 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Stylized Trajectory Planning for Autonomous Driving via Diffusion Model
Feb 04, 2026Achieving safe and stylized trajectory planning in complex real-world scenarios remains a critical challenge for autonomous driving systems. This paper proposes the SDD Planner, a diffusion-based framework designed to effectively reconcile safety constraints with driving styles in real time. The framework integrates two core modules: a Multi-Source Style-Aware Encoder, which employs distance-sensitive attention to fuse dynamic agent data and environmental contexts for heterogeneous safety-style perception; and a Style-Guided Dynamic Trajectory Generator, which adaptively modulates priority weights within the diffusion denoising process to generate user-preferred yet safe trajectories. Extensive experiments demonstrate that SDD Planner achieves state-of-the-art performance. On the StyleDrive benchmark, it improves the SM-PDMS metric by 3.9% over WoTE, the strongest baseline. Furthermore, on the NuPlan Test14 and Test14-hard benchmarks, SDD Planner ranks first with overall scores of 91.76 and 80.32, respectively, outperforming leading methods such as PLUTO. Real-vehicle closed-loop tests further confirm that SDD Planner maintains high safety standards while aligning with preset driving styles, validating its practical applicability for real-world deployment.
A Deep Learning Model of Mental Rotation Informed by Interactive VR Experiments
Dec 15, 2025Mental rotation -- the ability to compare objects seen from different viewpoints -- is a fundamental example of mental simulation and spatial world modelling in humans. Here we propose a mechanistic model of human mental rotation, leveraging advances in deep, equivariant, and neuro-symbolic learning. Our model consists of three stacked components: (1) an equivariant neural encoder, taking images as input and producing 3D spatial representations of objects, (2) a neuro-symbolic object encoder, deriving symbolic descriptions of objects from these spatial representations, and (3) a neural decision agent, comparing these symbolic descriptions to prescribe rotation simulations in 3D latent space via a recurrent pathway. Our model design is guided by the abundant experimental literature on mental rotation, which we complemented with experiments in VR where participants could at times manipulate the objects to compare, providing us with additional insights into the cognitive process of mental rotation. Our model captures well the performance, response times and behavior of participants in our and others' experiments. The necessity of each model component is shown through systematic ablations. Our work adds to a recent collection of deep neural models of human spatial reasoning, further demonstrating the potency of integrating deep, equivariant, and symbolic representations to model the human mind.
DEVAL: A Framework for Evaluating and Improving the Derivation Capability of Large Language Models
Nov 18, 2025Assessing the reasoning ability of Large Language Models (LLMs) over data remains an open and pressing research question. Compared with LLMs, human reasoning can derive corresponding modifications to the output based on certain kinds of changes to the input. This reasoning pattern, which relies on abstract rules that govern relationships between changes of data, has not been comprehensively described or evaluated in LLMs. In this paper, we formally define this reasoning pattern as the Derivation Relation (DR) and introduce the concept of Derivation Capability (DC), i.e. applying DR by making the corresponding modification to the output whenever the input takes certain changes. To assess DC, a systematically constructed evaluation framework named DEVAL is proposed and used to evaluate five popular LLMs and one Large Reasoning Model in seven mainstream tasks. The evaluation results show that mainstream LLMs, such as GPT-4o and Claude3.5, exhibit moderate DR recognition capabilities but reveal significant drop-offs on applying DR effectively in problem-solving scenarios. To improve this, we propose a novel prompt engineering approach called Derivation Prompting (DP). It achieves an average improvement of 15.2% in DC for all tested LLMs, outperforming commonly used prompt engineering techniques.
Consistent Assistant Domains Transformer for Source-free Domain Adaptation
Oct 02, 2025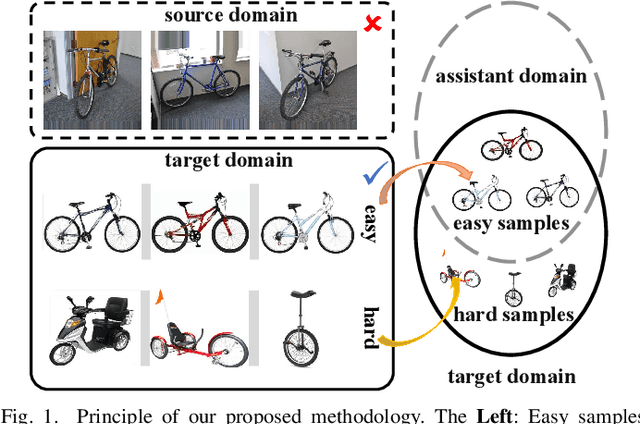
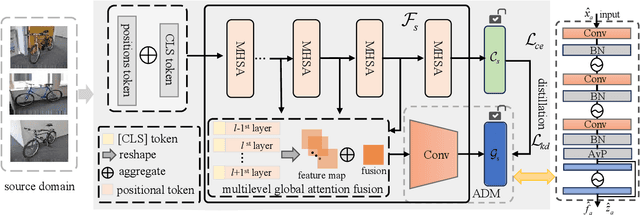
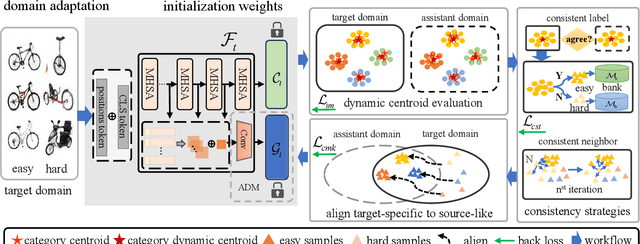
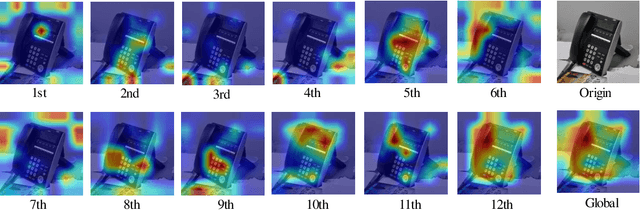
Source-free domain adaptation (SFDA) aims to address the challenge of adapting to a target domain without accessing the source domain directly. However, due to the inaccessibility of source domain data, deterministic invariable features cannot be obtained. Current mainstream methods primarily focus on evaluating invariant features in the target domain that closely resemble those in the source domain, subsequently aligning the target domain with the source domain. However, these methods are susceptible to hard samples and influenced by domain bias. In this paper, we propose a Consistent Assistant Domains Transformer for SFDA, abbreviated as CADTrans, which solves the issue by constructing invariable feature representations of domain consistency. Concretely, we develop an assistant domain module for CADTrans to obtain diversified representations from the intermediate aggregated global attentions, which addresses the limitation of existing methods in adequately representing diversity. Based on assistant and target domains, invariable feature representations are obtained by multiple consistent strategies, which can be used to distinguish easy and hard samples. Finally, to align the hard samples to the corresponding easy samples, we construct a conditional multi-kernel max mean discrepancy (CMK-MMD) strategy to distinguish between samples of the same category and those of different categories. Extensive experiments are conducted on various benchmarks such as Office-31, Office-Home, VISDA-C, and DomainNet-126, proving the significant performance improvements achieved by our proposed approaches. Code is available at https://github.com/RoryShao/CADTrans.git.
Reconstruction of Solar EUV Irradiance Using CaII K Images and SOHO/SEM Data with Bayesian Deep Learning and Uncertainty Quantification
Aug 09, 2025Solar extreme ultraviolet (EUV) irradiance plays a crucial role in heating the Earth's ionosphere, thermosphere, and mesosphere, affecting atmospheric dynamics over varying time scales. Although significant effort has been spent studying short-term EUV variations from solar transient events, there is little work to explore the long-term evolution of the EUV flux over multiple solar cycles. Continuous EUV flux measurements have only been available since 1995, leaving significant gaps in earlier data. In this study, we propose a Bayesian deep learning model, named SEMNet, to fill the gaps. We validate our approach by applying SEMNet to construct SOHO/SEM EUV flux measurements in the period between 1998 and 2014 using CaII K images from the Precision Solar Photometric Telescope. We then extend SEMNet through transfer learning to reconstruct solar EUV irradiance in the period between 1950 and 1960 using CaII K images from the Kodaikanal Solar Observatory. Experimental results show that SEMNet provides reliable predictions along with uncertainty bounds, demonstrating the feasibility of CaII K images as a robust proxy for long-term EUV fluxes. These findings contribute to a better understanding of solar influences on Earth's climate over extended periods.
Ultra3D: Efficient and High-Fidelity 3D Generation with Part Attention
Jul 23, 2025Recent advances in sparse voxel representations have significantly improved the quality of 3D content generation, enabling high-resolution modeling with fine-grained geometry. However, existing frameworks suffer from severe computational inefficiencies due to the quadratic complexity of attention mechanisms in their two-stage diffusion pipelines. In this work, we propose Ultra3D, an efficient 3D generation framework that significantly accelerates sparse voxel modeling without compromising quality. Our method leverages the compact VecSet representation to efficiently generate a coarse object layout in the first stage, reducing token count and accelerating voxel coordinate prediction. To refine per-voxel latent features in the second stage, we introduce Part Attention, a geometry-aware localized attention mechanism that restricts attention computation within semantically consistent part regions. This design preserves structural continuity while avoiding unnecessary global attention, achieving up to 6.7x speed-up in latent generation. To support this mechanism, we construct a scalable part annotation pipeline that converts raw meshes into part-labeled sparse voxels. Extensive experiments demonstrate that Ultra3D supports high-resolution 3D generation at 1024 resolution and achieves state-of-the-art performance in both visual fidelity and user preference.
Correcting Noisy Multilabel Predictions: Modeling Label Noise through Latent Space Shifts
Feb 20, 2025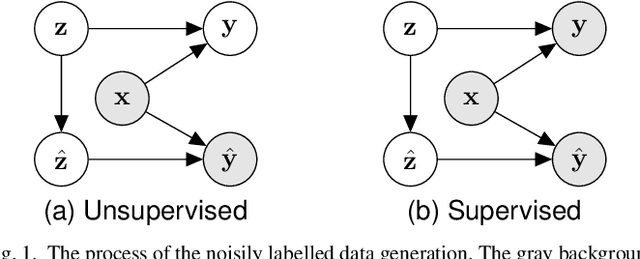



Noise in data appears to be inevitable in most real-world machine learning applications and would cause severe overfitting problems. Not only can data features contain noise, but labels are also prone to be noisy due to human input. In this paper, rather than noisy label learning in multiclass classifications, we instead focus on the less explored area of noisy label learning for multilabel classifications. Specifically, we investigate the post-correction of predictions generated from classifiers learned with noisy labels. The reasons are two-fold. Firstly, this approach can directly work with the trained models to save computational resources. Secondly, it could be applied on top of other noisy label correction techniques to achieve further improvements. To handle this problem, we appeal to deep generative approaches that are possible for uncertainty estimation. Our model posits that label noise arises from a stochastic shift in the latent variable, providing a more robust and beneficial means for noisy learning. We develop both unsupervised and semi-supervised learning methods for our model. The extensive empirical study presents solid evidence to that our approach is able to consistently improve the independent models and performs better than a number of existing methods across various noisy label settings. Moreover, a comprehensive empirical analysis of the proposed method is carried out to validate its robustness, including sensitivity analysis and an ablation study, among other elements.
Heterogeneity-aware Personalized Federated Learning via Adaptive Dual-Agent Reinforcement Learning
Jan 28, 2025



Federated Learning (FL) empowers multiple clients to collaboratively train machine learning models without sharing local data, making it highly applicable in heterogeneous Internet of Things (IoT) environments. However, intrinsic heterogeneity in clients' model architectures and computing capabilities often results in model accuracy loss and the intractable straggler problem, which significantly impairs training effectiveness. To tackle these challenges, this paper proposes a novel Heterogeneity-aware Personalized Federated Learning method, named HAPFL, via multi-level Reinforcement Learning (RL) mechanisms. HAPFL optimizes the training process by incorporating three strategic components: 1) An RL-based heterogeneous model allocation mechanism. The parameter server employs a Proximal Policy Optimization (PPO)-based RL agent to adaptively allocate appropriately sized, differentiated models to clients based on their performance, effectively mitigating performance disparities. 2) An RL-based training intensity adjustment scheme. The parameter server leverages another PPO-based RL agent to dynamically fine-tune the training intensity for each client to further enhance training efficiency and reduce straggling latency. 3) A knowledge distillation-based mutual learning mechanism. Each client deploys both a heterogeneous local model and a homogeneous lightweight model named LiteModel, where these models undergo mutual learning through knowledge distillation. This uniform LiteModel plays a pivotal role in aggregating and sharing global knowledge, significantly enhancing the effectiveness of personalized local training. Experimental results across multiple benchmark datasets demonstrate that HAPFL not only achieves high accuracy but also substantially reduces the overall training time by 20.9%-40.4% and decreases straggling latency by 19.0%-48.0% compared to existing solutions.
Monotonic Learning in the PAC Framework: A New Perspective
Jan 09, 2025Monotone learning refers to learning processes in which expected performance consistently improves as more training data is introduced. Non-monotone behavior of machine learning has been the topic of a series of recent works, with various proposals that ensure monotonicity by applying transformations or wrappers on learning algorithms. In this work, from a different perspective, we tackle the topic of monotone learning within the framework of Probably Approximately Correct (PAC) learning theory. Following the mechanism that estimates sample complexity of a PAC-learnable problem, we derive a performance lower bound for that problem, and prove the monotonicity of that bound as the sample sizes increase. By calculating the lower bound distribution, we are able to prove that given a PAC-learnable problem with a hypothesis space that is either of finite size or of finite VC dimension, any learning algorithm based on Empirical Risk Minimization (ERM) is monotone if training samples are independent and identically distributed (i.i.d.). We further carry out an experiment on two concrete machine learning problems, one of which has a finite hypothesis set, and the other of finite VC dimension, and compared the experimental data for the empirical risk distributions with the estimated theoretical bound. The results of the comparison have confirmed the monotonicity of learning for the two PAC-learnable problems.
Deep Computer Vision for Solar Physics Big Data: Opportunities and Challenges
Sep 07, 2024With recent missions such as advanced space-based observatories like the Solar Dynamics Observatory (SDO) and Parker Solar Probe, and ground-based telescopes like the Daniel K. Inouye Solar Telescope (DKIST), the volume, velocity, and variety of data have made solar physics enter a transformative era as solar physics big data (SPBD). With the recent advancement of deep computer vision, there are new opportunities in SPBD for tackling problems that were previously unsolvable. However, there are new challenges arising due to the inherent characteristics of SPBD and deep computer vision models. This vision paper presents an overview of the different types of SPBD, explores new opportunities in applying deep computer vision to SPBD, highlights the unique challenges, and outlines several potential future research directions.