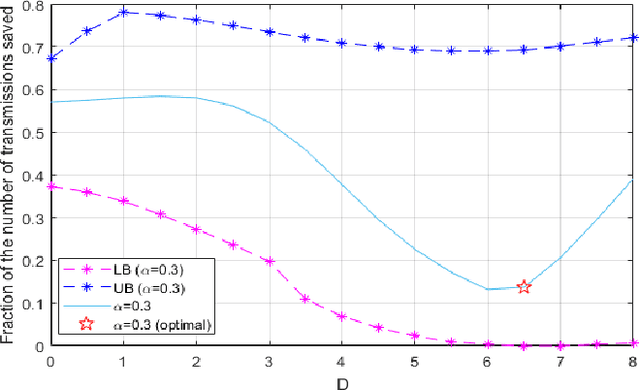
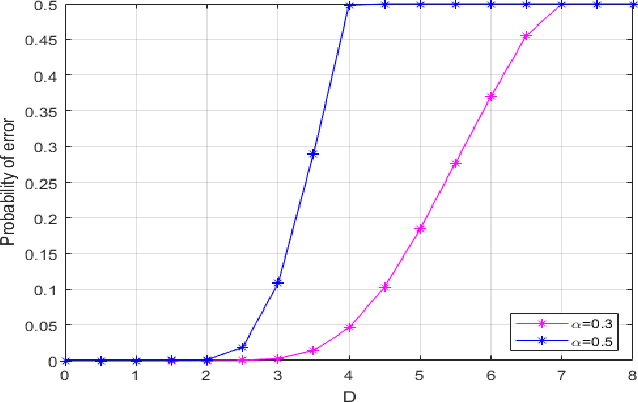
The ordered transmission (OT) scheme reduces the number of transmissions needed in the network to make the final decision, while it maintains the same probability of error as the system without using OT scheme. In this paper, we investigate the performance of the system using OT scheme in the presence of Byzantine attacks for binary hypothesis testing problem. We analyze the probability of error for the system under attack and evaluate the number of transmissions saved using Monte Carlo method. We also derive the bounds for the number of transmissions saved in the system under attack. The optimal attacking strategy for the OT-based system is investigated. Simulation results show that the Byzantine attacks have significant impact on the number of transmissions saved even when the signal strength is sufficiently large.
Anomalous Instance Detection in Deep Learning: A Survey
Mar 16, 2020

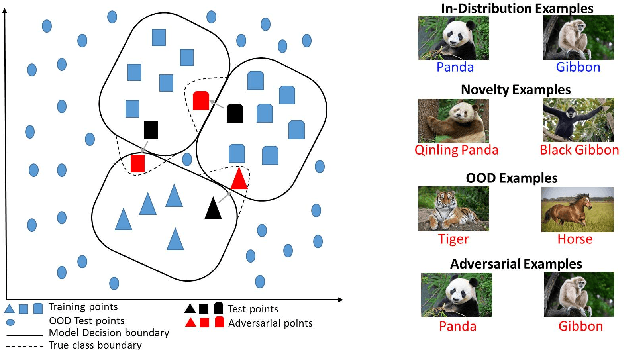
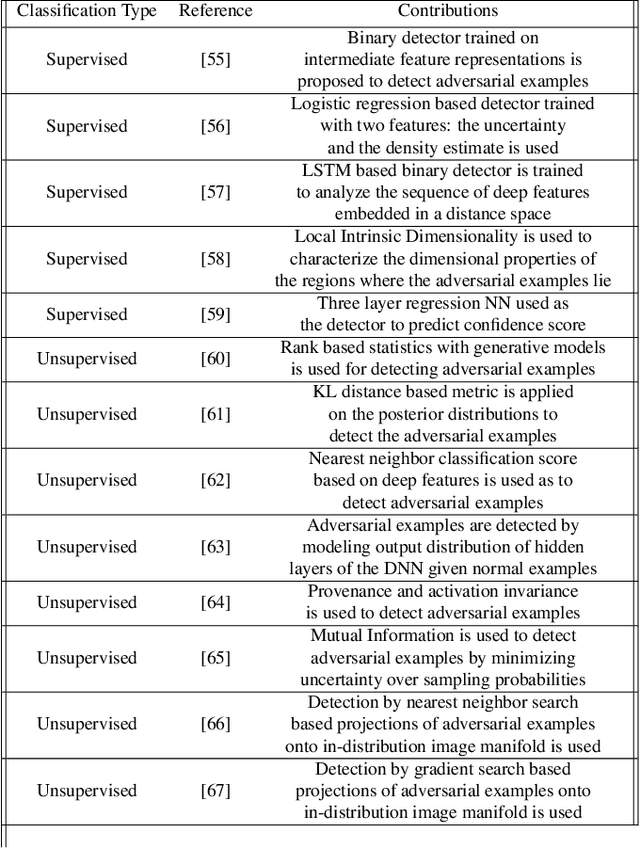
Deep Learning (DL) is vulnerable to out-of-distribution and adversarial examples resulting in incorrect outputs. To make DL more robust, several posthoc anomaly detection techniques to detect (and discard) these anomalous samples have been proposed in the recent past. This survey tries to provide a structured and comprehensive overview of the research on anomaly detection for DL based applications. We provide a taxonomy for existing techniques based on their underlying assumptions and adopted approaches. We discuss various techniques in each of the categories and provide the relative strengths and weaknesses of the approaches. Our goal in this survey is to provide an easier yet better understanding of the techniques belonging to different categories in which research has been done on this topic. Finally, we highlight the unsolved research challenges while applying anomaly detection techniques in DL systems and present some high-impact future research directions.
Parallel Restarted SPIDER -- Communication Efficient Distributed Nonconvex Optimization with Optimal Computation Complexity
Dec 12, 2019
In this paper, we propose a distributed algorithm for stochastic smooth, non-convex optimization. We assume a worker-server architecture where $N$ nodes, each having $n$ (potentially infinite) number of samples, collaborate with the help of a central server to perform the optimization task. The global objective is to minimize the average of local cost functions available at individual nodes. The proposed approach is a non-trivial extension of the popular parallel-restarted SGD algorithm, incorporating the optimal variance-reduction based SPIDER gradient estimator into it. We prove convergence of our algorithm to a first-order stationary solution. The proposed approach achieves the best known communication complexity $O(\epsilon^{-1})$ along with the optimal computation complexity. For finite-sum problems (finite $n$), we achieve the optimal computation (IFO) complexity $O(\sqrt{Nn}\epsilon^{-1})$. For online problems ($n$ unknown or infinite), we achieve the optimal IFO complexity $O(\epsilon^{-3/2})$. In both the cases, we maintain the linear speedup achieved by existing methods. This is a massive improvement over the $O(\epsilon^{-2})$ IFO complexity of the existing approaches. Additionally, our algorithm is general enough to allow non-identical distributions of data across workers, as in the recently proposed federated learning paradigm.