 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Stone, Three Birds: Self-adaptive Optimal Transport for Multi-VLM Selection, Adaptation, and Ensembling
Jun 06, 2026Vision-language models (VLMs) enable visual recognition from semantic class descriptions, which makes them attractive when target annotations are scarce or unavailable. Most deployment pipelines, however, first choose a single VLM and then adapt that model to the unlabeled target set. This single-backbone paradigm hides a critical assumption: the selected VLM is already compatible with the target domain. In realistic cross-domain deployment, several general-purpose and domain-specialized VLMs may be plausible, yet no instance-level target labels are available to identify the reliable ones. Deployment therefore requires a coupled solution for model selection, target adaptation, and prediction integration. We revisit this problem from a system-level multi-VLM perspective. Our central observation is that the three decisions above depend on the same latent object: a trustworthy sample-class structure in the target set. Different VLMs may encode different transfer biases and produce conflicting predictions, but their outputs can still provide complementary evidence for estimating this structure. We propose One Stone, Three Birds, a training-free framework based on self-adaptive optimal transport. Given a pool of frozen candidate VLMs, OSTB estimates a consensus sample-to-class transport plan without updating VLM parameters. The learned transport structure is then reused for all deployment objectives: model selection is performed by ranking the combined semantic and visual reliability induced by the consensus plan; target adaptation is obtained by fitting transport-conditioned visual classifiers; and ensembling is implemented through reliability-aware probabilistic integration. Extensive experiments on natural-image, remote-sensing, and medical-pathology benchmarks show that OSTB improves model ranking, adaptation stability, and ensemble robustness under heterogeneous candidate pools.
Manifold Clustering with Schatten p-norm Maximization
Apr 29, 2025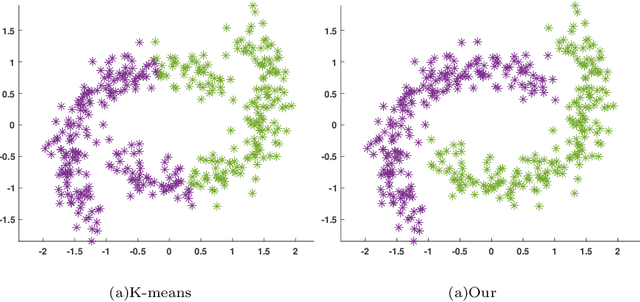
Manifold clustering, with its exceptional ability to capture complex data structures, holds a pivotal position in cluster analysis. However, existing methods often focus only on finding the optimal combination between K-means and manifold learning, and overlooking the consistency between the data structure and labels. To address this issue, we deeply explore the relationship between K-means and manifold learning, and on this basis, fuse them to develop a new clustering framework. Specifically, the algorithm uses labels to guide the manifold structure and perform clustering on it, which ensures the consistency between the data structure and labels. Furthermore, in order to naturally maintain the class balance in the clustering process, we maximize the Schatten p-norm of labels, and provide a theoretical proof to support this. Additionally, our clustering framework is designed to be flexible and compatible with many types of distance functions, which facilitates efficient processing of nonlinear separable data. The experimental results of several databases confirm the superiority of our proposed model.
Self-Supervised Graph Embedding Clustering
Sep 24, 2024



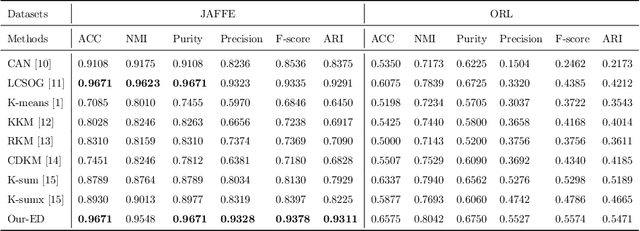
The K-means one-step dimensionality reduction clustering method has made some progress in addressing the curse of dimensionality in clustering tasks. However, it combines the K-means clustering and dimensionality reduction processes for optimization, leading to limitations in the clustering effect due to the introduced hyperparameters and the initialization of clustering centers. Moreover, maintaining class balance during clustering remains challenging. To overcome these issues, we propose a unified framework that integrates manifold learning with K-means, resulting in the self-supervised graph embedding framework. Specifically, we establish a connection between K-means and the manifold structure, allowing us to perform K-means without explicitly defining centroids. Additionally, we use this centroid-free K-means to generate labels in low-dimensional space and subsequently utilize the label information to determine the similarity between samples. This approach ensures consistency between the manifold structure and the labels. Our model effectively achieves one-step clustering without the need for redundant balancing hyperparameters. Notably, we have discovered that maximizing the $\ell_{2,1}$-norm naturally maintains class balance during clustering, a result that we have theoretically proven. Finally, experiments on multiple datasets demonstrate that the clustering results of Our-LPP and Our-MFA exhibit excellent and reliable performance.
High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning
Apr 07, 2024Zero-shot learning(ZSL) aims to recognize new classes without prior exposure to their samples, relying on semantic knowledge from observed classes. However, current attention-based models may overlook the transferability of visual features and the distinctiveness of attribute localization when learning regional features in images. Additionally, they often overlook shared attributes among different objects. Highly discriminative attribute features are crucial for identifying and distinguishing unseen classes. To address these issues, we propose an innovative approach called High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning (HDAFL). HDAFL optimizes visual features by learning attribute features to obtain discriminative visual embeddings. Specifically, HDAFL utilizes multiple convolutional kernels to automatically learn discriminative regions highly correlated with attributes in images, eliminating irrelevant interference in image features. Furthermore, we introduce a Transformer-based attribute discrimination encoder to enhance the discriminative capability among attributes. Simultaneously, the method employs contrastive loss to alleviate dataset biases and enhance the transferability of visual features, facilitating better semantic transfer between seen and unseen classes. Experimental results demonstrate the effectiveness of HDAFL across three widely used datasets.
Fuzzy K-Means Clustering without Cluster Centroids
Apr 07, 2024Fuzzy K-Means clustering is a critical technique in unsupervised data analysis. However, the performance of popular Fuzzy K-Means algorithms is sensitive to the selection of initial cluster centroids and is also affected by noise when updating mean cluster centroids. To address these challenges, this paper proposes a novel Fuzzy K-Means clustering algorithm that entirely eliminates the reliance on cluster centroids, obtaining membership matrices solely through distance matrix computation. This innovation enhances flexibility in distance measurement between sample points, thus improving the algorithm's performance and robustness. The paper also establishes theoretical connections between the proposed model and popular Fuzzy K-Means clustering techniques. Experimental results on several real datasets demonstrate the effectiveness of the algorithm.
Interpretable Multi-View Clustering Based on Anchor Graph Tensor Factorization
Apr 01, 2024The clustering method based on the anchor graph has gained significant attention due to its exceptional clustering performance and ability to process large-scale data. One common approach is to learn bipartite graphs with K-connected components, helping avoid the need for post-processing. However, this method has strict parameter requirements and may not always get K-connected components. To address this issue, an alternative approach is to directly obtain the cluster label matrix by performing non-negative matrix factorization (NMF) on the anchor graph. Nevertheless, existing multi-view clustering methods based on anchor graph factorization lack adequate cluster interpretability for the decomposed matrix and often overlook the inter-view information. We address this limitation by using non-negative tensor factorization to decompose an anchor graph tensor that combines anchor graphs from multiple views. This approach allows us to consider inter-view information comprehensively. The decomposed tensors, namely the sample indicator tensor and the anchor indicator tensor, enhance the interpretability of the factorization. Extensive experiments validate the effectiveness of this method.
One-Step Multi-View Clustering Based on Transition Probability
Mar 03, 2024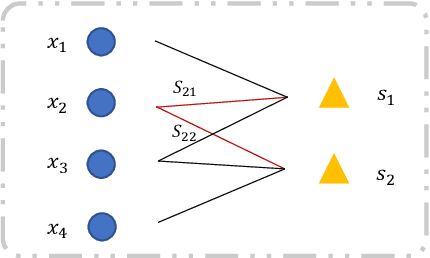

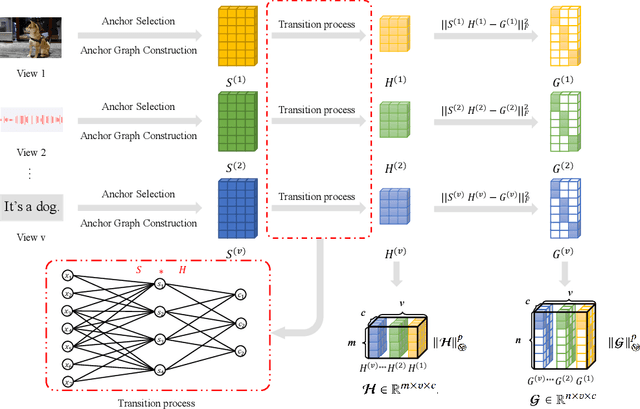
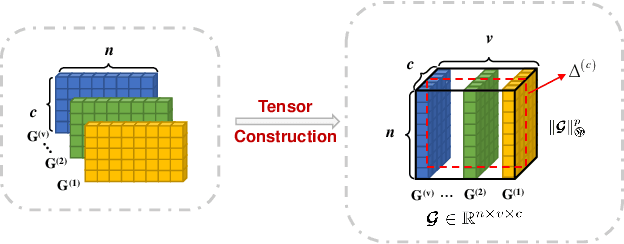
The large-scale multi-view clustering algorithms, based on the anchor graph, have shown promising performance and efficiency and have been extensively explored in recent years. Despite their successes, current methods lack interpretability in the clustering process and do not sufficiently consider the complementary information across different views. To address these shortcomings, we introduce the One-Step Multi-View Clustering Based on Transition Probability (OSMVC-TP). This method adopts a probabilistic approach, which leverages the anchor graph, representing the transition probabilities from samples to anchor points. Our method directly learns the transition probabilities from anchor points to categories, and calculates the transition probabilities from samples to categories, thus obtaining soft label matrices for samples and anchor points, enhancing the interpretability of clustering. Furthermore, to maintain consistency in labels across different views, we apply a Schatten p-norm constraint on the tensor composed of the soft labels. This approach effectively harnesses the complementary information among the views. Extensive experiments have confirmed the effectiveness and robustness of OSMVC-TP.
Label Learning Method Based on Tensor Projection
Feb 26, 2024Multi-view clustering method based on anchor graph has been widely concerned due to its high efficiency and effectiveness. In order to avoid post-processing, most of the existing anchor graph-based methods learn bipartite graphs with connected components. However, such methods have high requirements on parameters, and in some cases it may not be possible to obtain bipartite graphs with clear connected components. To end this, we propose a label learning method based on tensor projection (LLMTP). Specifically, we project anchor graph into the label space through an orthogonal projection matrix to obtain cluster labels directly. Considering that the spatial structure information of multi-view data may be ignored to a certain extent when projected in different views separately, we extend the matrix projection transformation to tensor projection, so that the spatial structure information between views can be fully utilized. In addition, we introduce the tensor Schatten $p$-norm regularization to make the clustering label matrices of different views as consistent as possible. Extensive experiments have proved the effectiveness of the proposed method.
Anchor-free Clustering based on Anchor Graph Factorization
Feb 24, 2024



Anchor-based methods are a pivotal approach in handling clustering of large-scale data. However, these methods typically entail two distinct stages: selecting anchor points and constructing an anchor graph. This bifurcation, along with the initialization of anchor points, significantly influences the overall performance of the algorithm. To mitigate these issues, we introduce a novel method termed Anchor-free Clustering based on Anchor Graph Factorization (AFCAGF). AFCAGF innovates in learning the anchor graph, requiring only the computation of pairwise distances between samples. This process, achievable through straightforward optimization, circumvents the necessity for explicit selection of anchor points. More concretely, our approach enhances the Fuzzy k-means clustering algorithm (FKM), introducing a new manifold learning technique that obviates the need for initializing cluster centers. Additionally, we evolve the concept of the membership matrix between cluster centers and samples in FKM into an anchor graph encompassing multiple anchor points and samples. Employing Non-negative Matrix Factorization (NMF) on this anchor graph allows for the direct derivation of cluster labels, thereby eliminating the requirement for further post-processing steps. To solve the method proposed, we implement an alternating optimization algorithm that ensures convergence. Empirical evaluations on various real-world datasets underscore the superior efficacy of our algorithm compared to traditional approaches.
Rethinking k-means from manifold learning perspective
May 12, 2023Although numerous clustering algorithms have been developed, many existing methods still leverage k-means technique to detect clusters of data points. However, the performance of k-means heavily depends on the estimation of centers of clusters, which is very difficult to achieve an optimal solution. Another major drawback is that it is sensitive to noise and outlier data. In this paper, from manifold learning perspective, we rethink k-means and present a new clustering algorithm which directly detects clusters of data without mean estimation. Specifically, we construct distance matrix between data points by Butterworth filter such that distance between any two data points in the same clusters equals to a small constant, while increasing the distance between other data pairs from different clusters. To well exploit the complementary information embedded in different views, we leverage the tensor Schatten p-norm regularization on the 3rd-order tensor which consists of indicator matrices of different views. Finally, an efficient alternating algorithm is derived to optimize our model. The constructed sequence was proved to converge to the stationary KKT point. Extensive experimental results indicate the superiority of our proposed method.