 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnemoi: A Semi-Centralized Multi-agent Systems Based on Agent-to-Agent Communication MCP server from Coral Protocol
Aug 23, 2025Recent advances in generalist multi-agent systems (MAS) have largely followed a context-engineering plus centralized paradigm, where a planner agent coordinates multiple worker agents through unidirectional prompt passing. While effective under strong planner models, this design suffers from two critical limitations: (1) strong dependency on the planner's capability, which leads to degraded performance when a smaller LLM powers the planner; and (2) limited inter-agent communication, where collaboration relies on costly prompt concatenation and context injection, introducing redundancy and information loss. To address these challenges, we propose Anemoi, a semi-centralized MAS built on the Agent-to-Agent (A2A) communication MCP server from Coral Protocol. Unlike traditional designs, Anemoi enables structured and direct inter-agent collaboration, allowing all agents to monitor progress, assess results, identify bottlenecks, and propose refinements in real time. This paradigm reduces reliance on a single planner, supports adaptive plan updates, and minimizes redundant context passing, resulting in more scalable and cost-efficient execution. Evaluated on the GAIA benchmark, Anemoi achieved 52.73\% accuracy with a small LLM (GPT-4.1-mini) as the planner, surpassing the strongest open-source baseline OWL (43.63\%) by +9.09\% under identical LLM settings. Our implementation is publicly available at https://github.com/Coral-Protocol/Anemoi.
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025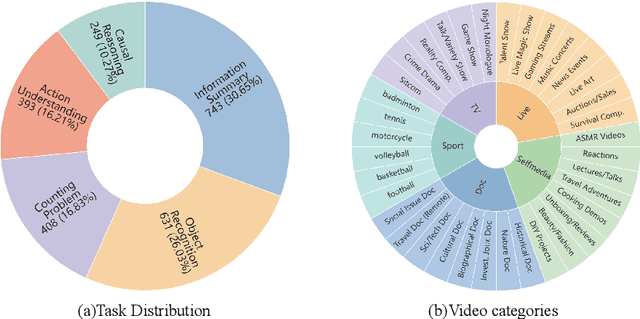



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
KG-HTC: Integrating Knowledge Graphs into LLMs for Effective Zero-shot Hierarchical Text Classification
May 08, 2025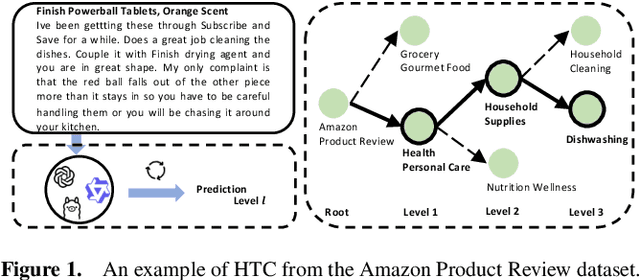

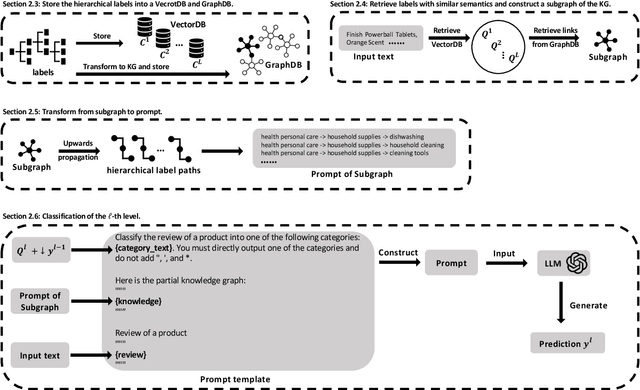
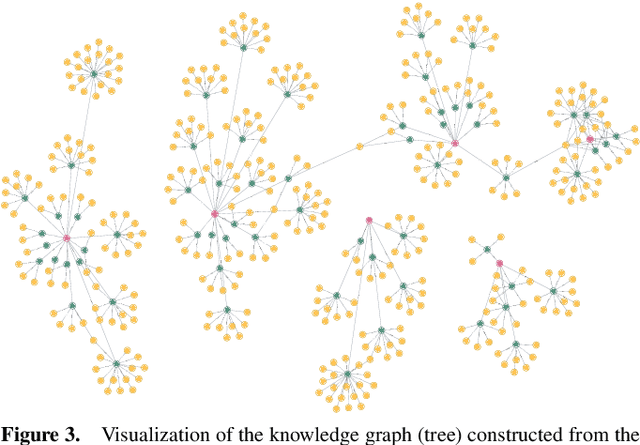
Hierarchical Text Classification (HTC) involves assigning documents to labels organized within a taxonomy. Most previous research on HTC has focused on supervised methods. However, in real-world scenarios, employing supervised HTC can be challenging due to a lack of annotated data. Moreover, HTC often faces issues with large label spaces and long-tail distributions. In this work, we present Knowledge Graphs for zero-shot Hierarchical Text Classification (KG-HTC), which aims to address these challenges of HTC in applications by integrating knowledge graphs with Large Language Models (LLMs) to provide structured semantic context during classification. Our method retrieves relevant subgraphs from knowledge graphs related to the input text using a Retrieval-Augmented Generation (RAG) approach. Our KG-HTC can enhance LLMs to understand label semantics at various hierarchy levels. We evaluate KG-HTC on three open-source HTC datasets: WoS, DBpedia, and Amazon. Our experimental results show that KG-HTC significantly outperforms three baselines in the strict zero-shot setting, particularly achieving substantial improvements at deeper levels of the hierarchy. This evaluation demonstrates the effectiveness of incorporating structured knowledge into LLMs to address HTC's challenges in large label spaces and long-tailed label distributions. Our code is available at: https://github.com/QianboZang/KG-HTC.
AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
Oct 29, 2024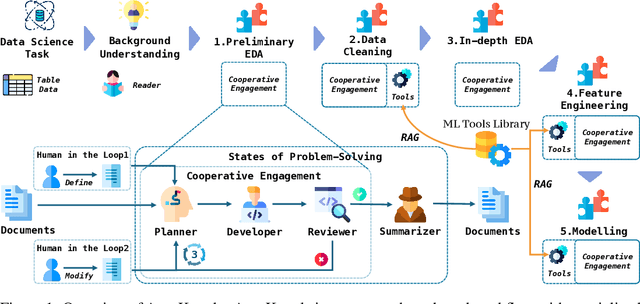
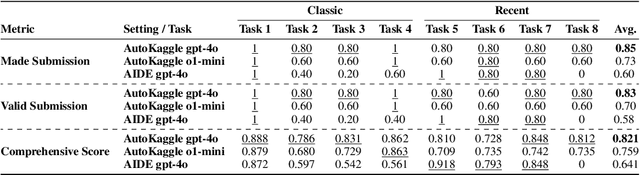
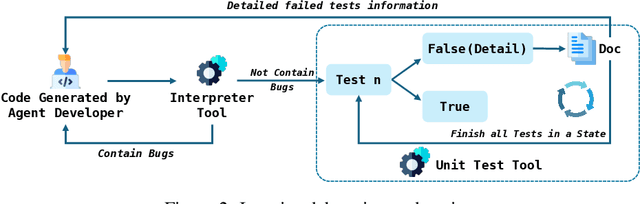
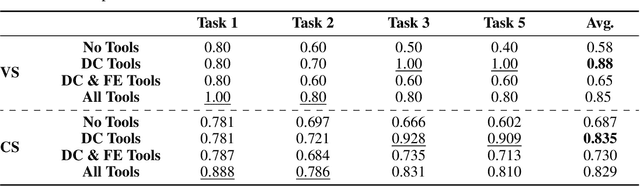
Data science tasks involving tabular data present complex challenges that require sophisticated problem-solving approaches. We propose AutoKaggle, a powerful and user-centric framework that assists data scientists in completing daily data pipelines through a collaborative multi-agent system. AutoKaggle implements an iterative development process that combines code execution, debugging, and comprehensive unit testing to ensure code correctness and logic consistency. The framework offers highly customizable workflows, allowing users to intervene at each phase, thus integrating automated intelligence with human expertise. Our universal data science toolkit, comprising validated functions for data cleaning, feature engineering, and modeling, forms the foundation of this solution, enhancing productivity by streamlining common tasks. We selected 8 Kaggle competitions to simulate data processing workflows in real-world application scenarios. Evaluation results demonstrate that AutoKaggle achieves a validation submission rate of 0.85 and a comprehensive score of 0.82 in typical data science pipelines, fully proving its effectiveness and practicality in handling complex data science tasks.
LIME-M: Less Is More for Evaluation of MLLMs
Sep 10, 2024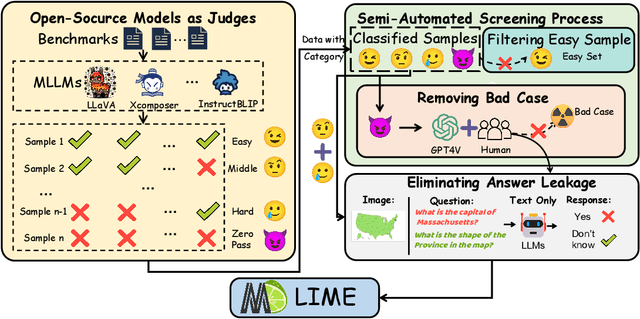
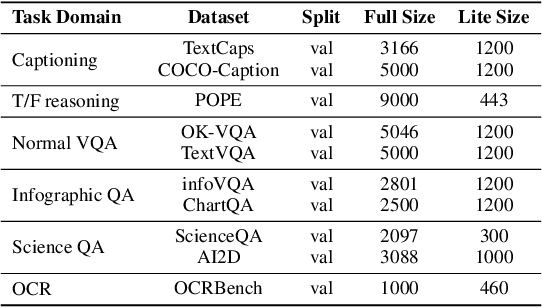
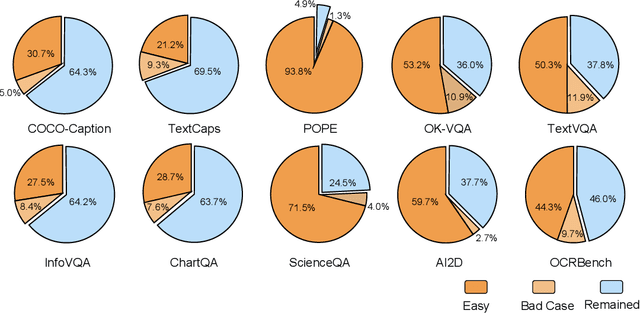
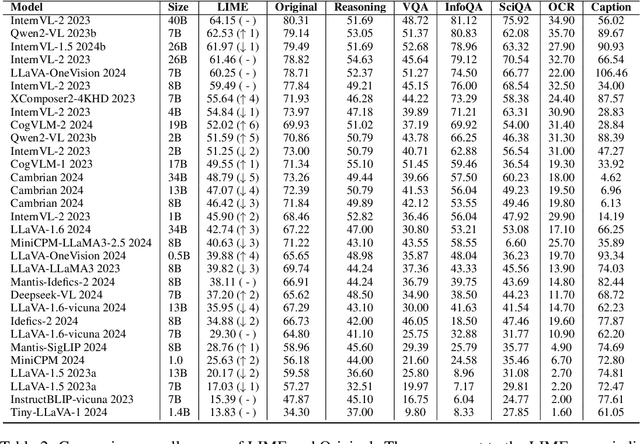
With the remarkable success achieved by Multimodal Large Language Models (MLLMs), numerous benchmarks have been designed to assess MLLMs' ability to guide their development in image perception tasks (e.g., image captioning and visual question answering). However, the existence of numerous benchmarks results in a substantial computational burden when evaluating model performance across all of them. Moreover, these benchmarks contain many overly simple problems or challenging samples, which do not effectively differentiate the capabilities among various MLLMs. To address these challenges, we propose a pipeline to process the existing benchmarks, which consists of two modules: (1) Semi-Automated Screening Process and (2) Eliminating Answer Leakage. The Semi-Automated Screening Process filters out samples that cannot distinguish the model's capabilities by synthesizing various MLLMs and manually evaluating them. The Eliminate Answer Leakage module filters samples whose answers can be inferred without images. Finally, we curate the LIME-M: Less Is More for Evaluation of Multimodal LLMs, a lightweight Multimodal benchmark that can more effectively evaluate the performance of different models. Our experiments demonstrate that: LIME-M can better distinguish the performance of different MLLMs with fewer samples (24% of the original) and reduced time (23% of the original); LIME-M eliminates answer leakage, focusing mainly on the information within images; The current automatic metric (i.e., CIDEr) is insufficient for evaluating MLLMs' capabilities in captioning. Moreover, removing the caption task score when calculating the overall score provides a more accurate reflection of model performance differences. All our codes and data are released at https://github.com/kangreen0210/LIME-M.