 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

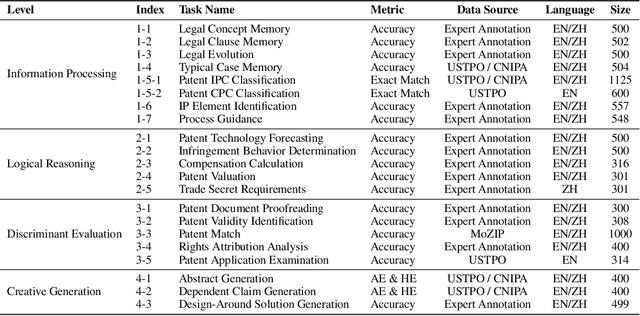
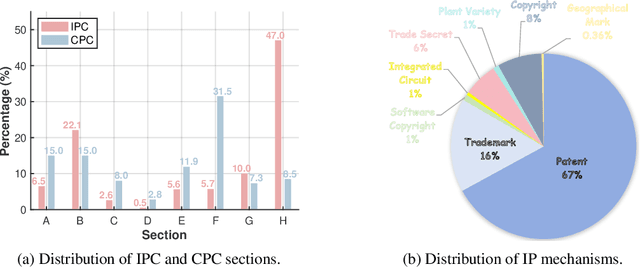
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
Dec 13, 2024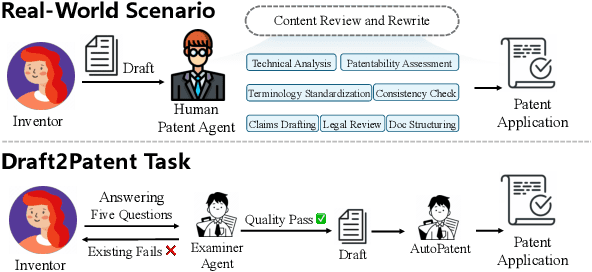
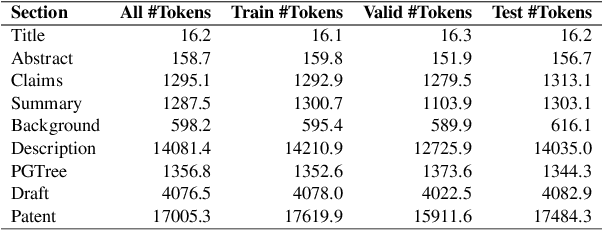
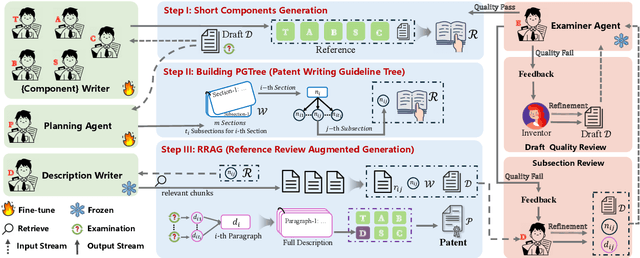
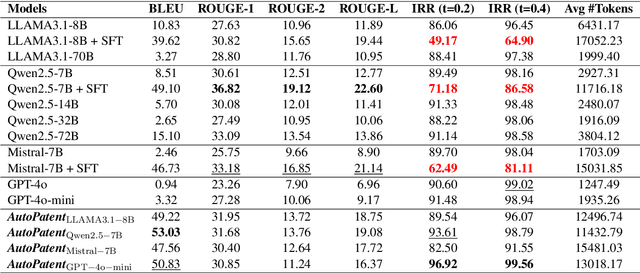
As the capabilities of Large Language Models (LLMs) continue to advance, the field of patent processing has garnered increased attention within the natural language processing community. However, the majority of research has been concentrated on classification tasks, such as patent categorization and examination, or on short text generation tasks like patent summarization and patent quizzes. In this paper, we introduce a novel and practical task known as Draft2Patent, along with its corresponding D2P benchmark, which challenges LLMs to generate full-length patents averaging 17K tokens based on initial drafts. Patents present a significant challenge to LLMs due to their specialized nature, standardized terminology, and extensive length. We propose a multi-agent framework called AutoPatent which leverages the LLM-based planner agent, writer agents, and examiner agent with PGTree and RRAG to generate lengthy, intricate, and high-quality complete patent documents. The experimental results demonstrate that our AutoPatent framework significantly enhances the ability to generate comprehensive patents across various LLMs. Furthermore, we have discovered that patents generated solely with the AutoPatent framework based on the Qwen2.5-7B model outperform those produced by larger and more powerful LLMs, such as GPT-4o, Qwen2.5-72B, and LLAMA3.1-70B, in both objective metrics and human evaluations. We will make the data and code available upon acceptance at \url{https://github.com/QiYao-Wang/AutoPatent}.