 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models
Apr 05, 2026Post training via GRPO has demonstrated remarkable effectiveness in improving the generation quality of flow-matching models. However, GRPO suffers from inherently low sample efficiency due to its on-policy training paradigm. To address this limitation, we present OP-GRPO, the first Off-Policy GRPO framework tailored for flow-matching models. First, we actively select high-quality trajectories and adaptively incorporate them into a replay buffer for reuse in subsequent training iterations. Second, to mitigate the distribution shift introduced by off-policy samples, we propose a sequence-level importance sampling correction that preserves the integrity of GRPO's clipping mechanism while ensuring stable policy updates. Third, we theoretically and empirically show that late denoising steps yield ill-conditioned off-policy ratios, and mitigate this by truncating trajectories at late steps. Across image and video generation benchmarks, OP-GRPO achieves comparable or superior performance to Flow-GRPO with only 34.2% of the training steps on average, yielding substantial gains in training efficiency while maintaining generation quality.
Alternating Reinforcement Learning for Rubric-Based Reward Modeling in Non-Verifiable LLM Post-Training
Feb 02, 2026Standard reward models typically predict scalar scores that fail to capture the multifaceted nature of response quality in non-verifiable domains, such as creative writing or open-ended instruction following. To address this limitation, we propose Rubric-ARM, a framework that jointly optimizes a rubric generator and a judge using reinforcement learning from preference feedback. Unlike existing methods that rely on static rubrics or disjoint training pipelines, our approach treats rubric generation as a latent action learned to maximize judgment accuracy. We introduce an alternating optimization strategy to mitigate the non-stationarity of simultaneous updates, providing theoretical analysis that demonstrates how this schedule reduces gradient variance during training. Extensive experiments show that Rubric-ARM achieves state-of-the-art performance among baselines on multiple benchmarks and significantly improves downstream policy alignment in both offline and online reinforcement learning settings.
CleanUpBench: Embodied Sweeping and Grasping Benchmark
Aug 07, 2025Embodied AI benchmarks have advanced navigation, manipulation, and reasoning, but most target complex humanoid agents or large-scale simulations that are far from real-world deployment. In contrast, mobile cleaning robots with dual mode capabilities, such as sweeping and grasping, are rapidly emerging as realistic and commercially viable platforms. However, no benchmark currently exists that systematically evaluates these agents in structured, multi-target cleaning tasks, revealing a critical gap between academic research and real-world applications. We introduce CleanUpBench, a reproducible and extensible benchmark for evaluating embodied agents in realistic indoor cleaning scenarios. Built on NVIDIA Isaac Sim, CleanUpBench simulates a mobile service robot equipped with a sweeping mechanism and a six-degree-of-freedom robotic arm, enabling interaction with heterogeneous objects. The benchmark includes manually designed environments and one procedurally generated layout to assess generalization, along with a comprehensive evaluation suite covering task completion, spatial efficiency, motion quality, and control performance. To support comparative studies, we provide baseline agents based on heuristic strategies and map-based planning. CleanUpBench bridges the gap between low-level skill evaluation and full-scene testing, offering a scalable testbed for grounded, embodied intelligence in everyday settings.
A Multi-robot Coverage Path Planning Algorithm Based on Improved DARP Algorithm
Apr 19, 2023
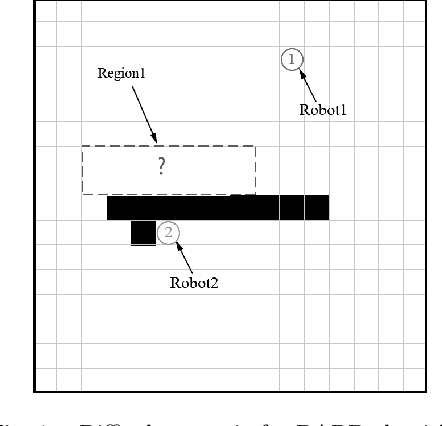

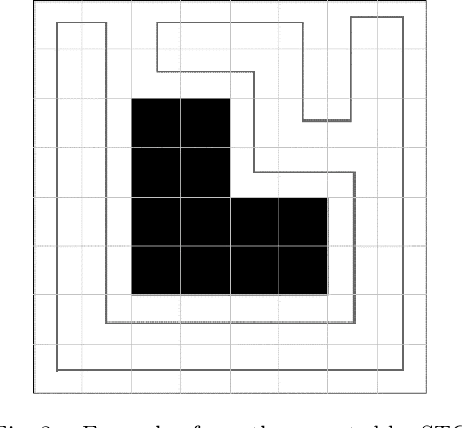
The research on multi-robot coverage path planning (CPP) has been attracting more and more attention. In order to achieve efficient coverage, this paper proposes an improved DARP coverage algorithm. The improved DARP algorithm based on A* algorithm is used to assign tasks to robots and then combined with STC algorithm based on Up-First algorithm to achieve full coverage of the task area. Compared with the initial DARP algorithm, this algorithm has higher efficiency and higher coverage rate.
Structured Attention Composition for Temporal Action Localization
May 27, 2022
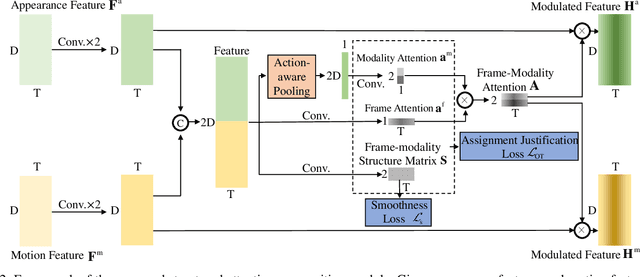
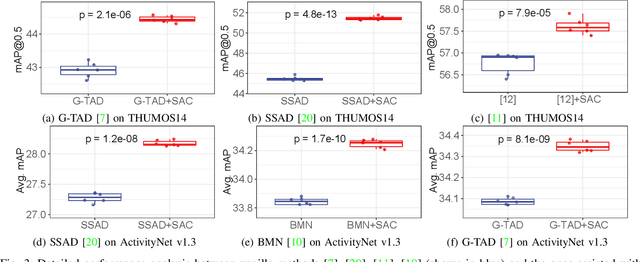

Temporal action localization aims at localizing action instances from untrimmed videos. Existing works have designed various effective modules to precisely localize action instances based on appearance and motion features. However, by treating these two kinds of features with equal importance, previous works cannot take full advantage of each modality feature, making the learned model still sub-optimal. To tackle this issue, we make an early effort to study temporal action localization from the perspective of multi-modality feature learning, based on the observation that different actions exhibit specific preferences to appearance or motion modality. Specifically, we build a novel structured attention composition module. Unlike conventional attention, the proposed module would not infer frame attention and modality attention independently. Instead, by casting the relationship between the modality attention and the frame attention as an attention assignment process, the structured attention composition module learns to encode the frame-modality structure and uses it to regularize the inferred frame attention and modality attention, respectively, upon the optimal transport theory. The final frame-modality attention is obtained by the composition of the two individual attentions. The proposed structured attention composition module can be deployed as a plug-and-play module into existing action localization frameworks. Extensive experiments on two widely used benchmarks show that the proposed structured attention composition consistently improves four state-of-the-art temporal action localization methods and builds new state-of-the-art performance on THUMOS14. Code is availabel at https://github.com/VividLe/Structured-Attention-Composition.
Background-Click Supervision for Temporal Action Localization
Nov 24, 2021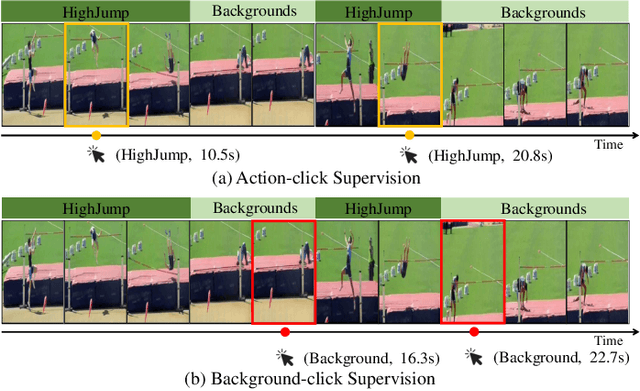
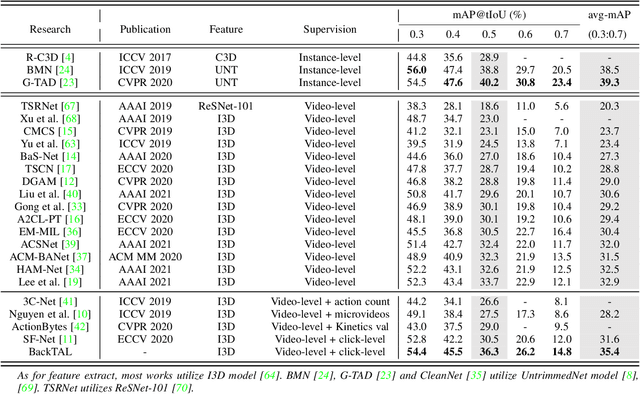
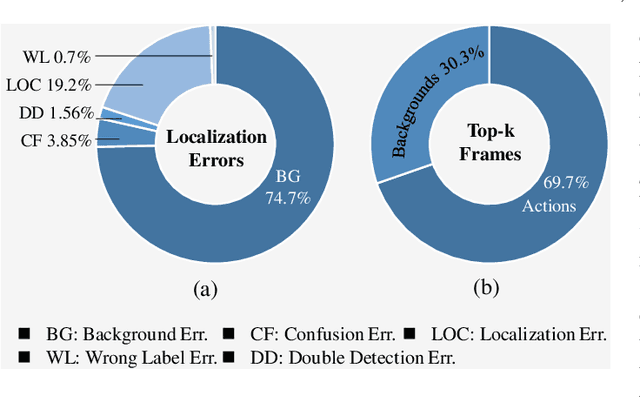
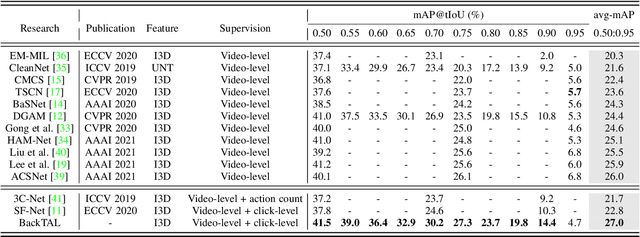
Weakly supervised temporal action localization aims at learning the instance-level action pattern from the video-level labels, where a significant challenge is action-context confusion. To overcome this challenge, one recent work builds an action-click supervision framework. It requires similar annotation costs but can steadily improve the localization performance when compared to the conventional weakly supervised methods. In this paper, by revealing that the performance bottleneck of the existing approaches mainly comes from the background errors, we find that a stronger action localizer can be trained with labels on the background video frames rather than those on the action frames. To this end, we convert the action-click supervision to the background-click supervision and develop a novel method, called BackTAL. Specifically, BackTAL implements two-fold modeling on the background video frames, i.e. the position modeling and the feature modeling. In position modeling, we not only conduct supervised learning on the annotated video frames but also design a score separation module to enlarge the score differences between the potential action frames and backgrounds. In feature modeling, we propose an affinity module to measure frame-specific similarities among neighboring frames and dynamically attend to informative neighbors when calculating temporal convolution. Extensive experiments on three benchmarks are conducted, which demonstrate the high performance of the established BackTAL and the rationality of the proposed background-click supervision. Code is available at https://github.com/VividLe/BackTAL.
Equivalent Classification Mapping for Weakly Supervised Temporal Action Localization
Aug 18, 2020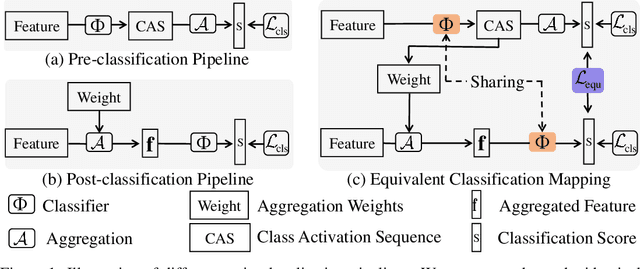
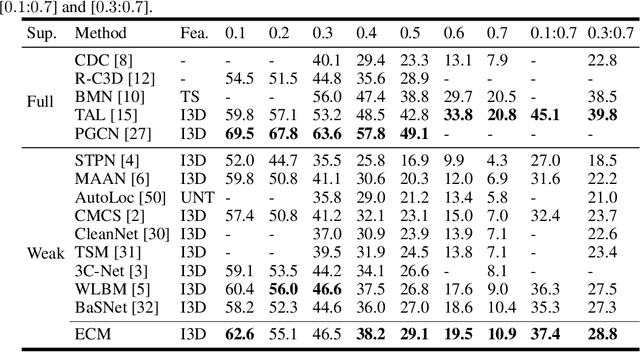
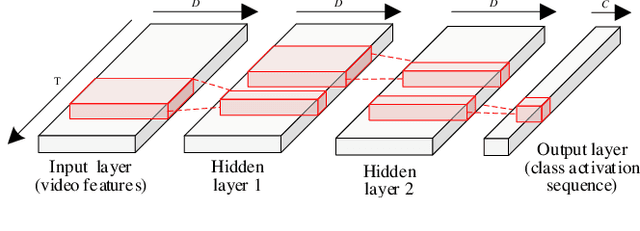
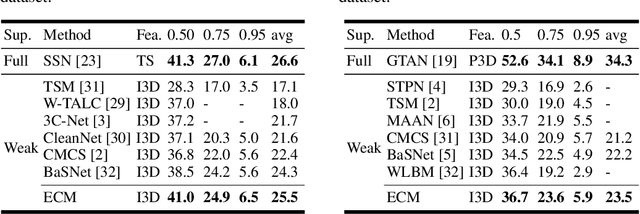
Weakly supervised temporal action localization is a newly emerging yet widely studied topic in recent years. The existing methods can be categorized into two localization-by-classification pipelines, i.e., the pre-classification pipeline and the post-classification pipeline. The pre-classification pipeline first performs classification on each video snippet and then aggregate the snippet-level classification scores to obtain the video-level classification score, while the post-classification pipeline aggregates the snippet-level features first and then predicts the video-level classification score based on the aggregated feature. Although the classifiers in these two pipelines are used in different ways, the role they play is exactly the same---to classify the given features to identify the corresponding action categories. To this end, an ideal classifier can make both pipelines work. This inspires us to simultaneously learn these two pipelines in a unified framework to obtain an effective classifier. Specifically, in the proposed learning framework, we implement two parallel network streams to model the two localization-by-classification pipelines simultaneously and make the two network streams share the same classifier, thus achieving the novel Equivalent Classification Mapping (ECM) mechanism. Considering that an ideal classifier would make the classification results of the two network streams be identical and make the frame-level classification scores obtained from the pre-classification pipeline and the feature aggregation weights in the post-classification pipeline be consistent, we further introduce an equivalent classification loss and an equivalent weight transition module to endow the proposed learning framework with such properties. Comprehensive experiments are carried on three benchmarks and the proposed ECM achieves superior performance over other state-of-the-art methods.
Kid-Net: Convolution Networks for Kidney Vessels Segmentation from CT-Volumes
Jun 18, 2018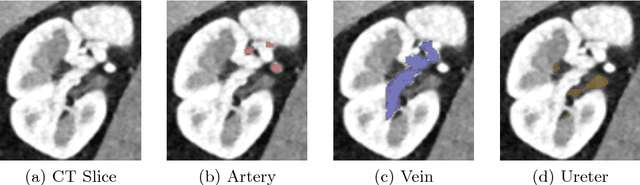
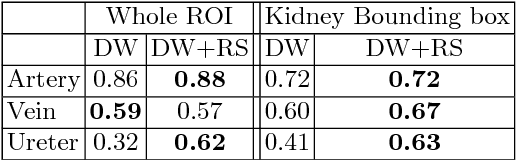
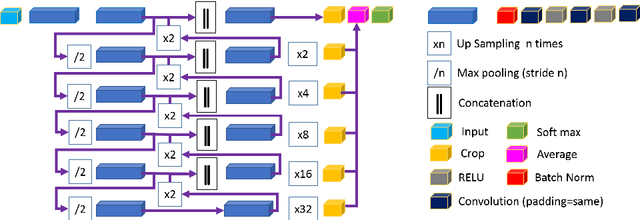
Semantic image segmentation plays an important role in modeling patient-specific anatomy. We propose a convolution neural network, called Kid-Net, along with a training schema to segment kidney vessels: artery, vein and collecting system. Such segmentation is vital during the surgical planning phase in which medical decisions are made before surgical incision. Our main contribution is developing a training schema that handles unbalanced data, reduces false positives and enables high-resolution segmentation with a limited memory budget. These objectives are attained using dynamic weighting, random sampling and 3D patch segmentation. Manual medical image annotation is both time-consuming and expensive. Kid-Net reduces kidney vessels segmentation time from matter of hours to minutes. It is trained end-to-end using 3D patches from volumetric CT-images. A complete segmentation for a 512x512x512 CT-volume is obtained within a few minutes (1-2 mins) by stitching the output 3D patches together. Feature down-sampling and up-sampling are utilized to achieve higher classification and localization accuracies. Quantitative and qualitative evaluation results on a challenging testing dataset show Kid-Net competence.