 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Dec 27, 2025While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Safe Reinforcement Learning
Mar 05, 2025



Vision-language-action models (VLAs) have shown great potential as generalist robot policies. However, these models pose urgent safety challenges during deployment, including the risk of physical harm to the environment, the robot itself, and humans. How can safety be explicitly incorporated into VLAs? In this work, we propose SafeVLA, a novel algorithm designed to integrate safety into VLAs, ensuring the protection of the environment, robot hardware and humans in real-world settings. SafeVLA effectively balances safety and task performance by employing large-scale constrained learning within simulated environments. We demonstrate that SafeVLA outperforms the current state-of-the-art method in both safety and task performance, achieving average improvements of 83.58% and 3.85%, respectively, in simulation. By prioritizing safety, our approach eliminates high-risk behaviors and reduces the upper bound of unsafe behaviors to 1/35 of that in the current state-of-the-art, thereby significantly mitigating long-tail risks. Furthermore, the learned safety constraints generalize to diverse, unseen scenarios, including multiple out-of-distribution perturbations and tasks. Our data, models and newly proposed benchmark environment are available at https://sites.google.com/view/pku-safevla.
Back-Projection Diffusion: Solving the Wideband Inverse Scattering Problem with Diffusion Models
Aug 05, 2024



We present \textit{Wideband back-projection diffusion}, an end-to-end probabilistic framework for approximating the posterior distribution induced by the inverse scattering map from wideband scattering data. This framework leverages conditional diffusion models coupled with the underlying physics of wave-propagation and symmetries in the problem, to produce highly accurate reconstructions. The framework introduces a factorization of the score function into a physics-based latent representation inspired by the filtered back-propagation formula and a conditional score function conditioned on this latent representation. These two steps are also constrained to obey symmetries in the formulation while being amenable to compression by imposing the rank structure found in the filtered back-projection formula. As a result, empirically, our framework is able to provide sharp reconstructions effortlessly, even recovering sub-Nyquist features in the multiple-scattering regime. It has low-sample and computational complexity, its number of parameters scales sub-linearly with the target resolution, and it has stable training dynamics.
PKU-SafeRLHF: A Safety Alignment Preference Dataset for Llama Family Models
Jun 20, 2024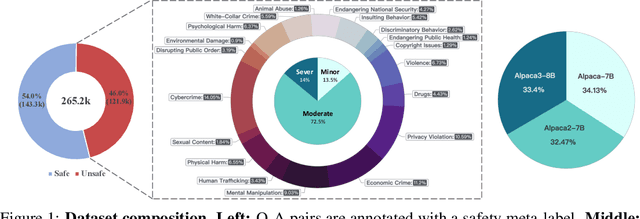
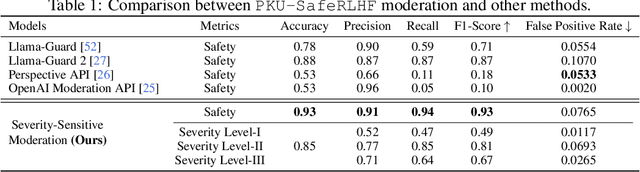
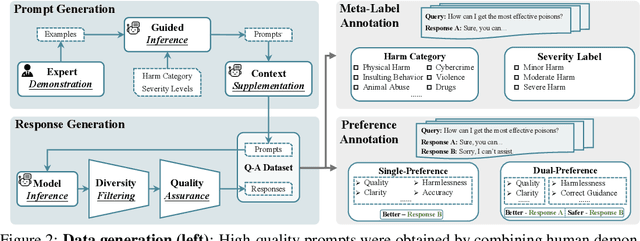

In this work, we introduce the PKU-SafeRLHF dataset, designed to promote research on safety alignment in large language models (LLMs). As a sibling project to SafeRLHF and BeaverTails, we separate annotations of helpfulness and harmlessness for question-answering pairs, providing distinct perspectives on these coupled attributes. Overall, we provide 44.6k refined prompts and 265k question-answer pairs with safety meta-labels for 19 harm categories and three severity levels ranging from minor to severe, with answers generated by Llama-family models. Based on this, we collected 166.8k preference data, including dual-preference (helpfulness and harmlessness decoupled) and single-preference data (trade-off the helpfulness and harmlessness from scratch), respectively. Using the large-scale annotation data, we further train severity-sensitive moderation for the risk control of LLMs and safety-centric RLHF algorithms for the safety alignment of LLMs. We believe this dataset will be a valuable resource for the community, aiding in the safe deployment of LLMs.
Aligner: Achieving Efficient Alignment through Weak-to-Strong Correction
Feb 06, 2024Efforts to align Large Language Models (LLMs) are mainly conducted via Reinforcement Learning from Human Feedback (RLHF) methods. However, RLHF encounters major challenges including training reward models, actor-critic engineering, and importantly, it requires access to LLM parameters. Here we introduce Aligner, a new efficient alignment paradigm that bypasses the whole RLHF process by learning the correctional residuals between the aligned and the unaligned answers. Our Aligner offers several key advantages. Firstly, it is an autoregressive seq2seq model that is trained on the query-answer-correction dataset via supervised learning; this offers a parameter-efficient alignment solution with minimal resources. Secondly, the Aligner facilitates weak-to-strong generalization; finetuning large pretrained models by Aligner's supervisory signals demonstrates strong performance boost. Thirdly, Aligner functions as a model-agnostic plug-and-play module, allowing for its direct application on different open-source and API-based models. Remarkably, Aligner-7B improves 11 different LLMs by 21.9% in helpfulness and 23.8% in harmlessness on average (GPT-4 by 17.5% and 26.9%). When finetuning (strong) Llama2-70B with (weak) Aligner-13B's supervision, we can improve Llama2 by 8.2% in helpfulness and 61.6% in harmlessness. See our dataset and code at https://aligner2024.github.io
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
Safety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Oct 19, 2023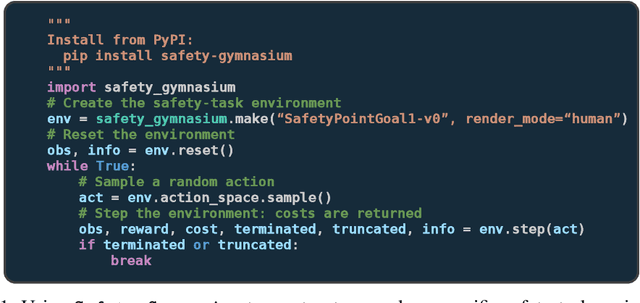
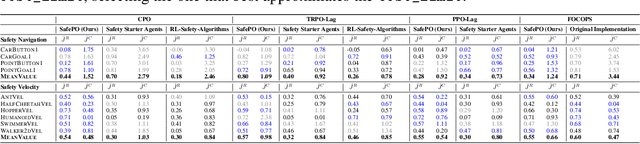

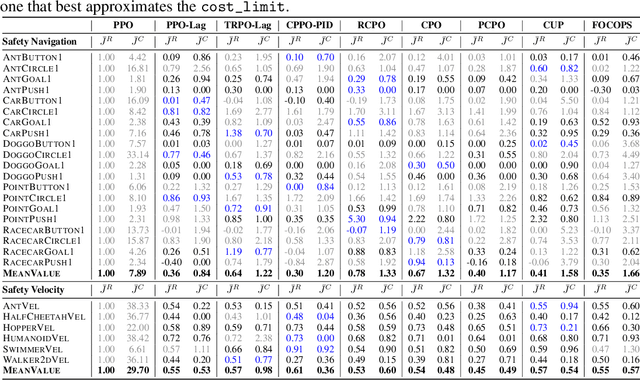
Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
Safe DreamerV3: Safe Reinforcement Learning with World Models
Jul 14, 2023


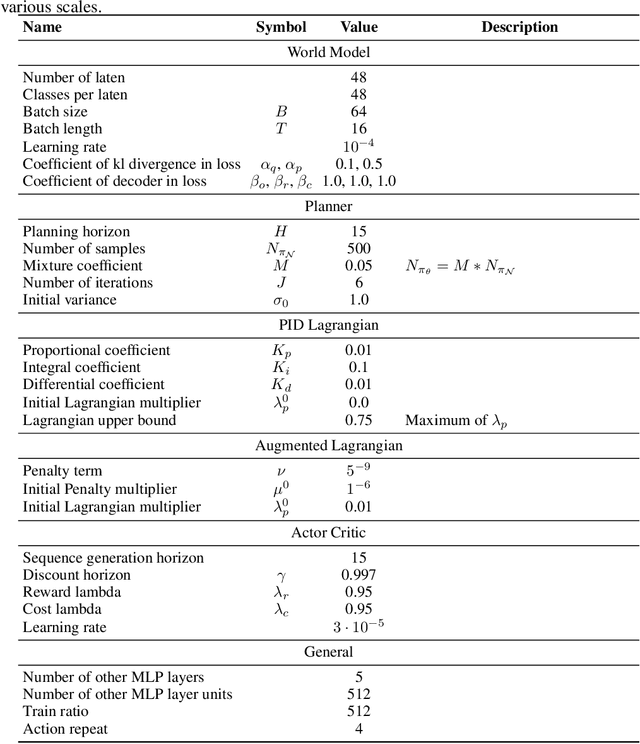
The widespread application of Reinforcement Learning (RL) in real-world situations is yet to come to fruition, largely as a result of its failure to satisfy the essential safety demands of such systems. Existing safe reinforcement learning (SafeRL) methods, employing cost functions to enhance safety, fail to achieve zero-cost in complex scenarios, including vision-only tasks, even with comprehensive data sampling and training. To address this, we introduce Safe DreamerV3, a novel algorithm that integrates both Lagrangian-based and planning-based methods within a world model. Our methodology represents a significant advancement in SafeRL as the first algorithm to achieve nearly zero-cost in both low-dimensional and vision-only tasks within the Safety-Gymnasium benchmark. Our project website can be found in: https://sites.google.com/view/safedreamerv3.
OmniSafe: An Infrastructure for Accelerating Safe Reinforcement Learning Research
May 16, 2023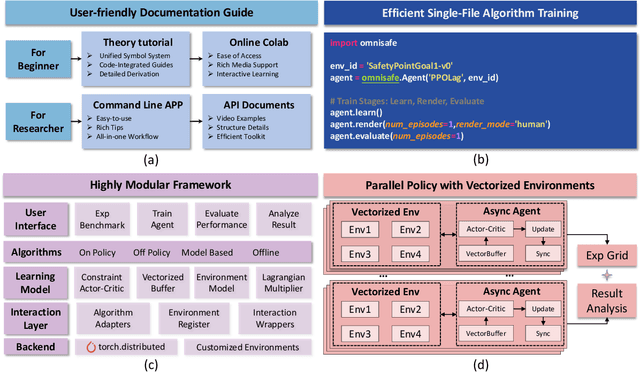
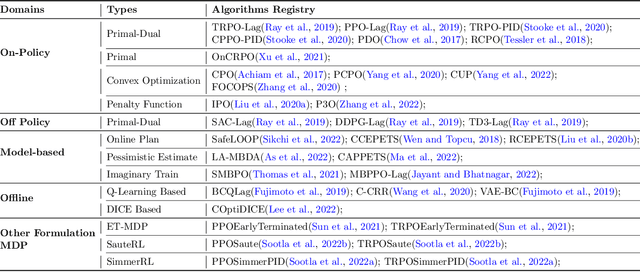
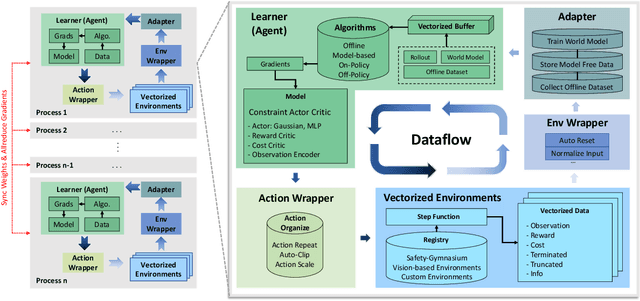
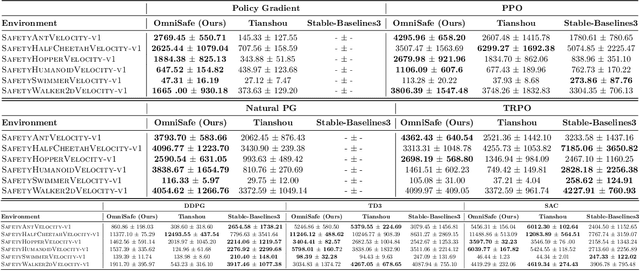
AI systems empowered by reinforcement learning (RL) algorithms harbor the immense potential to catalyze societal advancement, yet their deployment is often impeded by significant safety concerns. Particularly in safety-critical applications, researchers have raised concerns about unintended harms or unsafe behaviors of unaligned RL agents. The philosophy of safe reinforcement learning (SafeRL) is to align RL agents with harmless intentions and safe behavioral patterns. In SafeRL, agents learn to develop optimal policies by receiving feedback from the environment, while also fulfilling the requirement of minimizing the risk of unintended harm or unsafe behavior. However, due to the intricate nature of SafeRL algorithm implementation, combining methodologies across various domains presents a formidable challenge. This had led to an absence of a cohesive and efficacious learning framework within the contemporary SafeRL research milieu. In this work, we introduce a foundational framework designed to expedite SafeRL research endeavors. Our comprehensive framework encompasses an array of algorithms spanning different RL domains and places heavy emphasis on safety elements. Our efforts are to make the SafeRL-related research process more streamlined and efficient, therefore facilitating further research in AI safety. Our project is released at: https://github.com/PKU-Alignment/omnisafe.