 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMTrack: Semantic Multi-Object Tracking with Multi-modal Large Language Models
Jan 10, 2026Traditional Multi-Object Tracking (MOT) systems have achieved remarkable precision in localization and association, effectively answering \textit{where} and \textit{who}. However, they often function as autistic observers, capable of tracing geometric paths but blind to the semantic \textit{what} and \textit{why} behind object behaviors. To bridge the gap between geometric perception and cognitive reasoning, we propose \textbf{LLMTrack}, a novel end-to-end framework for Semantic Multi-Object Tracking (SMOT). We adopt a bionic design philosophy that decouples strong localization from deep understanding, utilizing Grounding DINO as the eyes and the LLaVA-OneVision multimodal large model as the brain. We introduce a Spatio-Temporal Fusion Module that aggregates instance-level interaction features and video-level contexts, enabling the Large Language Model (LLM) to comprehend complex trajectories. Furthermore, we design a progressive three-stage training strategy, Visual Alignment, Temporal Fine-tuning, and Semantic Injection via LoRA to efficiently adapt the massive model to the tracking domain. Extensive experiments on the BenSMOT benchmark demonstrate that LLMTrack achieves state-of-the-art performance, significantly outperforming existing methods in instance description, interaction recognition, and video summarization while maintaining robust tracking stability.
StereoMV2D: A Sparse Temporal Stereo-Enhanced Framework for Robust Multi-View 3D Object Detection
Dec 19, 2025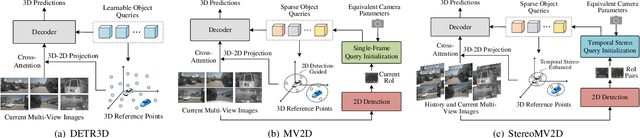
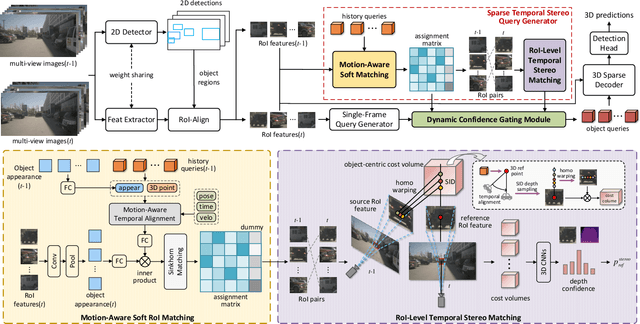

Multi-view 3D object detection is a fundamental task in autonomous driving perception, where achieving a balance between detection accuracy and computational efficiency remains crucial. Sparse query-based 3D detectors efficiently aggregate object-relevant features from multi-view images through a set of learnable queries, offering a concise and end-to-end detection paradigm. Building on this foundation, MV2D leverages 2D detection results to provide high-quality object priors for query initialization, enabling higher precision and recall. However, the inherent depth ambiguity in single-frame 2D detections still limits the accuracy of 3D query generation. To address this issue, we propose StereoMV2D, a unified framework that integrates temporal stereo modeling into the 2D detection-guided multi-view 3D detector. By exploiting cross-temporal disparities of the same object across adjacent frames, StereoMV2D enhances depth perception and refines the query priors, while performing all computations efficiently within 2D regions of interest (RoIs). Furthermore, a dynamic confidence gating mechanism adaptively evaluates the reliability of temporal stereo cues through learning statistical patterns derived from the inter-frame matching matrix together with appearance consistency, ensuring robust detection under object appearance and occlusion. Extensive experiments on the nuScenes and Argoverse 2 datasets demonstrate that StereoMV2D achieves superior detection performance without incurring significant computational overhead. Code will be available at https://github.com/Uddd821/StereoMV2D.
HV-BEV: Decoupling Horizontal and Vertical Feature Sampling for Multi-View 3D Object Detection
Dec 25, 2024



The application of vision-based multi-view environmental perception system has been increasingly recognized in autonomous driving technology, especially the BEV-based models. Current state-of-the-art solutions primarily encode image features from each camera view into the BEV space through explicit or implicit depth prediction. However, these methods often focus on improving the accuracy of projecting 2D features into corresponding depth regions, while overlooking the highly structured information of real-world objects and the varying height distributions of objects across different scenes. In this work, we propose HV-BEV, a novel approach that decouples feature sampling in the BEV grid queries paradigm into horizontal feature aggregation and vertical adaptive height-aware reference point sampling, aiming to improve both the aggregation of objects' complete information and generalization to diverse road environments. Specifically, we construct a learnable graph structure in the horizontal plane aligned with the ground for 3D reference points, reinforcing the association of the same instance across different BEV grids, especially when the instance spans multiple image views around the vehicle. Additionally, instead of relying on uniform sampling within a fixed height range, we introduce a height-aware module that incorporates historical information, enabling the reference points to adaptively focus on the varying heights at which objects appear in different scenes. Extensive experiments validate the effectiveness of our proposed method, demonstrating its superior performance over the baseline across the nuScenes dataset. Moreover, our best-performing model achieves a remarkable 50.5% mAP and 59.8% NDS on the nuScenes testing set.
FastTrackTr:Towards Fast Multi-Object Tracking with Transformers
Nov 24, 2024



Transformer-based multi-object tracking (MOT) methods have captured the attention of many researchers in recent years. However, these models often suffer from slow inference speeds due to their structure or other issues. To address this problem, we revisited the Joint Detection and Tracking (JDT) method by looking back at past approaches. By integrating the original JDT approach with some advanced theories, this paper employs an efficient method of information transfer between frames on the DETR, constructing a fast and novel JDT-type MOT framework: FastTrackTr. Thanks to the superiority of this information transfer method, our approach not only reduces the number of queries required during tracking but also avoids the excessive introduction of network structures, ensuring model simplicity. Experimental results indicate that our method has the potential to achieve real-time tracking and exhibits competitive tracking accuracy across multiple datasets.
One-Step Multi-View Clustering Based on Transition Probability
Mar 03, 2024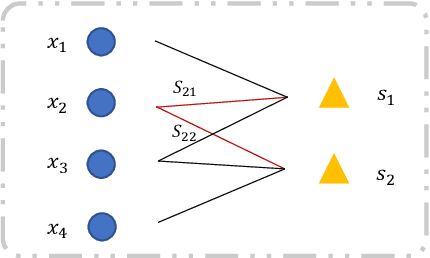

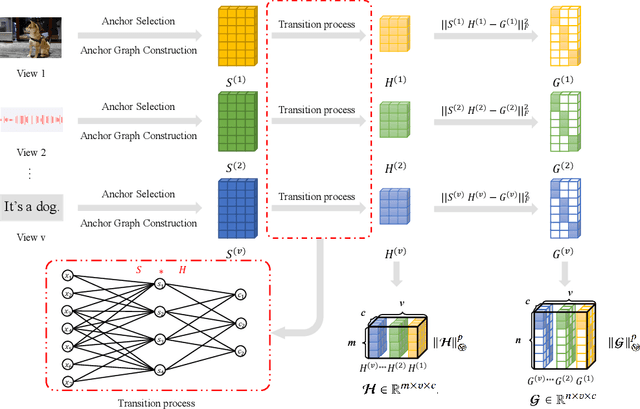
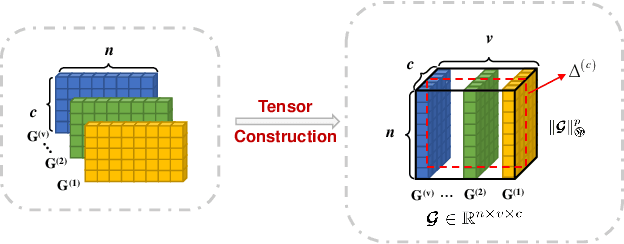
The large-scale multi-view clustering algorithms, based on the anchor graph, have shown promising performance and efficiency and have been extensively explored in recent years. Despite their successes, current methods lack interpretability in the clustering process and do not sufficiently consider the complementary information across different views. To address these shortcomings, we introduce the One-Step Multi-View Clustering Based on Transition Probability (OSMVC-TP). This method adopts a probabilistic approach, which leverages the anchor graph, representing the transition probabilities from samples to anchor points. Our method directly learns the transition probabilities from anchor points to categories, and calculates the transition probabilities from samples to categories, thus obtaining soft label matrices for samples and anchor points, enhancing the interpretability of clustering. Furthermore, to maintain consistency in labels across different views, we apply a Schatten p-norm constraint on the tensor composed of the soft labels. This approach effectively harnesses the complementary information among the views. Extensive experiments have confirmed the effectiveness and robustness of OSMVC-TP.