 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
GuideWeb: A Benchmark for Automatic In-App Guide Generation on Real-World Web UIs
Feb 02, 2026Digital Adoption Platform (DAP) provide web-based overlays that deliver operation guidance and contextual hints to help users navigate complex websites. Although modern DAP tools enable non-experts to author such guidance, maintaining these guides remains labor-intensive because website layouts and functionalities evolve continuously, which requires repeated manual updates and re-annotation. In this work, we introduce \textbf{GuideWeb}, a new benchmark for automatic in-app guide generation on real-world web UIs. GuideWeb formulates the task as producing page-level guidance by selecting \textbf{guide target elements} grounded in the webpage and generating concise guide text aligned with user intent. We also propose a comprehensive evaluation suite that jointly measures the accuracy of guide target element selection and the quality of generated intents and guide texts. Experiments show that our proposed \textbf{GuideWeb Agent} achieves \textbf{30.79\%} accuracy in guide target element prediction, while obtaining BLEU scores of \textbf{44.94} for intent generation and \textbf{21.34} for guide-text generation. Existing baselines perform substantially worse, which highlights that automatic guide generation remains challenging and that further advances are necessary before such systems can be reliably deployed in real-world settings.
Visual Merit or Linguistic Crutch? A Close Look at DeepSeek-OCR
Jan 08, 2026DeepSeek-OCR utilizes an optical 2D mapping approach to achieve high-ratio vision-text compression, claiming to decode text tokens exceeding ten times the input visual tokens. While this suggests a promising solution for the LLM long-context bottleneck, we investigate a critical question: "Visual merit or linguistic crutch - which drives DeepSeek-OCR's performance?" By employing sentence-level and word-level semantic corruption, we isolate the model's intrinsic OCR capabilities from its language priors. Results demonstrate that without linguistic support, DeepSeek-OCR's performance plummets from approximately 90% to 20%. Comparative benchmarking against 13 baseline models reveals that traditional pipeline OCR methods exhibit significantly higher robustness to such semantic perturbations than end-to-end methods. Furthermore, we find that lower visual token counts correlate with increased reliance on priors, exacerbating hallucination risks. Context stress testing also reveals a total model collapse around 10,000 text tokens, suggesting that current optical compression techniques may paradoxically aggravate the long-context bottleneck. This study empirically defines DeepSeek-OCR's capability boundaries and offers essential insights for future optimizations of the vision-text compression paradigm. We release all data, results and scripts used in this study at https://github.com/dududuck00/DeepSeekOCR.
Automatic Paper Reviewing with Heterogeneous Graph Reasoning over LLM-Simulated Reviewer-Author Debates
Nov 11, 2025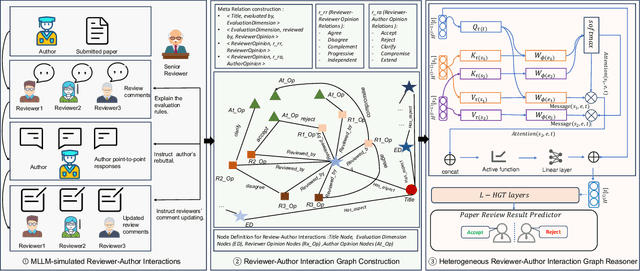
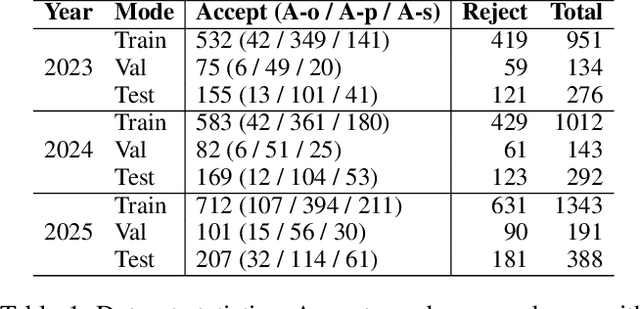
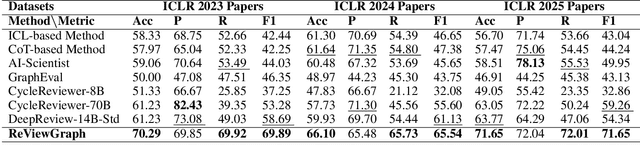
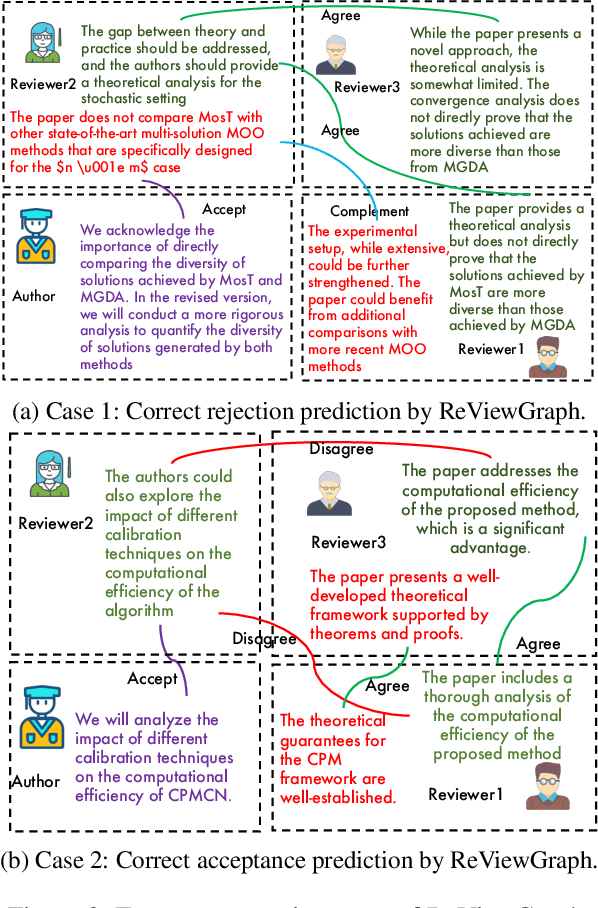
Existing paper review methods often rely on superficial manuscript features or directly on large language models (LLMs), which are prone to hallucinations, biased scoring, and limited reasoning capabilities. Moreover, these methods often fail to capture the complex argumentative reasoning and negotiation dynamics inherent in reviewer-author interactions. To address these limitations, we propose ReViewGraph (Reviewer-Author Debates Graph Reasoner), a novel framework that performs heterogeneous graph reasoning over LLM-simulated multi-round reviewer-author debates. In our approach, reviewer-author exchanges are simulated through LLM-based multi-agent collaboration. Diverse opinion relations (e.g., acceptance, rejection, clarification, and compromise) are then explicitly extracted and encoded as typed edges within a heterogeneous interaction graph. By applying graph neural networks to reason over these structured debate graphs, ReViewGraph captures fine-grained argumentative dynamics and enables more informed review decisions. Extensive experiments on three datasets demonstrate that ReViewGraph outperforms strong baselines with an average relative improvement of 15.73%, underscoring the value of modeling detailed reviewer-author debate structures.
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025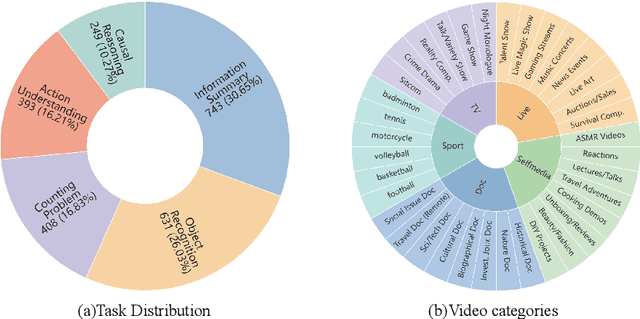



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
M-MRE: Extending the Mutual Reinforcement Effect to Multimodal Information Extraction
Apr 24, 2025Mutual Reinforcement Effect (MRE) is an emerging subfield at the intersection of information extraction and model interpretability. MRE aims to leverage the mutual understanding between tasks of different granularities, enhancing the performance of both coarse-grained and fine-grained tasks through joint modeling. While MRE has been explored and validated in the textual domain, its applicability to visual and multimodal domains remains unexplored. In this work, we extend MRE to the multimodal information extraction domain for the first time. Specifically, we introduce a new task: Multimodal Mutual Reinforcement Effect (M-MRE), and construct a corresponding dataset to support this task. To address the challenges posed by M-MRE, we further propose a Prompt Format Adapter (PFA) that is fully compatible with various Large Vision-Language Models (LVLMs). Experimental results demonstrate that MRE can also be observed in the M-MRE task, a multimodal text-image understanding scenario. This provides strong evidence that MRE facilitates mutual gains across three interrelated tasks, confirming its generalizability beyond the textual domain.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

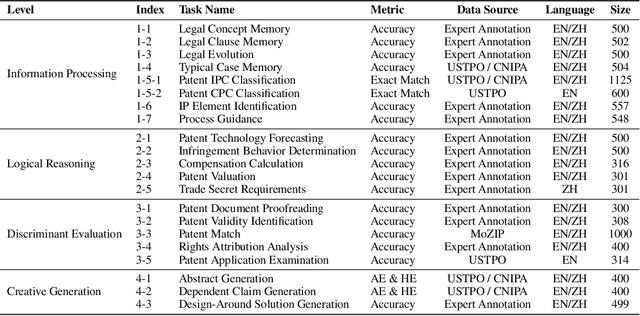
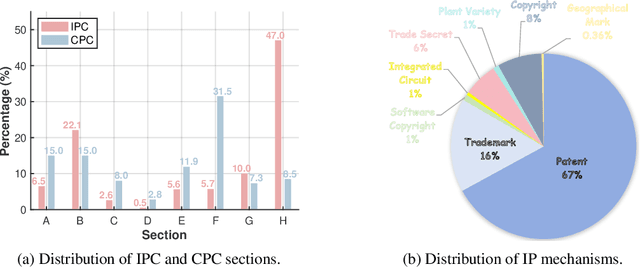
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Jan 30, 2025



Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model's internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack's effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.