 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding DeepResearch via Reports
Oct 09, 2025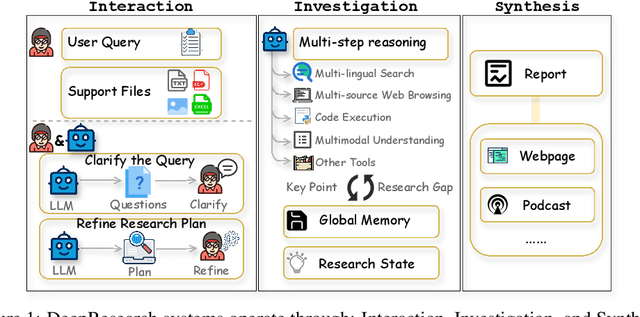

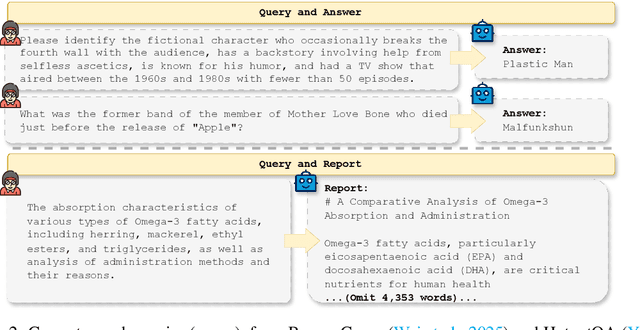

DeepResearch agents represent a transformative AI paradigm, conducting expert-level research through sophisticated reasoning and multi-tool integration. However, evaluating these systems remains critically challenging due to open-ended research scenarios and existing benchmarks that focus on isolated capabilities rather than holistic performance. Unlike traditional LLM tasks, DeepResearch systems must synthesize diverse sources, generate insights, and present coherent findings, which are capabilities that resist simple verification. To address this gap, we introduce DeepResearch-ReportEval, a comprehensive framework designed to assess DeepResearch systems through their most representative outputs: research reports. Our approach systematically measures three dimensions: quality, redundancy, and factuality, using an innovative LLM-as-a-Judge methodology achieving strong expert concordance. We contribute a standardized benchmark of 100 curated queries spanning 12 real-world categories, enabling systematic capability comparison. Our evaluation of four leading commercial systems reveals distinct design philosophies and performance trade-offs, establishing foundational insights as DeepResearch evolves from information assistants toward intelligent research partners. Source code and data are available at: https://github.com/HKUDS/DeepResearch-Eval.
A$^2$Search: Ambiguity-Aware Question Answering with Reinforcement Learning
Oct 09, 2025



Recent advances in Large Language Models (LLMs) and Reinforcement Learning (RL) have led to strong performance in open-domain question answering (QA). However, existing models still struggle with questions that admit multiple valid answers. Standard QA benchmarks, which typically assume a single gold answer, overlook this reality and thus produce inappropriate training signals. Existing attempts to handle ambiguity often rely on costly manual annotation, which is difficult to scale to multi-hop datasets such as HotpotQA and MuSiQue. In this paper, we present A$^2$Search, an annotation-free, end-to-end training framework to recognize and handle ambiguity. At its core is an automated pipeline that detects ambiguous questions and gathers alternative answers via trajectory sampling and evidence verification. The model is then optimized with RL using a carefully designed $\mathrm{AnsF1}$ reward, which naturally accommodates multiple answers. Experiments on eight open-domain QA benchmarks demonstrate that A$^2$Search achieves new state-of-the-art performance. With only a single rollout, A$^2$Search-7B yields an average $\mathrm{AnsF1}@1$ score of $48.4\%$ across four multi-hop benchmarks, outperforming all strong baselines, including the substantially larger ReSearch-32B ($46.2\%$). Extensive analyses further show that A$^2$Search resolves ambiguity and generalizes across benchmarks, highlighting that embracing ambiguity is essential for building more reliable QA systems. Our code, data, and model weights can be found at https://github.com/zfj1998/A2Search
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
Oct 29, 2024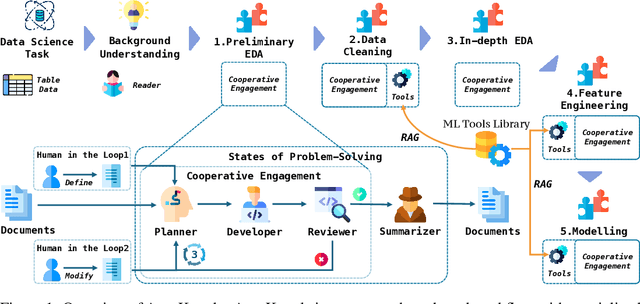
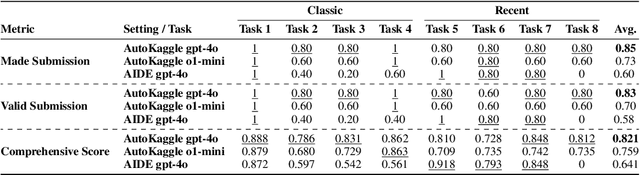
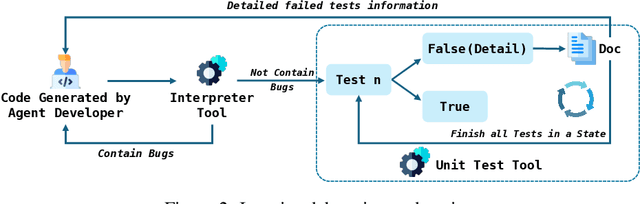
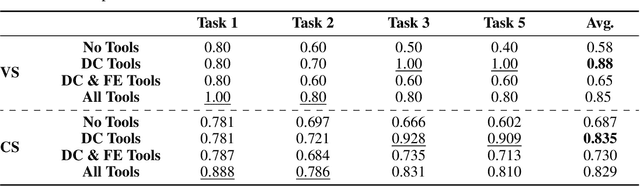
Data science tasks involving tabular data present complex challenges that require sophisticated problem-solving approaches. We propose AutoKaggle, a powerful and user-centric framework that assists data scientists in completing daily data pipelines through a collaborative multi-agent system. AutoKaggle implements an iterative development process that combines code execution, debugging, and comprehensive unit testing to ensure code correctness and logic consistency. The framework offers highly customizable workflows, allowing users to intervene at each phase, thus integrating automated intelligence with human expertise. Our universal data science toolkit, comprising validated functions for data cleaning, feature engineering, and modeling, forms the foundation of this solution, enhancing productivity by streamlining common tasks. We selected 8 Kaggle competitions to simulate data processing workflows in real-world application scenarios. Evaluation results demonstrate that AutoKaggle achieves a validation submission rate of 0.85 and a comprehensive score of 0.82 in typical data science pipelines, fully proving its effectiveness and practicality in handling complex data science tasks.
Aria: An Open Multimodal Native Mixture-of-Experts Model
Oct 08, 2024
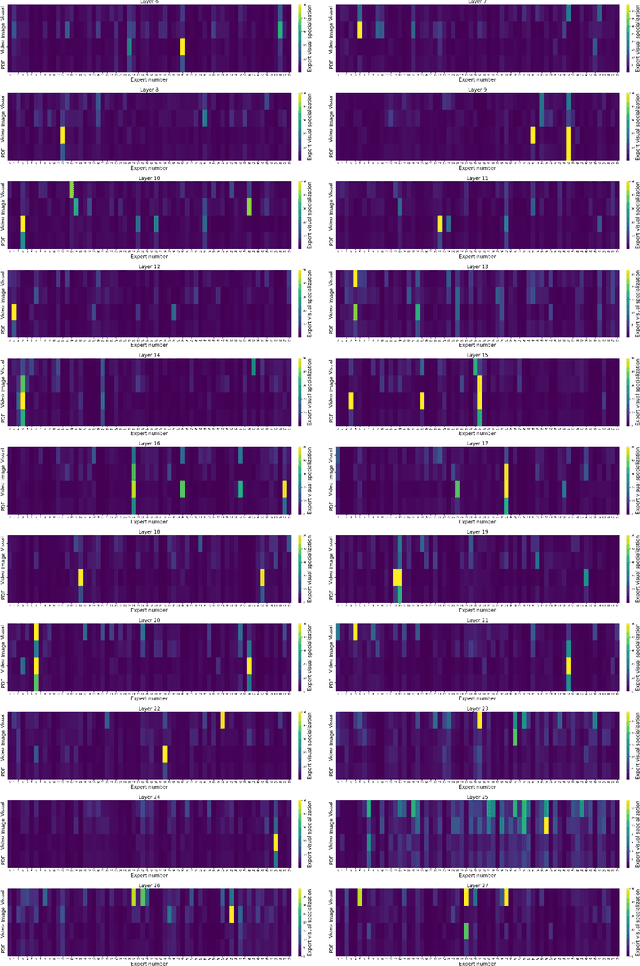


Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations. To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively. It outperforms Pixtral-12B and Llama3.2-11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following. We open-source the model weights along with a codebase that facilitates easy adoptions and adaptations of Aria in real-world applications.
The Fine Line: Navigating Large Language Model Pretraining with Down-streaming Capability Analysis
Apr 01, 2024



Uncovering early-stage metrics that reflect final model performance is one core principle for large-scale pretraining. The existing scaling law demonstrates the power-law correlation between pretraining loss and training flops, which serves as an important indicator of the current training state for large language models. However, this principle only focuses on the model's compression properties on the training data, resulting in an inconsistency with the ability improvements on the downstream tasks. Some follow-up works attempted to extend the scaling-law to more complex metrics (such as hyperparameters), but still lacked a comprehensive analysis of the dynamic differences among various capabilities during pretraining. To address the aforementioned limitations, this paper undertakes a comprehensive comparison of model capabilities at various pretraining intermediate checkpoints. Through this analysis, we confirm that specific downstream metrics exhibit similar training dynamics across models of different sizes, up to 67 billion parameters. In addition to our core findings, we've reproduced Amber and OpenLLaMA, releasing their intermediate checkpoints. This initiative offers valuable resources to the research community and facilitates the verification and exploration of LLM pretraining by open-source researchers. Besides, we provide empirical summaries, including performance comparisons of different models and capabilities, and tuition of key metrics for different training phases. Based on these findings, we provide a more user-friendly strategy for evaluating the optimization state, offering guidance for establishing a stable pretraining process.
Yi: Open Foundation Models by 01.AI
Mar 07, 2024



We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
Machine Unlearning of Pre-trained Large Language Models
Feb 27, 2024This study investigates the concept of the `right to be forgotten' within the context of large language models (LLMs). We explore machine unlearning as a pivotal solution, with a focus on pre-trained models--a notably under-researched area. Our research delineates a comprehensive framework for machine unlearning in pre-trained LLMs, encompassing a critical analysis of seven diverse unlearning methods. Through rigorous evaluation using curated datasets from arXiv, books, and GitHub, we establish a robust benchmark for unlearning performance, demonstrating that these methods are over $10^5$ times more computationally efficient than retraining. Our results show that integrating gradient ascent with gradient descent on in-distribution data improves hyperparameter robustness. We also provide detailed guidelines for efficient hyperparameter tuning in the unlearning process. Our findings advance the discourse on ethical AI practices, offering substantive insights into the mechanics of machine unlearning for pre-trained LLMs and underscoring the potential for responsible AI development.
Data Engineering for Scaling Language Models to 128K Context
Feb 15, 2024We study the continual pretraining recipe for scaling language models' context lengths to 128K, with a focus on data engineering. We hypothesize that long context modeling, in particular \textit{the ability to utilize information at arbitrary input locations}, is a capability that is mostly already acquired through large-scale pretraining, and that this capability can be readily extended to contexts substantially longer than seen during training~(e.g., 4K to 128K) through lightweight continual pretraining on appropriate data mixture. We investigate the \textit{quantity} and \textit{quality} of the data for continual pretraining: (1) for quantity, we show that 500 million to 5 billion tokens are enough to enable the model to retrieve information anywhere within the 128K context; (2) for quality, our results equally emphasize \textit{domain balance} and \textit{length upsampling}. Concretely, we find that naively upsampling longer data on certain domains like books, a common practice of existing work, gives suboptimal performance, and that a balanced domain mixture is important. We demonstrate that continual pretraining of the full model on 1B-5B tokens of such data is an effective and affordable strategy for scaling the context length of language models to 128K. Our recipe outperforms strong open-source long-context models and closes the gap to frontier models like GPT-4 128K.