 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Attention Composition for Temporal Action Localization
Paper and Code

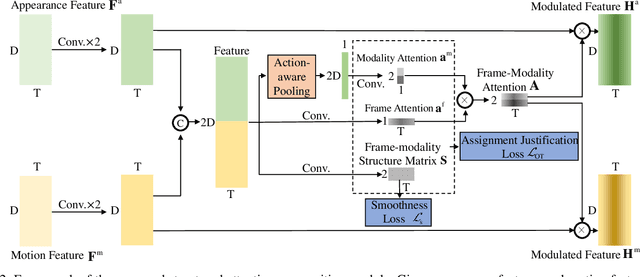
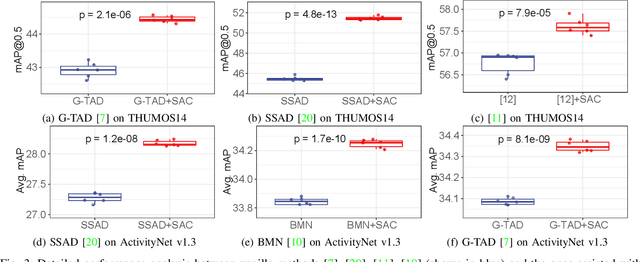

Temporal action localization aims at localizing action instances from untrimmed videos. Existing works have designed various effective modules to precisely localize action instances based on appearance and motion features. However, by treating these two kinds of features with equal importance, previous works cannot take full advantage of each modality feature, making the learned model still sub-optimal. To tackle this issue, we make an early effort to study temporal action localization from the perspective of multi-modality feature learning, based on the observation that different actions exhibit specific preferences to appearance or motion modality. Specifically, we build a novel structured attention composition module. Unlike conventional attention, the proposed module would not infer frame attention and modality attention independently. Instead, by casting the relationship between the modality attention and the frame attention as an attention assignment process, the structured attention composition module learns to encode the frame-modality structure and uses it to regularize the inferred frame attention and modality attention, respectively, upon the optimal transport theory. The final frame-modality attention is obtained by the composition of the two individual attentions. The proposed structured attention composition module can be deployed as a plug-and-play module into existing action localization frameworks. Extensive experiments on two widely used benchmarks show that the proposed structured attention composition consistently improves four state-of-the-art temporal action localization methods and builds new state-of-the-art performance on THUMOS14. Code is availabel at https://github.com/VividLe/Structured-Attention-Composition.