 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Optimal LLM Routing with Limited User Feedback under User Satisfaction Guarantees
Jun 12, 2026Inference costs for large language model (LLM) applications are rapidly growing, driven by surging demand and rising infrastructure cost. Users expect high-quality responses, and in commercial settings this is formally codified in Service Level Agreements (SLAs), creating a fundamental tension between cost and quality. Recent progress on cost-aware LLM request routing has shown potential to resolve this tension, but existing approaches rely on complete feedback signals, offline training, extensive per-workload tuning, and most lack SLA guarantees or inference-time adaptivity. We introduce SLARouter, an online routing algorithm that learns a cost-optimal policy from the sparse, one-sided user feedback available in production systems. SLARouter provides theoretical guarantees for both cost optimality and strict SLA compliance. Experiments across a wide range of LLM benchmarks show that SLARouter satisfies SLA constraints without the need for per-benchmark tuning, reducing operating cost by up to 2.2x over existing baselines.
Agentic Performance at the Edge: Insights from Benchmarking
May 11, 2026Agentic artificial intelligence (AI) is a natural fit for Internet of Things (IoT) and edge systems, but edge deployments are often constrained to models around 8 billion parameters or smaller. An important question is: How much agentic-task quality is lost when model size is constrained by memory, power, and latency budgets? To address this question, in this paper, we provide an initial empirical study considering edge-focused model scaling, general-purpose versus coder-oriented model effects, and tool-enabled execution under a fixed protocol. We introduce a domain-conditioned evaluation methodology, an implementation-grounded analysis of model-tool interactions, practical guidance for model selection under constraints, and an analysis of failure modes that reveals distinct semantic versus execution failure patterns across model families. Our core finding is that edge-agent quality is not a simple function of parameter count. Robust deployment depends on the joint design of model choice and tool workflow. Domain-conditioned analysis reveals Pareto fronts in the accuracy-latency space that can guide strategy selection based on operational priorities.
Preventing Rank Collapse in Federated Low-Rank Adaptation with Client Heterogeneity
Feb 13, 2026Federated low-rank adaptation (FedLoRA) has facilitated communication-efficient and privacy-preserving fine-tuning of foundation models for downstream tasks. In practical federated learning scenarios, client heterogeneity in system resources and data distributions motivates heterogeneous LoRA ranks across clients. We identify a previously overlooked phenomenon in heterogeneous FedLoRA, termed rank collapse, where the energy of the global update concentrates on the minimum shared rank, resulting in suboptimal performance and high sensitivity to rank configurations. Through theoretical analysis, we reveal the root cause of rank collapse: a mismatch between rank-agnostic aggregation weights and rank-dependent client contributions, which systematically suppresses higher-rank updates at a geometric rate over rounds. Motivated by this insight, we propose raFLoRA, a rank-partitioned aggregation method that decomposes local updates into rank partitions and then aggregates each partition weighted by its effective client contributions. Extensive experiments across classification and reasoning tasks show that raFLoRA prevents rank collapse, improves model performance, and preserves communication efficiency compared to state-of-the-art FedLoRA baselines.
Joint Continual Learning of Local Language Models and Cloud Offloading Decisions with Budget Constraints
Jan 29, 2026Locally deployed Small Language Models (SLMs) must continually support diverse tasks under strict memory and computation constraints, making selective reliance on cloud Large Language Models (LLMs) unavoidable. Regulating cloud assistance during continual learning is challenging, as naive reward-based reinforcement learning often yields unstable offloading behavior and exacerbates catastrophic forgetting as task distributions shift. We propose DA-GRPO, a dual-advantage extension of Group Relative Policy Optimization that incorporates cloud-usage constraints directly into advantage computation, avoiding fixed reward shaping and external routing models. This design enables the local model to jointly learn task competence and collaboration behavior, allowing cloud requests to emerge naturally during post-training while respecting a prescribed assistance budget. Experiments on mathematical reasoning and code generation benchmarks show that DA-GRPO improves post-switch accuracy, substantially reduces forgetting, and maintains stable cloud usage compared to prior collaborative and routing-based approaches.
RCCDA: Adaptive Model Updates in the Presence of Concept Drift under a Constrained Resource Budget
May 30, 2025



Machine learning (ML) algorithms deployed in real-world environments are often faced with the challenge of adapting models to concept drift, where the task data distributions are shifting over time. The problem becomes even more difficult when model performance must be maintained under adherence to strict resource constraints. Existing solutions often depend on drift-detection methods that produce high computational overhead for resource-constrained environments, and fail to provide strict guarantees on resource usage or theoretical performance assurances. To address these shortcomings, we propose RCCDA: a dynamic model update policy that optimizes ML training dynamics while ensuring strict compliance to predefined resource constraints, utilizing only past loss information and a tunable drift threshold. In developing our policy, we analytically characterize the evolution of model loss under concept drift with arbitrary training update decisions. Integrating these results into a Lyapunov drift-plus-penalty framework produces a lightweight policy based on a measurable accumulated loss threshold that provably limits update frequency and cost. Experimental results on three domain generalization datasets demonstrate that our policy outperforms baseline methods in inference accuracy while adhering to strict resource constraints under several schedules of concept drift, making our solution uniquely suited for real-time ML deployments.
Dynamically Learned Test-Time Model Routing in Language Model Zoos with Service Level Guarantees
May 26, 2025Open-weight LLM zoos provide access to numerous high-quality models, but selecting the appropriate model for specific tasks remains challenging and requires technical expertise. Most users simply want factually correct, safe, and satisfying responses without concerning themselves with model technicalities, while inference service providers prioritize minimizing operating costs. These competing interests are typically mediated through service level agreements (SLAs) that guarantee minimum service quality. We introduce MESS+, a stochastic optimization algorithm for cost-optimal LLM request routing while providing rigorous SLA compliance guarantees. MESS+ learns request satisfaction probabilities of LLMs in real-time as users interact with the system, based on which model selection decisions are made by solving a per-request optimization problem. Our algorithm includes a novel combination of virtual queues and request satisfaction prediction, along with a theoretical analysis of cost optimality and constraint satisfaction. Across a wide range of state-of-the-art LLM benchmarks, MESS+ achieves an average of 2x cost savings compared to existing LLM routing techniques.
Memory-Efficient Orthogonal Fine-Tuning with Principal Subspace Adaptation
May 16, 2025Driven by the relentless growth in model parameters, which renders full fine-tuning prohibitively expensive for large-scale deployment, parameter-efficient fine-tuning (PEFT) has emerged as a crucial approach for rapidly adapting large models to a wide range of downstream tasks. Among the PEFT family, orthogonal fine-tuning and its variants have demonstrated remarkable performance by preserving hyperspherical energy, which encodes pairwise angular similarity between neurons. However, these methods are inherently memory-inefficient due to the need to store intermediate activations from multiple full-dimensional sparse matrices. To address this limitation, we propose Memory-efficient Orthogonal Fine-Tuning (MOFT) with principal subspace adaptation. Specifically, we first establish a theoretical condition under which orthogonal transformations within a low-rank subspace preserve hyperspherical energy. Based on this insight, we constrain orthogonal fine-tuning to the principal subspace defined by the top-r components obtained through singular value decomposition and impose an additional constraint on the projection matrix to satisfy the preservation condition. To enhance MOFT's flexibility across tasks, we relax strict orthogonality by introducing two learnable scaling vectors. Extensive experiments on 37 diverse tasks and four models across NLP and CV demonstrate that MOFT consistently outperforms key baselines while significantly reducing the memory footprint of orthogonal fine-tuning.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

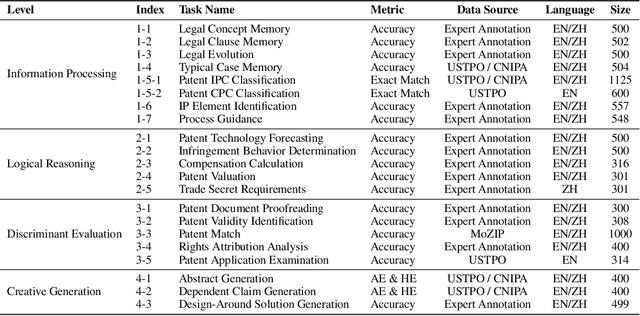
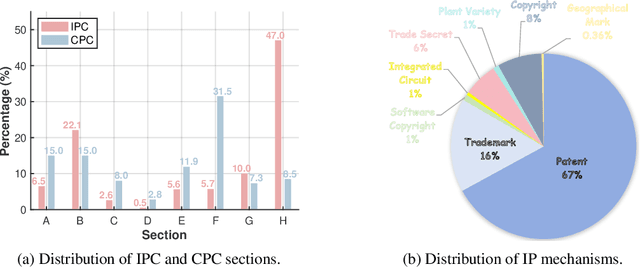
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
GneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025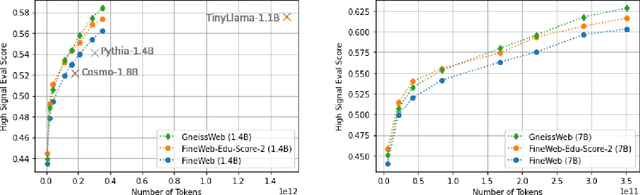
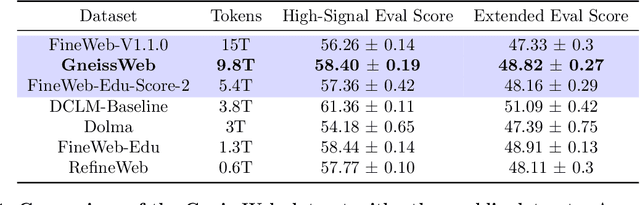
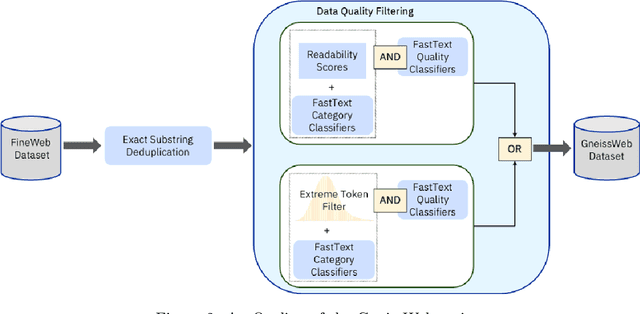

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Dynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining
Feb 10, 2025



Pretraining large language models (LLMs) on vast and heterogeneous datasets is crucial for achieving state-of-the-art performance across diverse downstream tasks. However, current training paradigms treat all samples equally, overlooking the importance or relevance of individual samples throughout the training process. Existing reweighting strategies, which primarily focus on group-level data importance, fail to leverage fine-grained instance-level information and do not adapt dynamically to individual sample importance as training progresses. In this paper, we introduce novel algorithms for dynamic, instance-level data reweighting aimed at improving both the efficiency and effectiveness of LLM pretraining. Our methods adjust the weight of each training sample based on its loss value in an online fashion, allowing the model to dynamically focus on more informative or important samples at the current training stage. In particular, our framework allows us to systematically devise reweighting strategies deprioritizing redundant or uninformative data, which we find tend to work best. Furthermore, we develop a new theoretical framework for analyzing the impact of loss-based reweighting on the convergence of gradient-based optimization, providing the first formal characterization of how these strategies affect convergence bounds. We empirically validate our approach across a spectrum of tasks, from pretraining 7B and 1.4B parameter LLMs to smaller-scale language models and linear regression problems, demonstrating that our loss-based reweighting approach can lead to faster convergence and significantly improved performance.