 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence
Jun 18, 2026Real-world spatial intelligence requires reasoning over a continuous and evolving 3D world, yet existing VLMs and tool-augmented agents largely remain tied to static, stateless inference from isolated visual observations. We introduce \textbf{\textsc{S-Agent}}, a spatial tool-use agentic paradigm for understanding and reasoning over continuous multi-view images and videos. By formulating spatial reasoning as spatio-temporal evidence accumulation rather than isolated frame-level prediction, \textsc{S-Agent} reshapes spatial perception into scene-centric understanding beyond frame-centric recognition. Specifically, \textsc{S-Agent} casts the VLM as a semantic planner that decides what evidence is needed, while a hierarchy of spatial tools and experts grounds objects in 2D, lifts them into 3D geometric evidence, and aggregates this evidence into high-level spatial knowledge (\textit{e.g.}, counting, measurement, orientation, and relative position). Additionally, a temporal memory mechanism, including Scene Memory for maintaining the evolving scene state and Agent Memory for accumulating reasoning context, enables evidence integration across frames and reasoning steps. Comprehensive experiments on multi-view and video spatial reasoning benchmarks show that \textsc{S-Agent} consistently improves both open-source and closed-source VLMs in a training-free manner. Beyond inference-time augmentation, supervised fine-tuning (SFT) on \textsc{S-Agent}-generated spatial trajectories \textsc{S-300K} yields \textsc{S-Agent-8B}, a compact spatial agent that significantly surpasses similar-scale baselines (e.g., Qwen3-VL-8B) and performs comparably to advanced closed-source models (e.g., GPT-5.4 and Gemini 3).
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
May 26, 2026While spatial foundation models have demonstrated impressive performance on standard datasets, a critical question remains: are they truly all-round players capable of generalizing robustly across diverse downstream tasks, arbitrary viewpoints, shifting scene domains, varying input densities, and specific hardware constraints? Answering this overarching question requires a holistic assessment, yet current models are mainly evaluated on specific domains for which they were specifically designed or trained. Such evaluations are intrinsically limited by narrow paradigm coverage, limited scene domains, and arbitrary frame sampling, making it fundamentally difficult to assess their true generalization capabilities. To address this gap, we present SpatialBench, a cross-paradigm, domain-diverse benchmark for spatial foundation models with deterministic sampling. SpatialBench features unprecedented scale and rigorous deterministic design, comprising 19 datasets and 546 scenes across 5 diverse spatial domains. It comprehensively evaluates 41 models across 6 paradigms on 5 task suites under 4 different input density settings. Our extensive evaluation reveals that current models are not yet all-round players, and uncovers crucial insights for future advancement. Specifically, we demonstrate that full-context attention maximizes accuracy while bounded-memory strategies unlock long-sequence scalability. Moreover, our empirical evaluations in challenging embodied and egocentric tasks demonstrate that strict domain alignment and high data quality are far more critical to performance than simple dataset scaling. Furthermore, to address the largest data gap identified in our analysis, we go beyond evaluation by introducing a large-scale dataset, DA-Next-5M, and a strong baseline model, DA-Next, pushing the boundaries of spatial representation learning.
Holi-Spatial: Evolving Video Streams into Holistic 3D Spatial Intelligence
Mar 08, 2026The pursuit of spatial intelligence fundamentally relies on access to large-scale, fine-grained 3D data. However, existing approaches predominantly construct spatial understanding benchmarks by generating question-answer (QA) pairs from a limited number of manually annotated datasets, rather than systematically annotating new large-scale 3D scenes from raw web data. As a result, their scalability is severely constrained, and model performance is further hindered by domain gaps inherent in these narrowly curated datasets. In this work, we propose Holi-Spatial, the first fully automated, large-scale, spatially-aware multimodal dataset, constructed from raw video inputs without human intervention, using the proposed data curation pipeline. Holi-Spatial supports multi-level spatial supervision, ranging from geometrically accurate 3D Gaussian Splatting (3DGS) reconstructions with rendered depth maps to object-level and relational semantic annotations, together with corresponding spatial Question-Answer (QA) pairs. Following a principled and systematic pipeline, we further construct Holi-Spatial-4M, the first large-scale, high-quality 3D semantic dataset, containing 12K optimized 3DGS scenes, 1.3M 2D masks, 320K 3D bounding boxes, 320K instance captions, 1.2M 3D grounding instances, and 1.2M spatial QA pairs spanning diverse geometric, relational, and semantic reasoning tasks. Holi-Spatial demonstrates exceptional performance in data curation quality, significantly outperforming existing feed-forward and per-scene optimized methods on datasets such as ScanNet, ScanNet++, and DL3DV. Furthermore, fine-tuning Vision-Language Models (VLMs) on spatial reasoning tasks using this dataset has also led to substantial improvements in model performance.
GeoAgent: Learning to Geolocate Everywhere with Reinforced Geographic Characteristics
Feb 13, 2026This paper presents GeoAgent, a model capable of reasoning closely with humans and deriving fine-grained address conclusions. Previous RL-based methods have achieved breakthroughs in performance and interpretability but still remain concerns because of their reliance on AI-generated chain-of-thought (CoT) data and training strategies, which conflict with geographic characteristics. To address these issues, we first introduce GeoSeek, a new geolocation dataset comprising CoT data annotated by geographic experts and professional players. We further thoroughly explore the inherent characteristics of geographic tasks and propose a geo-similarity reward and a consistency reward assessed by a consistency agent to assist training. This encourages the model to converge towards correct answers from a geographic perspective while ensuring the integrity and consistency of its reasoning process. Experimental results show that GeoAgent outperforms existing methods and a series of general VLLMs across multiple grains, while generating reasoning that closely aligns with humans.
StereoMV2D: A Sparse Temporal Stereo-Enhanced Framework for Robust Multi-View 3D Object Detection
Dec 19, 2025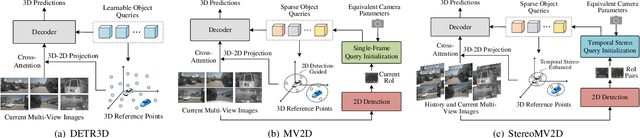
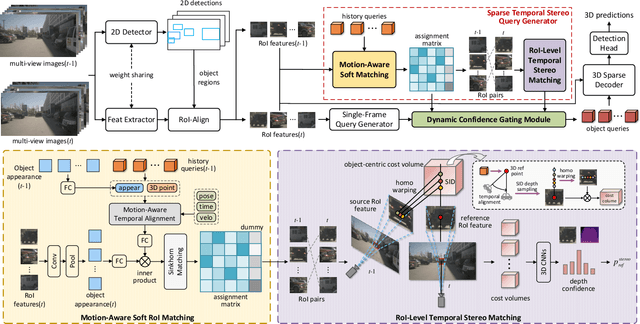

Multi-view 3D object detection is a fundamental task in autonomous driving perception, where achieving a balance between detection accuracy and computational efficiency remains crucial. Sparse query-based 3D detectors efficiently aggregate object-relevant features from multi-view images through a set of learnable queries, offering a concise and end-to-end detection paradigm. Building on this foundation, MV2D leverages 2D detection results to provide high-quality object priors for query initialization, enabling higher precision and recall. However, the inherent depth ambiguity in single-frame 2D detections still limits the accuracy of 3D query generation. To address this issue, we propose StereoMV2D, a unified framework that integrates temporal stereo modeling into the 2D detection-guided multi-view 3D detector. By exploiting cross-temporal disparities of the same object across adjacent frames, StereoMV2D enhances depth perception and refines the query priors, while performing all computations efficiently within 2D regions of interest (RoIs). Furthermore, a dynamic confidence gating mechanism adaptively evaluates the reliability of temporal stereo cues through learning statistical patterns derived from the inter-frame matching matrix together with appearance consistency, ensuring robust detection under object appearance and occlusion. Extensive experiments on the nuScenes and Argoverse 2 datasets demonstrate that StereoMV2D achieves superior detection performance without incurring significant computational overhead. Code will be available at https://github.com/Uddd821/StereoMV2D.
Visionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
Dec 09, 2025Neural rendering, particularly 3D Gaussian Splatting (3DGS), has evolved rapidly and become a key component for building world models. However, existing viewer solutions remain fragmented, heavy, or constrained by legacy pipelines, resulting in high deployment friction and limited support for dynamic content and generative models. In this work, we present Visionary, an open, web-native platform for real-time various Gaussian Splatting and meshes rendering. Built on an efficient WebGPU renderer with per-frame ONNX inference, Visionary enables dynamic neural processing while maintaining a lightweight, "click-to-run" browser experience. It introduces a standardized Gaussian Generator contract, which not only supports standard 3DGS rendering but also allows plug-and-play algorithms to generate or update Gaussians each frame. Such inference also enables us to apply feedforward generative post-processing. The platform further offers a plug in three.js library with a concise TypeScript API for seamless integration into existing web applications. Experiments show that, under identical 3DGS assets, Visionary achieves superior rendering efficiency compared to current Web viewers due to GPU-based primitive sorting. It already supports multiple variants, including MLP-based 3DGS, 4DGS, neural avatars, and style transformation or enhancement networks. By unifying inference and rendering directly in the browser, Visionary significantly lowers the barrier to reproduction, comparison, and deployment of 3DGS-family methods, serving as a unified World Model Carrier for both reconstructive and generative paradigms.
VDNeRF: Vision-only Dynamic Neural Radiance Field for Urban Scenes
Nov 09, 2025Neural Radiance Fields (NeRFs) implicitly model continuous three-dimensional scenes using a set of images with known camera poses, enabling the rendering of photorealistic novel views. However, existing NeRF-based methods encounter challenges in applications such as autonomous driving and robotic perception, primarily due to the difficulty of capturing accurate camera poses and limitations in handling large-scale dynamic environments. To address these issues, we propose Vision-only Dynamic NeRF (VDNeRF), a method that accurately recovers camera trajectories and learns spatiotemporal representations for dynamic urban scenes without requiring additional camera pose information or expensive sensor data. VDNeRF employs two separate NeRF models to jointly reconstruct the scene. The static NeRF model optimizes camera poses and static background, while the dynamic NeRF model incorporates the 3D scene flow to ensure accurate and consistent reconstruction of dynamic objects. To address the ambiguity between camera motion and independent object motion, we design an effective and powerful training framework to achieve robust camera pose estimation and self-supervised decomposition of static and dynamic elements in a scene. Extensive evaluations on mainstream urban driving datasets demonstrate that VDNeRF surpasses state-of-the-art NeRF-based pose-free methods in both camera pose estimation and dynamic novel view synthesis.
IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
Oct 26, 2025Humans naturally perceive the geometric structure and semantic content of a 3D world as intertwined dimensions, enabling coherent and accurate understanding of complex scenes. However, most prior approaches prioritize training large geometry models for low-level 3D reconstruction and treat high-level spatial understanding in isolation, overlooking the crucial interplay between these two fundamental aspects of 3D-scene analysis, thereby limiting generalization and leading to poor performance in downstream 3D understanding tasks. Recent attempts have mitigated this issue by simply aligning 3D models with specific language models, thus restricting perception to the aligned model's capacity and limiting adaptability to downstream tasks. In this paper, we propose InstanceGrounded Geometry Transformer (IGGT), an end-to-end large unified transformer to unify the knowledge for both spatial reconstruction and instance-level contextual understanding. Specifically, we design a 3D-Consistent Contrastive Learning strategy that guides IGGT to encode a unified representation with geometric structures and instance-grounded clustering through only 2D visual inputs. This representation supports consistent lifting of 2D visual inputs into a coherent 3D scene with explicitly distinct object instances. To facilitate this task, we further construct InsScene-15K, a large-scale dataset with high-quality RGB images, poses, depth maps, and 3D-consistent instance-level mask annotations with a novel data curation pipeline.
Pursuing Temporal-Consistent Video Virtual Try-On via Dynamic Pose Interaction
May 22, 2025Video virtual try-on aims to seamlessly dress a subject in a video with a specific garment. The primary challenge involves preserving the visual authenticity of the garment while dynamically adapting to the pose and physique of the subject. While existing methods have predominantly focused on image-based virtual try-on, extending these techniques directly to videos often results in temporal inconsistencies. Most current video virtual try-on approaches alleviate this challenge by incorporating temporal modules, yet still overlook the critical spatiotemporal pose interactions between human and garment. Effective pose interactions in videos should not only consider spatial alignment between human and garment poses in each frame but also account for the temporal dynamics of human poses throughout the entire video. With such motivation, we propose a new framework, namely Dynamic Pose Interaction Diffusion Models (DPIDM), to leverage diffusion models to delve into dynamic pose interactions for video virtual try-on. Technically, DPIDM introduces a skeleton-based pose adapter to integrate synchronized human and garment poses into the denoising network. A hierarchical attention module is then exquisitely designed to model intra-frame human-garment pose interactions and long-term human pose dynamics across frames through pose-aware spatial and temporal attention mechanisms. Moreover, DPIDM capitalizes on a temporal regularized attention loss between consecutive frames to enhance temporal consistency. Extensive experiments conducted on VITON-HD, VVT and ViViD datasets demonstrate the superiority of our DPIDM against the baseline methods. Notably, DPIDM achieves VFID score of 0.506 on VVT dataset, leading to 60.5% improvement over the state-of-the-art GPD-VVTO approach.
Semantic-Aligned Learning with Collaborative Refinement for Unsupervised VI-ReID
Apr 27, 2025Unsupervised visible-infrared person re-identification (USL-VI-ReID) seeks to match pedestrian images of the same individual across different modalities without human annotations for model learning. Previous methods unify pseudo-labels of cross-modality images through label association algorithms and then design contrastive learning framework for global feature learning. However, these methods overlook the cross-modality variations in feature representation and pseudo-label distributions brought by fine-grained patterns. This insight results in insufficient modality-shared learning when only global features are optimized. To address this issue, we propose a Semantic-Aligned Learning with Collaborative Refinement (SALCR) framework, which builds up optimization objective for specific fine-grained patterns emphasized by each modality, thereby achieving complementary alignment between the label distributions of different modalities. Specifically, we first introduce a Dual Association with Global Learning (DAGI) module to unify the pseudo-labels of cross-modality instances in a bi-directional manner. Afterward, a Fine-Grained Semantic-Aligned Learning (FGSAL) module is carried out to explore part-level semantic-aligned patterns emphasized by each modality from cross-modality instances. Optimization objective is then formulated based on the semantic-aligned features and their corresponding label space. To alleviate the side-effects arising from noisy pseudo-labels, we propose a Global-Part Collaborative Refinement (GPCR) module to mine reliable positive sample sets for the global and part features dynamically and optimize the inter-instance relationships. Extensive experiments demonstrate the effectiveness of the proposed method, which achieves superior performances to state-of-the-art methods. Our code is available at \href{https://github.com/FranklinLingfeng/code-for-SALCR}.