 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP: Detecting Audio Backdoor Attacks via Stability-based Trigger Exposure Profiling
Mar 18, 2026With the widespread deployment of deep-learning-based speech models in security-critical applications, backdoor attacks have emerged as a serious threat: an adversary who poisons a small fraction of training data can implant a hidden trigger that controls the model's output while preserving normal behavior on clean inputs. Existing inference-time defenses are not well suited to the audio domain, as they either rely on trigger over-robustness assumptions that fail on transformation-based and semantic triggers, or depend on properties specific to image or text modalities. In this paper, we propose STEP (Stability-based Trigger Exposure Profiling), a black-box, retraining-free backdoor detector that operates under hard-label-only access. Its core idea is to exploit a characteristic dual anomaly of backdoor triggers: anomalous label stability under semantic-breaking perturbations, and anomalous label fragility under semantic-preserving perturbations. STEP profiles each test sample with two complementary perturbation branches that target these two properties respectively, scores the resulting stability features with one-class anomaly detectors trained on benign references, and fuses the two scores via unsupervised weighting. Extensive experiments across seven backdoor attacks show that STEP achieves an average AUROC of 97.92% and EER of 4.54%, substantially outperforming state-of-the-art baselines, and generalizes across model architectures, speech tasks, an open-set verification scenario, and over-the-air physical-world settings.
Long-Short Term Agents for Pure-Vision Bronchoscopy Robotic Autonomy
Mar 09, 2026Accurate intraoperative navigation is essential for robot-assisted endoluminal intervention, but remains difficult because of limited endoscopic field of view and dynamic artifacts. Existing navigation platforms often rely on external localization technologies, such as electromagnetic tracking or shape sensing, which increase hardware complexity and remain vulnerable to intraoperative anatomical mismatch. We present a vision-only autonomy framework that performs long-horizon bronchoscopic navigation using preoperative CT-derived virtual targets and live endoscopic video, without external tracking during navigation. The framework uses hierarchical long-short agents: a short-term reactive agent for continuous low-latency motion control, and a long-term strategic agent for decision support at anatomically ambiguous points. When their recommendations conflict, a world-model critic predicts future visual states for candidate actions and selects the action whose predicted state best matches the target view. We evaluated the system in a high-fidelity airway phantom, three ex vivo porcine lungs, and a live porcine model. The system reached all planned segmental targets in the phantom, maintained 80\% success to the eighth generation ex vivo, and achieved in vivo navigation performance comparable to the expert bronchoscopist. These results support the preclinical feasibility of sensor-free autonomous bronchoscopic navigation.
Generative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
MemEvolve: Meta-Evolution of Agent Memory Systems
Dec 21, 2025Self-evolving memory systems are unprecedentedly reshaping the evolutionary paradigm of large language model (LLM)-based agents. Prior work has predominantly relied on manually engineered memory architectures to store trajectories, distill experience, and synthesize reusable tools, enabling agents to evolve on the fly within environment interactions. However, this paradigm is fundamentally constrained by the staticity of the memory system itself: while memory facilitates agent-level evolving, the underlying memory architecture cannot be meta-adapted to diverse task contexts. To address this gap, we propose MemEvolve, a meta-evolutionary framework that jointly evolves agents' experiential knowledge and their memory architecture, allowing agent systems not only to accumulate experience but also to progressively refine how they learn from it. To ground MemEvolve in prior research and foster openness in future self-evolving systems, we introduce EvolveLab, a unified self-evolving memory codebase that distills twelve representative memory systems into a modular design space (encode, store, retrieve, manage), providing both a standardized implementation substrate and a fair experimental arena. Extensive evaluations on four challenging agentic benchmarks demonstrate that MemEvolve achieves (I) substantial performance gains, improving frameworks such as SmolAgent and Flash-Searcher by up to $17.06\%$; and (II) strong cross-task and cross-LLM generalization, designing memory architectures that transfer effectively across diverse benchmarks and backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?
Sep 04, 2025Large Language Model (LLM)-based agentic systems, often comprising multiple models, complex tool invocations, and orchestration protocols, substantially outperform monolithic agents. Yet this very sophistication amplifies their fragility, making them more prone to system failure. Pinpointing the specific agent or step responsible for an error within long execution traces defines the task of agentic system failure attribution. Current state-of-the-art reasoning LLMs, however, remain strikingly inadequate for this challenge, with accuracy generally below 10%. To address this gap, we propose AgenTracer, the first automated framework for annotating failed multi-agent trajectories via counterfactual replay and programmed fault injection, producing the curated dataset TracerTraj. Leveraging this resource, we develop AgenTracer-8B, a lightweight failure tracer trained with multi-granular reinforcement learning, capable of efficiently diagnosing errors in verbose multi-agent interactions. On the Who&When benchmark, AgenTracer-8B outperforms giant proprietary LLMs like Gemini-2.5-Pro and Claude-4-Sonnet by up to 18.18%, setting a new standard in LLM agentic failure attribution. More importantly, AgenTracer-8B delivers actionable feedback to off-the-shelf multi-agent systems like MetaGPT and MaAS with 4.8-14.2% performance gains, empowering self-correcting and self-evolving agentic AI.
SWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.
Geometric Parameter Estimations of Perovskite Solar Cells Based on Optical Simulations
Mar 13, 2025



This paper presents a non-invasive approach to estimate the layer thicknesses of perovskite solar cells. The thicknesses are predicted by a convolutional neural network that leverages the external quantum efficiency of a perovskite solar cell. The network is trained in thickness ranges where the optical properties are constant, and these ranges set the constraints for the network's application. Due to light sensitivity issues with opaque perovskites, the convolutional neural network showed better performance with transparent perovskites. To optimize the performance and reduce the root mean square error, we tried different sampling methods, image specifications, and Bayesian optimization for hyperparameter tuning. While sampling methods showed marginal improvement, implementing Bayesian optimization demonstrated high accuracy. Other minor optimization attempts include experimenting with input specifications and pre-processing approaches. The results confirm the feasibility, efficiency, and effectiveness of a convolution neural network for predicting perovskite solar cells' layer thicknesses based on controlled experiments.
Feature-EndoGaussian: Feature Distilled Gaussian Splatting in Surgical Deformable Scene Reconstruction
Mar 08, 2025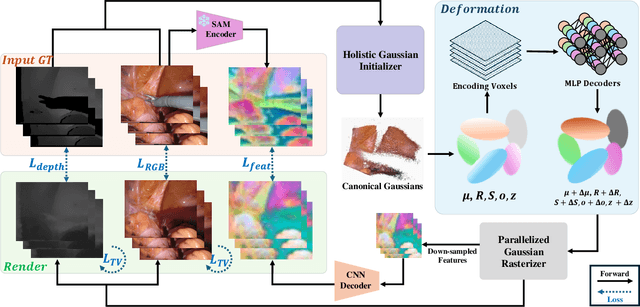
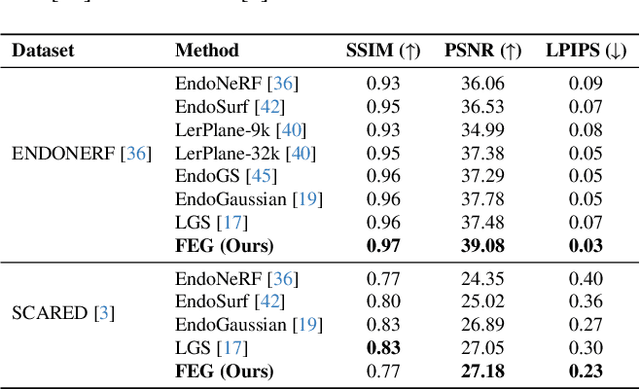
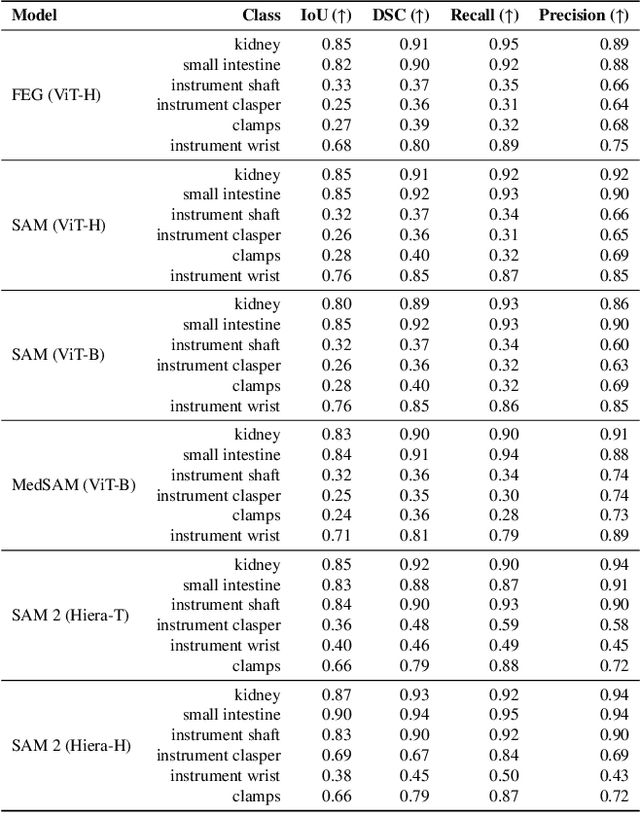
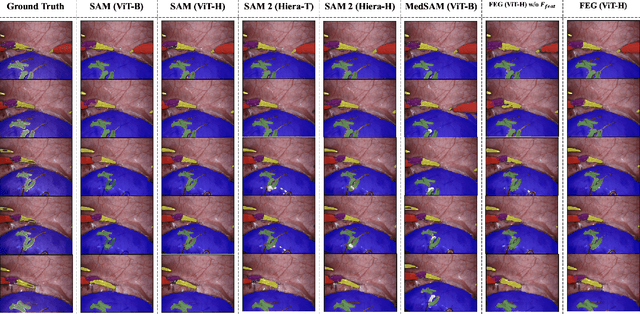
Minimally invasive surgery (MIS) has transformed clinical practice by reducing recovery times, minimizing complications, and enhancing precision. Nonetheless, MIS inherently relies on indirect visualization and precise instrument control, posing unique challenges. Recent advances in artificial intelligence have enabled real-time surgical scene understanding through techniques such as image classification, object detection, and segmentation, with scene reconstruction emerging as a key element for enhanced intraoperative guidance. Although neural radiance fields (NeRFs) have been explored for this purpose, their substantial data requirements and slow rendering inhibit real-time performance. In contrast, 3D Gaussian Splatting (3DGS) offers a more efficient alternative, achieving state-of-the-art performance in dynamic surgical scene reconstruction. In this work, we introduce Feature-EndoGaussian (FEG), an extension of 3DGS that integrates 2D segmentation cues into 3D rendering to enable real-time semantic and scene reconstruction. By leveraging pretrained segmentation foundation models, FEG incorporates semantic feature distillation within the Gaussian deformation framework, thereby enhancing both reconstruction fidelity and segmentation accuracy. On the EndoNeRF dataset, FEG achieves superior performance (SSIM of 0.97, PSNR of 39.08, and LPIPS of 0.03) compared to leading methods. Additionally, on the EndoVis18 dataset, FEG demonstrates competitive class-wise segmentation metrics while balancing model size and real-time performance.
From Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval
Feb 18, 2025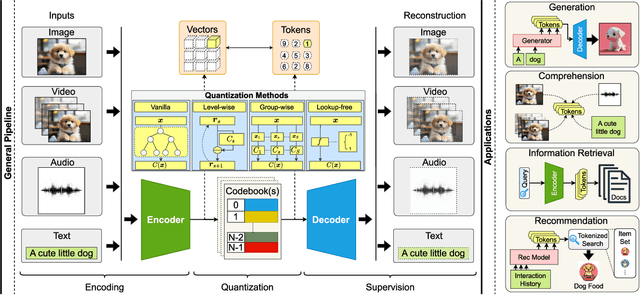
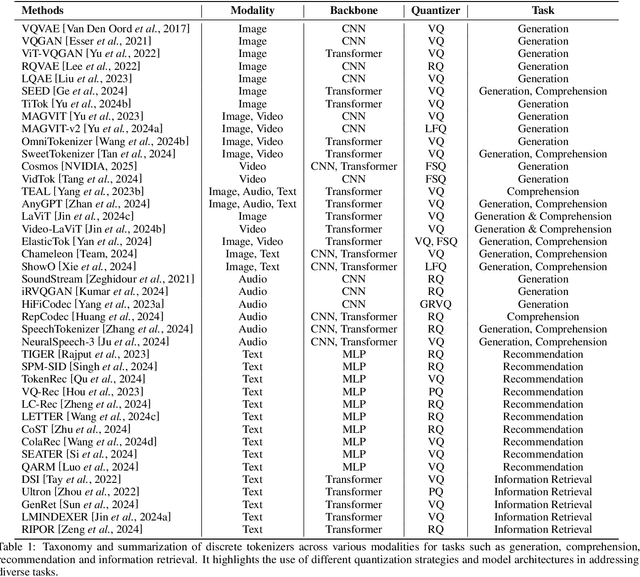
Discrete tokenizers have emerged as indispensable components in modern machine learning systems, particularly within the context of autoregressive modeling and large language models (LLMs). These tokenizers serve as the critical interface that transforms raw, unstructured data from diverse modalities into discrete tokens, enabling LLMs to operate effectively across a wide range of tasks. Despite their central role in generation, comprehension, and recommendation systems, a comprehensive survey dedicated to discrete tokenizers remains conspicuously absent in the literature. This paper addresses this gap by providing a systematic review of the design principles, applications, and challenges of discrete tokenizers. We begin by dissecting the sub-modules of tokenizers and systematically demonstrate their internal mechanisms to provide a comprehensive understanding of their functionality and design. Building on this foundation, we synthesize state-of-the-art methods, categorizing them into multimodal generation and comprehension tasks, and semantic tokens for personalized recommendations. Furthermore, we critically analyze the limitations of existing tokenizers and outline promising directions for future research. By presenting a unified framework for understanding discrete tokenizers, this survey aims to guide researchers and practitioners in addressing open challenges and advancing the field, ultimately contributing to the development of more robust and versatile AI systems.