 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen No Answer Is Correct: Diagnosing Absent Answer Detection for MLLMs in Video Understanding
Jun 06, 2026Multimodal large language models (MLLMs) have made substantial advancements in video understanding, yet the reliability of their responses remains underexplored. This work presents a diagnostic study of absent answer detection for MLLMs in video understanding, where the correct answer is deliberately excluded from the candidate set and a reliable model is expected to recognize that no valid option exists. We evaluate the absent answer detection behavior under three settings: multiple-choice questions augmented with an ``None of the Above'' option, open-ended generation with a detection instruction, and standard evaluation without any guidance. Across a diverse set of models and benchmarks, we find that MLLMs overwhelmingly select plausible distractors rather than detecting the absent answer. This failure is more pronounced in temporal reasoning tasks and worsens with denser frame sampling. We further explore chain-of-thought prompting as a mitigation strategy and find that while it substantially improves detection rates, performance remains unsatisfactory, suggesting that prompting-based strategies alone are insufficient to fully address this limitation. These findings expose a systematic failure in absent answer detection and highlight the need for explicit detection mechanisms in multimodal systems.
Latent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
May 04, 2026Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
Query-Conditioned Evidential Keyframe Sampling for MLLM-Based Long-Form Video Understanding
Apr 01, 2026Multimodal Large Language Models (MLLMs) have shown strong performance on video question answering, but their application to long-form videos is constrained by limited context length and computational cost, making keyframe sampling essential. Existing approaches typically rely on semantic relevance or reinforcement learning, which either fail to capture evidential clues or suffer from inefficient combinatorial optimization. In this work, we propose an evidence-driven keyframe sampling framework grounded in information bottleneck theory. We formulate keyframe selection as maximizing the conditional mutual information between selected frames and the query, providing a principled objective that reflects each frame's contribution to answering the question. To make this objective tractable, we exploit its structure to derive a decomposed optimization that reduces subset selection to independent frame-level scoring. We further introduce a query-conditioned evidence scoring network trained with a contrastive objective to estimate evidential importance efficiently. Experiments on long-form video understanding benchmarks show that our method consistently outperforms prior sampling strategies under strict token budgets, while significantly improving training efficiency.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025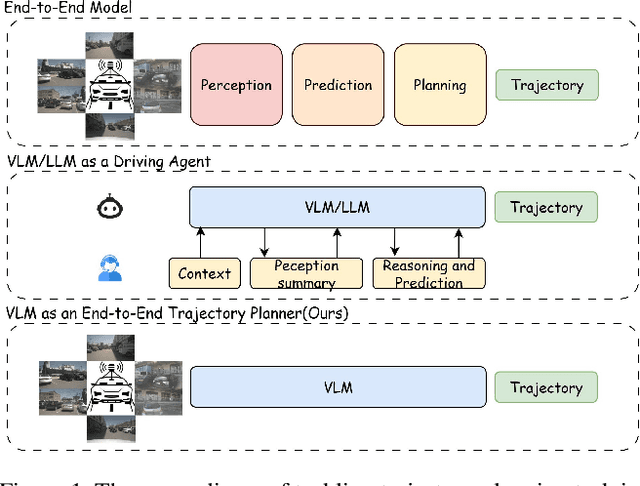
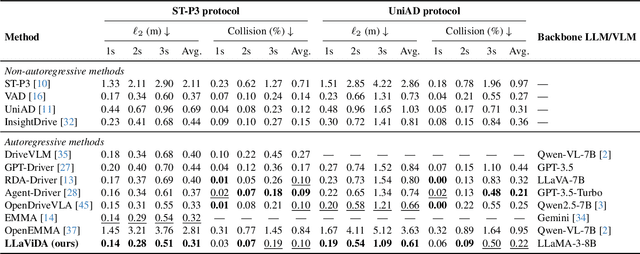
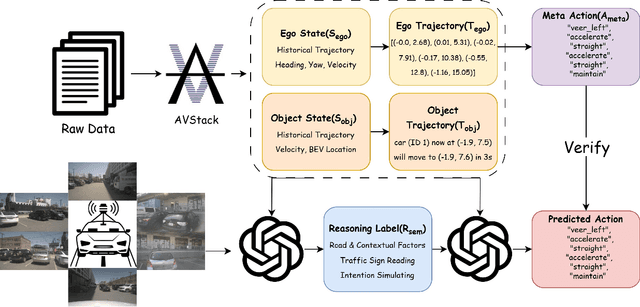
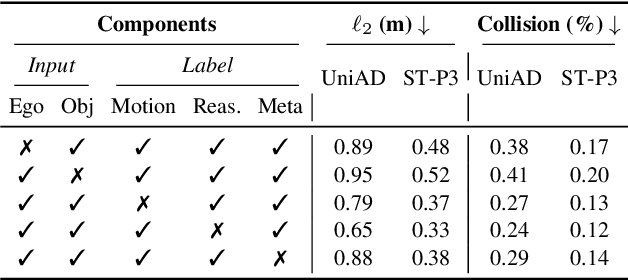
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.
CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models
May 25, 2025Vision-Language Models (VLMs) excel across diverse tasks but suffer from high inference costs in time and memory. Token sparsity mitigates inefficiencies in token usage, while neuron sparsity reduces high-dimensional computations, both offering promising solutions to enhance efficiency. Recently, these two sparsity paradigms have evolved largely in parallel, fostering the prevailing assumption that they function independently. However, a fundamental yet underexplored question remains: Do they truly operate in isolation, or is there a deeper underlying interplay that has yet to be uncovered? In this paper, we conduct the first comprehensive investigation into this question. By introducing and analyzing the matching mechanism between Core Neurons and Core Tokens, we found that key neurons and tokens for inference mutually influence and reinforce each other. Building on this insight, we propose CoreMatching, a co-adaptive sparse inference framework, which leverages the synergy between token and neuron sparsity to enhance inference efficiency. Through theoretical analysis and efficiency evaluations, we demonstrate that the proposed method surpasses state-of-the-art baselines on ten image understanding tasks and three hardware devices. Notably, on the NVIDIA Titan Xp, it achieved 5x FLOPs reduction and a 10x overall speedup. Code is released at https://github.com/wangqinsi1/2025-ICML-CoreMatching/tree/main.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Keyframe-oriented Vision Token Pruning: Enhancing Efficiency of Large Vision Language Models on Long-Form Video Processing
Mar 13, 2025Vision language models (VLMs) demonstrate strong capabilities in jointly processing visual and textual data. However, they often incur substantial computational overhead due to redundant visual information, particularly in long-form video scenarios. Existing approaches predominantly focus on either vision token pruning, which may overlook spatio-temporal dependencies, or keyframe selection, which identifies informative frames but discards others, thus disrupting contextual continuity. In this work, we propose KVTP (Keyframe-oriented Vision Token Pruning), a novel framework that overcomes the drawbacks of token pruning and keyframe selection. By adaptively assigning pruning rates based on frame relevance to the query, KVTP effectively retains essential contextual information while significantly reducing redundant computation. To thoroughly evaluate the long-form video understanding capacities of VLMs, we curated and reorganized subsets from VideoMME, EgoSchema, and NextQA into a unified benchmark named SparseKV-QA that highlights real-world scenarios with sparse but crucial events. Our experiments with VLMs of various scales show that KVTP can reduce token usage by 80% without compromising spatiotemporal and contextual consistency, significantly cutting computation while maintaining the performance. These results demonstrate our approach's effectiveness in efficient long-video processing, facilitating more scalable VLM deployment.
SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval
Dec 16, 2024We introduce Speech Information Retrieval (SIR), a new long-context task for Speech Large Language Models (Speech LLMs), and present SPIRAL, a 1,012-sample benchmark testing models' ability to extract critical details from approximately 90-second spoken inputs. While current Speech LLMs excel at short-form tasks, they struggle with the computational and representational demands of longer audio sequences. To address this limitation, we propose SpeechPrune, a training-free token pruning strategy that uses speech-text similarity and approximated attention scores to efficiently discard irrelevant tokens. In SPIRAL, SpeechPrune achieves accuracy improvements of 29% and up to 47% over the original model and the random pruning model at a pruning rate of 20%, respectively. SpeechPrune can maintain network performance even at a pruning level of 80%. This approach highlights the potential of token-level pruning for efficient and scalable long-form speech understanding.
Towards Automated Model Design on Recommender Systems
Nov 12, 2024The increasing popularity of deep learning models has created new opportunities for developing AI-based recommender systems. Designing recommender systems using deep neural networks requires careful architecture design, and further optimization demands extensive co-design efforts on jointly optimizing model architecture and hardware. Design automation, such as Automated Machine Learning (AutoML), is necessary to fully exploit the potential of recommender model design, including model choices and model-hardware co-design strategies. We introduce a novel paradigm that utilizes weight sharing to explore abundant solution spaces. Our paradigm creates a large supernet to search for optimal architectures and co-design strategies to address the challenges of data multi-modality and heterogeneity in the recommendation domain. From a model perspective, the supernet includes a variety of operators, dense connectivity, and dimension search options. From a co-design perspective, it encompasses versatile Processing-In-Memory (PIM) configurations to produce hardware-efficient models. Our solution space's scale, heterogeneity, and complexity pose several challenges, which we address by proposing various techniques for training and evaluating the supernet. Our crafted models show promising results on three Click-Through Rates (CTR) prediction benchmarks, outperforming both manually designed and AutoML-crafted models with state-of-the-art performance when focusing solely on architecture search. From a co-design perspective, we achieve 2x FLOPs efficiency, 1.8x energy efficiency, and 1.5x performance improvements in recommender models.
* Accepted in ACM Transactions on Recommender Systems. arXiv admin note: substantial text overlap with arXiv:2207.07187