 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Cultural Awareness in LLMs: A Case Study of Cross-Culture Aesthetic Stylistics
May 26, 2026Large Language Models (LLMs) are increasingly deployed in diverse cultural contexts, yet their ability to master aesthetic stylistics, i.e., the strategic use of language to evoke cultural resonance, remains underexplored. We curate C4STYLI, a benchmark of highly stylized translated movie titles and advertising slogans from Hong Kong and the Chinese Mainland, to evaluate LLMs via the lens of behavioral recognition and productive competence. Extensive evaluations show that LLMs differ from humans in stylistic recognition, and this recognition ability varies across text domains. In addition, stylistic recognition and generation performance in LLMs are not consistently aligned. To further examine whether LLMs genuinely capture stylistic information in stylistic recognition, we conduct structural ablation with logistic regression probes. We find that, in the Hong Kong setting, stylistic recognition in LLMs relies primarily on surface-level linguistic information rather than stylistic structure. This suggests limited sensitivity to Hong Kong-specific stylistic structure.
Foresight Optimization for Strategic Reasoning in Large Language Models
Apr 16, 2026Reasoning capabilities in large language models (LLMs) have generally advanced significantly. However, it is still challenging for existing reasoning-based LLMs to perform effective decision-making abilities in multi-agent environments, due to the absence of explicit foresight modeling. To this end, strategic reasoning, the most fundamental capability to anticipate the counterpart's behaviors and foresee its possible future actions, has been introduced to alleviate the above issues. Strategic reasoning is fundamental to effective decision-making in multi-agent environments, yet existing reasoning enhancement methods for LLMs do not explicitly capture its foresight nature. In this work, we introduce Foresight Policy Optimization (FoPO) to enhance strategic reasoning in LLMs, which integrates opponent modeling principles into policy optimization, thereby enabling explicit consideration of both self-interest and counterpart influence. Specifically, we construct two curated datasets, namely Cooperative RSA and Competitive Taboo, equipped with well-designed rules and moderate difficulty to facilitate a systematic investigation of FoPO in a self-play framework. Our experiments demonstrate that FoPO significantly enhances strategic reasoning across LLMs of varying sizes and origins. Moreover, models trained with FoPO exhibit strong generalization to out-of-domain strategic scenarios, substantially outperforming standard LLM reasoning optimization baselines.
HiVLA: A Visual-Grounded-Centric Hierarchical Embodied Manipulation System
Apr 15, 2026While end-to-end Vision-Language-Action (VLA) models offer a promising paradigm for robotic manipulation, fine-tuning them on narrow control data often compromises the profound reasoning capabilities inherited from their base Vision-Language Models (VLMs). To resolve this fundamental trade-off, we propose HiVLA, a visual-grounded-centric hierarchical framework that explicitly decouples high-level semantic planning from low-level motor control. In high-level part, a VLM planner first performs task decomposition and visual grounding to generate structured plans, comprising a subtask instruction and a precise target bounding box. Then, to translate this plan into physical actions, we introduce a flow-matching Diffusion Transformer (DiT) action expert in low-level part equipped with a novel cascaded cross-attention mechanism. This design sequentially fuses global context, high-resolution object-centric crops and skill semantics, enabling the DiT to focus purely on robust execution. Our decoupled architecture preserves the VLM's zero-shot reasoning while allowing independent improvement of both components. Extensive experiments in simulation and the real world demonstrate that HiVLA significantly outperforms state-of-the-art end-to-end baselines, particularly excelling in long-horizon skill composition and the fine-grained manipulation of small objects in cluttered scenes.
Enhancing User Engagement in Socially-Driven Dialogue through Interactive LLM Alignments
Jun 26, 2025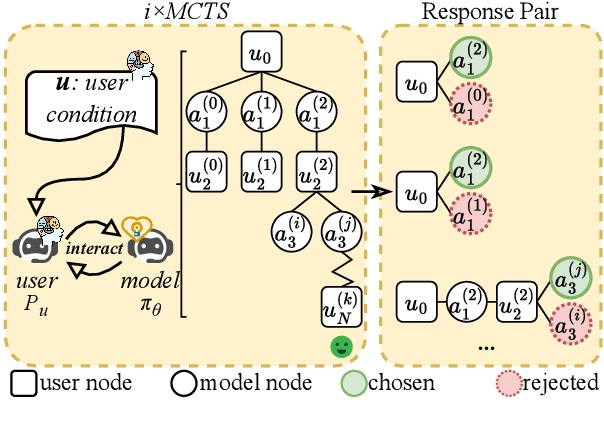

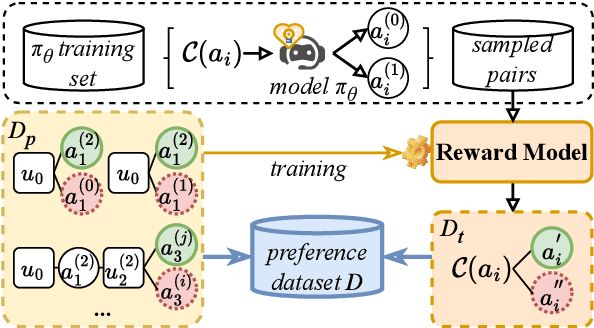

Enhancing user engagement through interactions plays an essential role in socially-driven dialogues. While prior works have optimized models to reason over relevant knowledge or plan a dialogue act flow, the relationship between user engagement and knowledge or dialogue acts is subtle and does not guarantee user engagement in socially-driven dialogues. To this end, we enable interactive LLMs to learn user engagement by leveraging signals from the future development of conversations. Specifically, we adopt a more direct and relevant indicator of user engagement, i.e., the user's reaction related to dialogue intention after the interaction, as a reward to align interactive LLMs. To achieve this, we develop a user simulator to interact with target interactive LLMs and explore interactions between the user and the interactive LLM system via \textit{i$\times$MCTS} (\textit{M}onte \textit{C}arlo \textit{T}ree \textit{S}earch for \textit{i}nteraction). In this way, we collect a dataset containing pairs of higher and lower-quality experiences using \textit{i$\times$MCTS}, and align interactive LLMs for high-level user engagement by direct preference optimization (DPO) accordingly. Experiments conducted on two socially-driven dialogue scenarios (emotional support conversations and persuasion for good) demonstrate that our method effectively enhances user engagement in interactive LLMs.
LIMOPro: Reasoning Refinement for Efficient and Effective Test-time Scaling
May 25, 2025Large language models (LLMs) have demonstrated remarkable reasoning capabilities through test-time scaling approaches, particularly when fine-tuned with chain-of-thought (CoT) data distilled from more powerful large reasoning models (LRMs). However, these reasoning chains often contain verbose elements that mirror human problem-solving, categorized as progressive reasoning (the essential solution development path) and functional elements (verification processes, alternative solution approaches, and error corrections). While progressive reasoning is crucial, the functional elements significantly increase computational demands during test-time inference. We introduce PIR (Perplexity-based Importance Refinement), a principled framework that quantitatively evaluates the importance of each reasoning step based on its impact on answer prediction confidence. PIR systematically identifies and selectively prunes only low-importance functional steps while preserving progressive reasoning components, creating optimized training data that maintains the integrity of the core solution path while reducing verbosity. Models fine-tuned on PIR-optimized data exhibit superior test-time scaling properties, generating more concise reasoning chains while achieving improved accuracy (+0.9\% to +6.6\%) with significantly reduced token usage (-3\% to -41\%) across challenging reasoning benchmarks (AIME, AMC, and GPQA Diamond). Our approach demonstrates strong generalizability across different model sizes, data sources, and token budgets, offering a practical solution for deploying reasoning-capable LLMs in scenarios where efficient test-time scaling, response time, and computational efficiency are valuable constraints.
Towards Dynamic Theory of Mind: Evaluating LLM Adaptation to Temporal Evolution of Human States
May 23, 2025As Large Language Models (LLMs) increasingly participate in human-AI interactions, evaluating their Theory of Mind (ToM) capabilities - particularly their ability to track dynamic mental states - becomes crucial. While existing benchmarks assess basic ToM abilities, they predominantly focus on static snapshots of mental states, overlooking the temporal evolution that characterizes real-world social interactions. We present \textsc{DynToM}, a novel benchmark specifically designed to evaluate LLMs' ability to understand and track the temporal progression of mental states across interconnected scenarios. Through a systematic four-step framework, we generate 1,100 social contexts encompassing 5,500 scenarios and 78,100 questions, each validated for realism and quality. Our comprehensive evaluation of ten state-of-the-art LLMs reveals that their average performance underperforms humans by 44.7\%, with performance degrading significantly when tracking and reasoning about the shift of mental states. This performance gap highlights fundamental limitations in current LLMs' ability to model the dynamic nature of human mental states.
J1: Exploring Simple Test-Time Scaling for LLM-as-a-Judge
May 17, 2025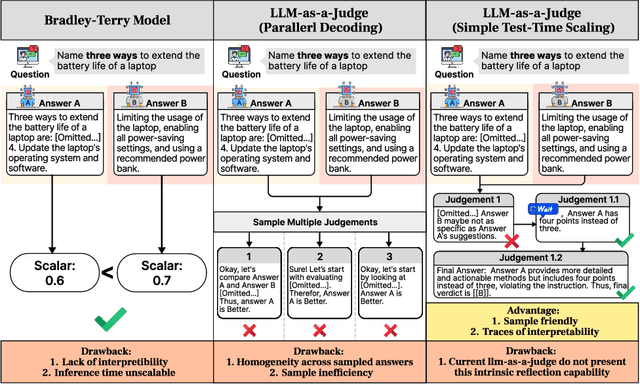
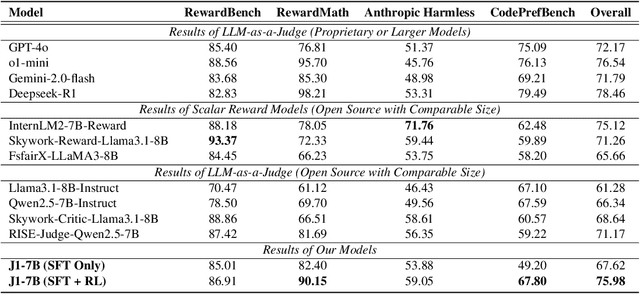
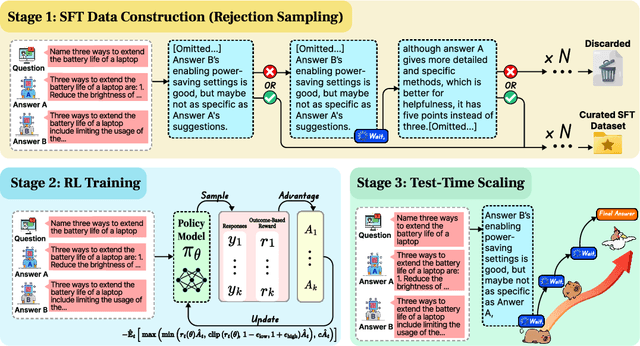
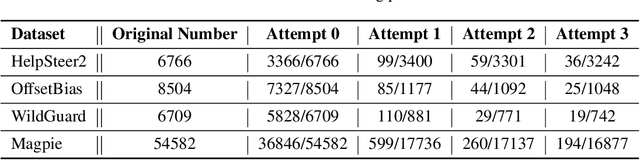
The current focus of AI research is shifting from emphasizing model training towards enhancing evaluation quality, a transition that is crucial for driving further advancements in AI systems. Traditional evaluation methods typically rely on reward models assigning scalar preference scores to outputs. Although effective, such approaches lack interpretability, leaving users often uncertain about why a reward model rates a particular response as high or low. The advent of LLM-as-a-Judge provides a more scalable and interpretable method of supervision, offering insights into the decision-making process. Moreover, with the emergence of large reasoning models, which consume more tokens for deeper thinking and answer refinement, scaling test-time computation in the LLM-as-a-Judge paradigm presents an avenue for further boosting performance and providing more interpretability through reasoning traces. In this paper, we introduce $\textbf{J1-7B}$, which is first supervised fine-tuned on reflection-enhanced datasets collected via rejection-sampling and subsequently trained using Reinforcement Learning (RL) with verifiable rewards. At inference time, we apply Simple Test-Time Scaling (STTS) strategies for additional performance improvement. Experimental results demonstrate that $\textbf{J1-7B}$ surpasses the previous state-of-the-art LLM-as-a-Judge by $ \textbf{4.8}$\% and exhibits a $ \textbf{5.1}$\% stronger scaling trend under STTS. Additionally, we present three key findings: (1) Existing LLM-as-a-Judge does not inherently exhibit such scaling trend. (2) Model simply fine-tuned on reflection-enhanced datasets continues to demonstrate similarly weak scaling behavior. (3) Significant scaling trend emerges primarily during the RL phase, suggesting that effective STTS capability is acquired predominantly through RL training.
MIO: A Foundation Model on Multimodal Tokens
Sep 26, 2024

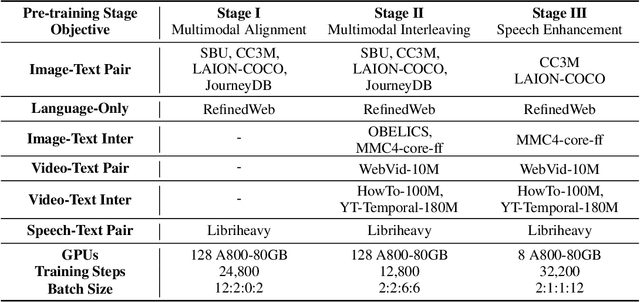

In this paper, we introduce MIO, a novel foundation model built on multimodal tokens, capable of understanding and generating speech, text, images, and videos in an end-to-end, autoregressive manner. While the emergence of large language models (LLMs) and multimodal large language models (MM-LLMs) propels advancements in artificial general intelligence through their versatile capabilities, they still lack true any-to-any understanding and generation. Recently, the release of GPT-4o has showcased the remarkable potential of any-to-any LLMs for complex real-world tasks, enabling omnidirectional input and output across images, speech, and text. However, it is closed-source and does not support the generation of multimodal interleaved sequences. To address this gap, we present MIO, which is trained on a mixture of discrete tokens across four modalities using causal multimodal modeling. MIO undergoes a four-stage training process: (1) alignment pre-training, (2) interleaved pre-training, (3) speech-enhanced pre-training, and (4) comprehensive supervised fine-tuning on diverse textual, visual, and speech tasks. Our experimental results indicate that MIO exhibits competitive, and in some cases superior, performance compared to previous dual-modal baselines, any-to-any model baselines, and even modality-specific baselines. Moreover, MIO demonstrates advanced capabilities inherent to its any-to-any feature, such as interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, instructional image editing, etc.
Large Language Models for Disease Diagnosis: A Scoping Review
Aug 27, 2024Automatic disease diagnosis has become increasingly valuable in clinical practice. The advent of large language models (LLMs) has catalyzed a paradigm shift in artificial intelligence, with growing evidence supporting the efficacy of LLMs in diagnostic tasks. Despite the growing attention in this field, many critical research questions remain under-explored. For instance, what diseases and LLM techniques have been investigated for diagnostic tasks? How can suitable LLM techniques and evaluation methods be selected for clinical decision-making? To answer these questions, we performed a comprehensive analysis of LLM-based methods for disease diagnosis. This scoping review examined the types of diseases, associated organ systems, relevant clinical data, LLM techniques, and evaluation methods reported in existing studies. Furthermore, we offered guidelines for data preprocessing and the selection of appropriate LLM techniques and evaluation strategies for diagnostic tasks. We also assessed the limitations of current research and delineated the challenges and future directions in this research field. In summary, our review outlined a blueprint for LLM-based disease diagnosis, helping to streamline and guide future research endeavors.
Towards a Client-Centered Assessment of LLM Therapists by Client Simulation
Jun 18, 2024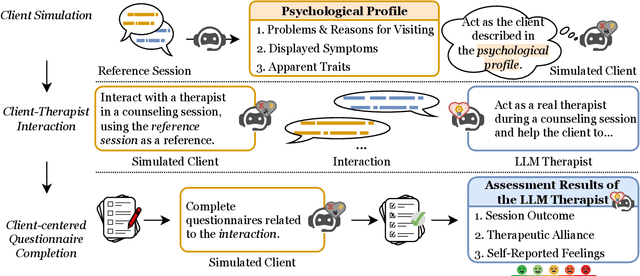

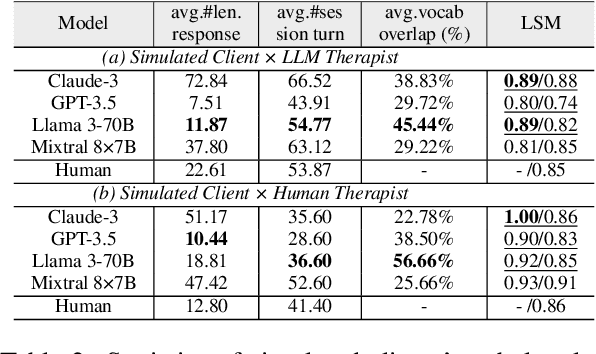
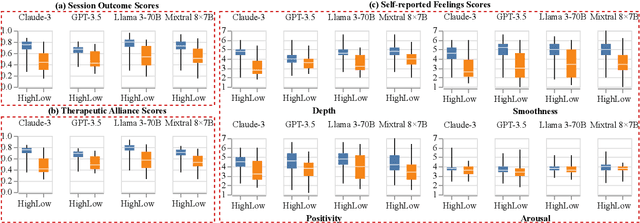
Although there is a growing belief that LLMs can be used as therapists, exploring LLMs' capabilities and inefficacy, particularly from the client's perspective, is limited. This work focuses on a client-centered assessment of LLM therapists with the involvement of simulated clients, a standard approach in clinical medical education. However, there are two challenges when applying the approach to assess LLM therapists at scale. Ethically, asking humans to frequently mimic clients and exposing them to potentially harmful LLM outputs can be risky and unsafe. Technically, it can be difficult to consistently compare the performances of different LLM therapists interacting with the same client. To this end, we adopt LLMs to simulate clients and propose ClientCAST, a client-centered approach to assessing LLM therapists by client simulation. Specifically, the simulated client is utilized to interact with LLM therapists and complete questionnaires related to the interaction. Based on the questionnaire results, we assess LLM therapists from three client-centered aspects: session outcome, therapeutic alliance, and self-reported feelings. We conduct experiments to examine the reliability of ClientCAST and use it to evaluate LLMs therapists implemented by Claude-3, GPT-3.5, LLaMA3-70B, and Mixtral 8*7B. Codes are released at https://github.com/wangjs9/ClientCAST.