 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
Feb 26, 2026Recent deep research agents primarily improve performance by scaling reasoning depth, but this leads to high inference cost and latency in search-intensive scenarios. Moreover, generalization across heterogeneous research settings remains challenging. In this work, we propose \emph{Search More, Think Less} (SMTL), a framework for long-horizon agentic search that targets both efficiency and generalization. SMTL replaces sequential reasoning with parallel evidence acquisition, enabling efficient context management under constrained context budgets. To support generalization across task types, we further introduce a unified data synthesis pipeline that constructs search tasks spanning both deterministic question answering and open-ended research scenarios with task appropriate evaluation metrics. We train an end-to-end agent using supervised fine-tuning and reinforcement learning, achieving strong and often state of the art performance across benchmarks including BrowseComp (48.6\%), GAIA (75.7\%), Xbench (82.0\%), and DeepResearch Bench (45.9\%). Compared to Mirothinker-v1.0, SMTL with maximum 100 interaction steps reduces the average number of reasoning steps on BrowseComp by 70.7\%, while improving accuracy.
EcoGym: Evaluating LLMs for Long-Horizon Plan-and-Execute in Interactive Economies
Feb 11, 2026Long-horizon planning is widely recognized as a core capability of autonomous LLM-based agents; however, current evaluation frameworks suffer from being largely episodic, domain-specific, or insufficiently grounded in persistent economic dynamics. We introduce EcoGym, a generalizable benchmark for continuous plan-and-execute decision making in interactive economies. EcoGym comprises three diverse environments: Vending, Freelance, and Operation, implemented in a unified decision-making process with standardized interfaces, and budgeted actions over an effectively unbounded horizon (1000+ steps if 365 day-loops for evaluation). The evaluation of EcoGym is based on business-relevant outcomes (e.g., net worth, income, and DAU), targeting long-term strategic coherence and robustness under partial observability and stochasticity. Experiments across eleven leading LLMs expose a systematic tension: no single model dominates across all three scenarios. Critically, we find that models exhibit significant suboptimality in either high-level strategies or efficient actions executions. EcoGym is released as an open, extensible testbed for transparent long-horizon agent evaluation and for studying controllability-utility trade-offs in realistic economic settings.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
HiNS: Hierarchical Negative Sampling for More Comprehensive Memory Retrieval Embedding Model
Jan 21, 2026Memory-augmented language agents rely on embedding models for effective memory retrieval. However, existing training data construction overlooks a critical limitation: the hierarchical difficulty of negative samples and their natural distribution in human-agent interactions. In practice, some negatives are semantically close distractors while others are trivially irrelevant, and natural dialogue exhibits structured proportions of these types. Current approaches using synthetic or uniformly sampled negatives fail to reflect this diversity, limiting embedding models' ability to learn nuanced discrimination essential for robust memory retrieval. In this work, we propose a principled data construction framework HiNS that explicitly models negative sample difficulty tiers and incorporates empirically grounded negative ratios derived from conversational data, enabling the training of embedding models with substantially improved retrieval fidelity and generalization in memory-intensive tasks. Experiments show significant improvements: on LoCoMo, F1/BLEU-1 gains of 3.27%/3.30%(MemoryOS) and 1.95%/1.78% (Mem0); on PERSONAMEM, total score improvements of 1.19% (MemoryOS) and 2.55% (Mem0).
PersonaDual: Balancing Personalization and Objectivity via Adaptive Reasoning
Jan 13, 2026As users increasingly expect LLMs to align with their preferences, personalized information becomes valuable. However, personalized information can be a double-edged sword: it can improve interaction but may compromise objectivity and factual correctness, especially when it is misaligned with the question. To alleviate this problem, we propose PersonaDual, a framework that supports both general-purpose objective reasoning and personalized reasoning in a single model, and adaptively switches modes based on context. PersonaDual is first trained with SFT to learn two reasoning patterns, and then further optimized via reinforcement learning with our proposed DualGRPO to improve mode selection. Experiments on objective and personalized benchmarks show that PersonaDual preserves the benefits of personalization while reducing interference, achieving near interference-free performance and better leveraging helpful personalized signals to improve objective problem-solving.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
MemEvolve: Meta-Evolution of Agent Memory Systems
Dec 21, 2025Self-evolving memory systems are unprecedentedly reshaping the evolutionary paradigm of large language model (LLM)-based agents. Prior work has predominantly relied on manually engineered memory architectures to store trajectories, distill experience, and synthesize reusable tools, enabling agents to evolve on the fly within environment interactions. However, this paradigm is fundamentally constrained by the staticity of the memory system itself: while memory facilitates agent-level evolving, the underlying memory architecture cannot be meta-adapted to diverse task contexts. To address this gap, we propose MemEvolve, a meta-evolutionary framework that jointly evolves agents' experiential knowledge and their memory architecture, allowing agent systems not only to accumulate experience but also to progressively refine how they learn from it. To ground MemEvolve in prior research and foster openness in future self-evolving systems, we introduce EvolveLab, a unified self-evolving memory codebase that distills twelve representative memory systems into a modular design space (encode, store, retrieve, manage), providing both a standardized implementation substrate and a fair experimental arena. Extensive evaluations on four challenging agentic benchmarks demonstrate that MemEvolve achieves (I) substantial performance gains, improving frameworks such as SmolAgent and Flash-Searcher by up to $17.06\%$; and (II) strong cross-task and cross-LLM generalization, designing memory architectures that transfer effectively across diverse benchmarks and backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents
Nov 18, 2025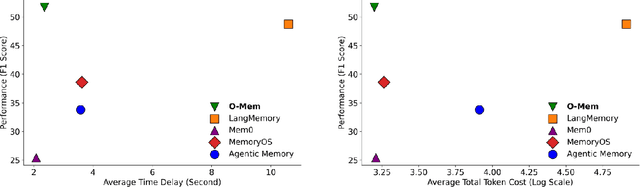
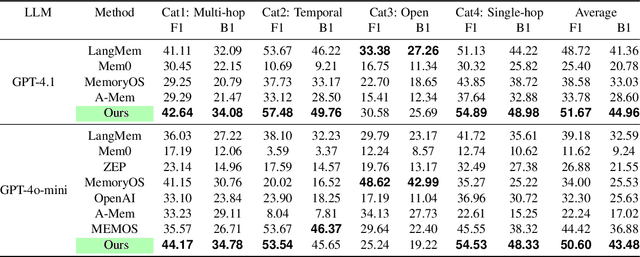
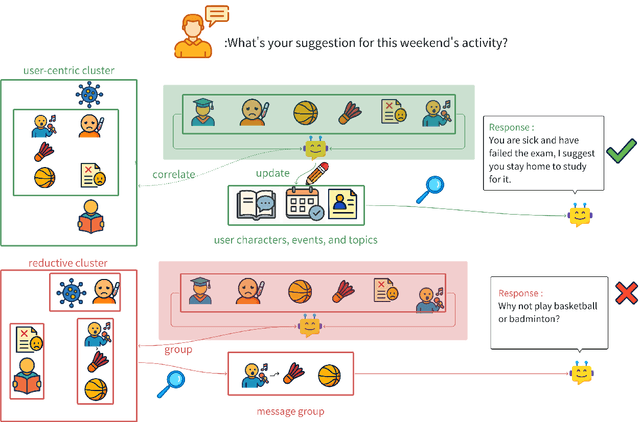

Recent advancements in LLM-powered agents have demonstrated significant potential in generating human-like responses; however, they continue to face challenges in maintaining long-term interactions within complex environments, primarily due to limitations in contextual consistency and dynamic personalization. Existing memory systems often depend on semantic grouping prior to retrieval, which can overlook semantically irrelevant yet critical user information and introduce retrieval noise. In this report, we propose the initial design of O-Mem, a novel memory framework based on active user profiling that dynamically extracts and updates user characteristics and event records from their proactive interactions with agents. O-Mem supports hierarchical retrieval of persona attributes and topic-related context, enabling more adaptive and coherent personalized responses. O-Mem achieves 51.67% on the public LoCoMo benchmark, a nearly 3% improvement upon LangMem,the previous state-of-the-art, and it achieves 62.99% on PERSONAMEM, a 3.5% improvement upon A-Mem,the previous state-of-the-art. O-Mem also boosts token and interaction response time efficiency compared to previous memory frameworks. Our work opens up promising directions for developing efficient and human-like personalized AI assistants in the future.
Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
Oct 21, 2025Faithfully personalizing large language models (LLMs) to align with individual user preferences is a critical but challenging task. While supervised fine-tuning (SFT) quickly reaches a performance plateau, standard reinforcement learning from human feedback (RLHF) also struggles with the nuances of personalization. Scalar-based reward models are prone to reward hacking which leads to verbose and superficially personalized responses. To address these limitations, we propose Critique-Post-Edit, a robust reinforcement learning framework that enables more faithful and controllable personalization. Our framework integrates two key components: (1) a Personalized Generative Reward Model (GRM) that provides multi-dimensional scores and textual critiques to resist reward hacking, and (2) a Critique-Post-Edit mechanism where the policy model revises its own outputs based on these critiques for more targeted and efficient learning. Under a rigorous length-controlled evaluation, our method substantially outperforms standard PPO on personalization benchmarks. Personalized Qwen2.5-7B achieves an average 11\% win-rate improvement, and personalized Qwen2.5-14B model surpasses the performance of GPT-4.1. These results demonstrate a practical path to faithful, efficient, and controllable personalization.