 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.
Skeleton-Guided-Translation: A Benchmarking Framework for Code Repository Translation with Fine-Grained Quality Evaluation
Jan 27, 2025



The advancement of large language models has intensified the need to modernize enterprise applications and migrate legacy systems to secure, versatile languages. However, existing code translation benchmarks primarily focus on individual functions, overlooking the complexities involved in translating entire repositories, such as maintaining inter-module coherence and managing dependencies. While some recent repository-level translation benchmarks attempt to address these challenges, they still face limitations, including poor maintainability and overly coarse evaluation granularity, which make them less developer-friendly. We introduce Skeleton-Guided-Translation, a framework for repository-level Java to C# code translation with fine-grained quality evaluation. It uses a two-step process: first translating the repository's structural "skeletons", then translating the full repository guided by these skeletons. Building on this, we present TRANSREPO-BENCH, a benchmark of high quality open-source Java repositories and their corresponding C# skeletons, including matching unit tests and build configurations. Our unit tests are fixed and can be applied across multiple or incremental translations without manual adjustments, enhancing automation and scalability in evaluations. Additionally, we develop fine-grained evaluation metrics that assess translation quality at the individual test case level, addressing traditional binary metrics' inability to distinguish when build failures cause all tests to fail. Evaluations using TRANSREPO-BENCH highlight key challenges and advance more accurate repository level code translation.
DI-BENCH: Benchmarking Large Language Models on Dependency Inference with Testable Repositories at Scale
Jan 23, 2025Large Language Models have advanced automated software development, however, it remains a challenge to correctly infer dependencies, namely, identifying the internal components and external packages required for a repository to successfully run. Existing studies highlight that dependency-related issues cause over 40\% of observed runtime errors on the generated repository. To address this, we introduce DI-BENCH, a large-scale benchmark and evaluation framework specifically designed to assess LLMs' capability on dependency inference. The benchmark features 581 repositories with testing environments across Python, C#, Rust, and JavaScript. Extensive experiments with textual and execution-based metrics reveal that the current best-performing model achieves only a 42.9% execution pass rate, indicating significant room for improvement. DI-BENCH establishes a new viewpoint for evaluating LLM performance on repositories, paving the way for more robust end-to-end software synthesis.
Suboptimality bounds for trace-bounded SDPs enable a faster and scalable low-rank SDP solver SDPLR+
Jun 14, 2024



Semidefinite programs (SDPs) and their solvers are powerful tools with many applications in machine learning and data science. Designing scalable SDP solvers is challenging because by standard the positive semidefinite decision variable is an $n \times n$ dense matrix, even though the input is often an $n \times n$ sparse matrix. However, the information in the solution may not correspond to a full-rank dense matrix as shown by Bavinok and Pataki. Two decades ago, Burer and Monterio developed an SDP solver $\texttt{SDPLR}$ that optimizes over a low-rank factorization instead of the full matrix. This greatly decreases the storage cost and works well for many problems. The original solver $\texttt{SDPLR}$ tracks only the primal infeasibility of the solution, limiting the technique's flexibility to produce moderate accuracy solutions. We use a suboptimality bound for trace-bounded SDP problems that enables us to track the progress better and perform early termination. We then develop $\texttt{SDPLR+}$, which starts the optimization with an extremely low-rank factorization and dynamically updates the rank based on the primal infeasibility and suboptimality. This further speeds up the computation and saves the storage cost. Numerical experiments on Max Cut, Minimum Bisection, Cut Norm, and Lov\'{a}sz Theta problems with many recent memory-efficient scalable SDP solvers demonstrate its scalability up to problems with million-by-million decision variables and it is often the fastest solver to a moderate accuracy of $10^{-2}$.
Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
Apr 13, 2024



Large language models (LLMs) has experienced exponential growth, they demonstrate remarkable performance across various tasks. Notwithstanding, contemporary research primarily centers on enhancing the size and quality of pretraining data, still utilizing the next token prediction task on autoregressive transformer model structure. The efficacy of this task in truly facilitating the model's comprehension of code logic remains questionable, we speculate that it still interprets code as mere text, while human emphasizes the underlying logical knowledge. In order to prove it, we introduce a new task, "Logically Equivalent Code Selection," which necessitates the selection of logically equivalent code from a candidate set, given a query code. Our experimental findings indicate that current LLMs underperform in this task, since they understand code by unordered bag of keywords. To ameliorate their performance, we propose an advanced pretraining task, "Next Token Prediction+". This task aims to modify the sentence embedding distribution of the LLM without sacrificing its generative capabilities. Our experimental results reveal that following this pretraining, both Code Llama and StarCoder, the prevalent code domain pretraining models, display significant improvements on our logically equivalent code selection task and the code completion task.
Rethinking the Instruction Quality: LIFT is What You Need
Dec 27, 2023Instruction tuning, a specialized technique to enhance large language model (LLM) performance via instruction datasets, relies heavily on the quality of employed data. Existing quality improvement methods alter instruction data through dataset expansion or curation. However, the expansion method risks data redundancy, potentially compromising LLM performance, while the curation approach confines the LLM's potential to the original dataset. Our aim is to surpass the original data quality without encountering these shortcomings. To achieve this, we propose LIFT (LLM Instruction Fusion Transfer), a novel and versatile paradigm designed to elevate the instruction quality to new heights. LIFT strategically broadens data distribution to encompass more high-quality subspaces and eliminates redundancy, concentrating on high-quality segments across overall data subspaces. Experimental results demonstrate that, even with a limited quantity of high-quality instruction data selected by our paradigm, LLMs not only consistently uphold robust performance across various tasks but also surpass some state-of-the-art results, highlighting the significant improvement in instruction quality achieved by our paradigm.
SUT: Active Defects Probing for Transcompiler Models
Oct 22, 2023



Automatic Program translation has enormous application value and hence has been attracting significant interest from AI researchers. However, we observe that current program translation models still make elementary syntax errors, particularly, when the target language does not have syntax elements in the source language. Metrics like BLUE, CodeBLUE and computation accuracy may not expose these issues. In this paper we introduce a new metrics for programming language translation and these metrics address these basic syntax errors. We develop a novel active defects probing suite called Syntactic Unit Tests (SUT) which includes a highly interpretable evaluation harness for accuracy and test scoring. Experiments have shown that even powerful models like ChatGPT still make mistakes on these basic unit tests. Specifically, compared to previous program translation task evaluation dataset, its pass rate on our unit tests has decreased by 26.15%. Further our evaluation harness reveal syntactic element errors in which these models exhibit deficiencies.
Program Translation via Code Distillation
Oct 17, 2023



Software version migration and program translation are an important and costly part of the lifecycle of large codebases. Traditional machine translation relies on parallel corpora for supervised translation, which is not feasible for program translation due to a dearth of aligned data. Recent unsupervised neural machine translation techniques have overcome data limitations by included techniques such as back translation and low level compiler intermediate representations (IR). These methods face significant challenges due to the noise in code snippet alignment and the diversity of IRs respectively. In this paper we propose a novel model called Code Distillation (CoDist) whereby we capture the semantic and structural equivalence of code in a language agnostic intermediate representation. Distilled code serves as a translation pivot for any programming language, leading by construction to parallel corpora which scale to all available source code by simply applying the distillation compiler. We demonstrate that our approach achieves state-of-the-art performance on CodeXGLUE and TransCoder GeeksForGeeks translation benchmarks, with an average absolute increase of 12.7% on the TransCoder GeeksforGeeks translation benchmark compare to TransCoder-ST.
A Multi-robot Coverage Path Planning Algorithm Based on Improved DARP Algorithm
Apr 19, 2023
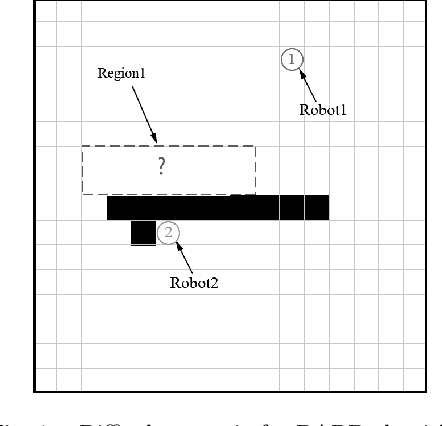

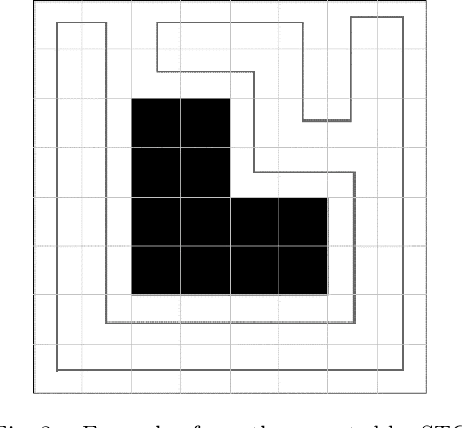
The research on multi-robot coverage path planning (CPP) has been attracting more and more attention. In order to achieve efficient coverage, this paper proposes an improved DARP coverage algorithm. The improved DARP algorithm based on A* algorithm is used to assign tasks to robots and then combined with STC algorithm based on Up-First algorithm to achieve full coverage of the task area. Compared with the initial DARP algorithm, this algorithm has higher efficiency and higher coverage rate.
A flexible PageRank-based graph embedding framework closely related to spectral eigenvector embeddings
Jul 22, 2022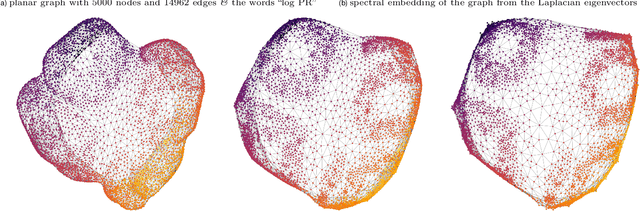
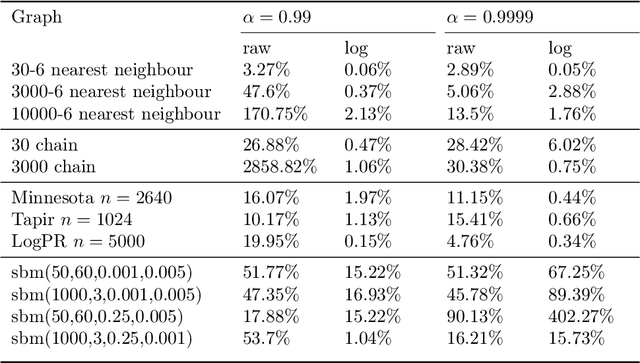
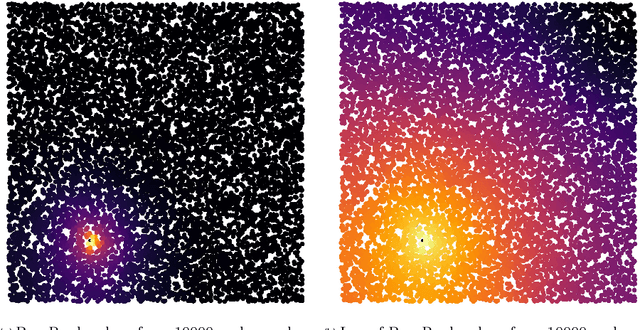
We study a simple embedding technique based on a matrix of personalized PageRank vectors seeded on a random set of nodes. We show that the embedding produced by the element-wise logarithm of this matrix (1) are related to the spectral embedding for a class of graphs where spectral embeddings are significant, and hence useful representation of the data, (2) can be done for the entire network or a smaller part of it, which enables precise local representation, and (3) uses a relatively small number of PageRank vectors compared to the size of the networks. Most importantly, the general nature of this embedding strategy opens up many emerging applications, where eigenvector and spectral techniques may not be well established, to the PageRank-based relatives. For instance, similar techniques can be used on PageRank vectors from hypergraphs to get "spectral-like" embeddings.