 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Didn't Have to Say It like That: Subliminal Learning from Faithful Paraphrases
Mar 10, 2026When language models are trained on synthetic data, they (student model) can covertly acquire behavioral traits from the data-generating model (teacher model). Subliminal learning refers to the transmission of traits from a teacher to a student model via training on data unrelated to those traits. Prior work demonstrated this in the training domains of number sequences, code, and math Chain-of-Thought traces including transmission of misaligned behaviors. We investigate whether transmission occurs through natural language paraphrases with fixed semantic content, and whether content explicitly contradicting the teacher's preference can block it. We find that training on paraphrases from a teacher system-prompted to love a particular animal increases a student's preference for that animal by up to 19 percentage points. This occurs when paraphrased content is semantically unrelated to the animal, or even when it explicitly expresses dislike. The transmission succeeds despite aggressive filtering to ensure paraphrase fidelity. This raises concerns for pipelines where models generate their own training data: content-based inspection cannot detect such transmission, and even preference-contradicting content fails to prevent it.
Self-Improvement as Coherence Optimization: A Theoretical Account
Jan 20, 2026Can language models improve their accuracy without external supervision? Methods such as debate, bootstrap, and internal coherence maximization achieve this surprising feat, even matching golden finetuning performance. Yet why they work remains theoretically unclear. We show that they are all special cases of coherence optimization: finding a context-to-behavior mapping that's most compressible and jointly predictable. We prove that coherence optimization is equivalent to description-length regularization, and that among all such regularization schemes, it is optimal for semi-supervised learning when the regularizer is derived from a pretrained model. Our theory, supported by preliminary experiments, explains why feedback-free self-improvement works and predicts when it should succeed or fail.
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Jun 08, 2025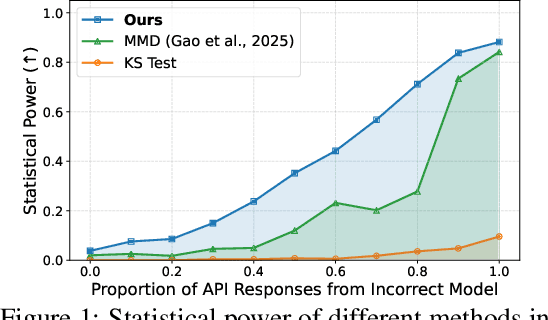

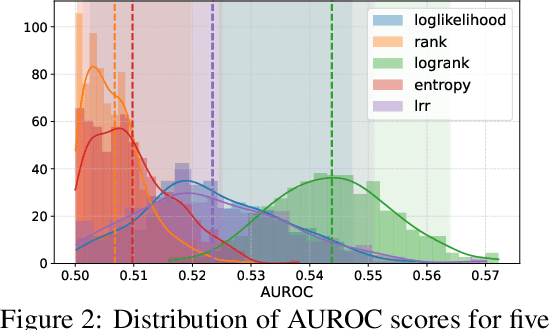
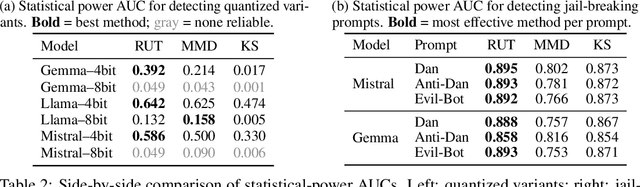
As API access becomes a primary interface to large language models (LLMs), users often interact with black-box systems that offer little transparency into the deployed model. To reduce costs or maliciously alter model behaviors, API providers may discreetly serve quantized or fine-tuned variants, which can degrade performance and compromise safety. Detecting such substitutions is difficult, as users lack access to model weights and, in most cases, even output logits. To tackle this problem, we propose a rank-based uniformity test that can verify the behavioral equality of a black-box LLM to a locally deployed authentic model. Our method is accurate, query-efficient, and avoids detectable query patterns, making it robust to adversarial providers that reroute or mix responses upon the detection of testing attempts. We evaluate the approach across diverse threat scenarios, including quantization, harmful fine-tuning, jailbreak prompts, and full model substitution, showing that it consistently achieves superior statistical power over prior methods under constrained query budgets.
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Dec 20, 2024



Reinforcement learning from human feedback (RLHF) has proven effective in enhancing the instruction-following capabilities of large language models; however, it remains underexplored in the cross-modality domain. As the number of modalities increases, aligning all-modality models with human intentions -- such as instruction following -- becomes a pressing challenge. In this work, we make the first attempt to fine-tune all-modality models (i.e. input and output with any modality, also named any-to-any models) using human preference data across all modalities (including text, image, audio, and video), ensuring its behavior aligns with human intentions. This endeavor presents several challenges. First, there is no large-scale all-modality human preference data in existing open-source resources, as most datasets are limited to specific modalities, predominantly text and image. Secondly, the effectiveness of binary preferences in RLHF for post-training alignment in complex all-modality scenarios remains an unexplored area. Finally, there is a lack of a systematic framework to evaluate the capabilities of all-modality models, particularly regarding modality selection and synergy. To address these challenges, we propose the align-anything framework, which includes meticulously annotated 200k all-modality human preference data. Then, we introduce an alignment method that learns from unified language feedback, effectively capturing complex modality-specific human preferences and enhancing the model's instruction-following capabilities. Furthermore, to assess performance improvements in all-modality models after post-training alignment, we construct a challenging all-modality capability evaluation framework -- eval-anything. All data, models, and code frameworks have been open-sourced for the community. For more details, please refer to https://github.com/PKU-Alignment/align-anything.
Representative Social Choice: From Learning Theory to AI Alignment
Oct 31, 2024Social choice theory is the study of preference aggregation across a population, used both in mechanism design for human agents and in the democratic alignment of language models. In this study, we propose the representative social choice framework for the modeling of democratic representation in collective decisions, where the number of issues and individuals are too large for mechanisms to consider all preferences directly. These scenarios are widespread in real-world decision-making processes, such as jury trials, indirect elections, legislation processes, corporate governance, and, more recently, language model alignment. In representative social choice, the population is represented by a finite sample of individual-issue pairs based on which social choice decisions are made. We show that many of the deepest questions in representative social choice can be naturally formulated as statistical learning problems, and prove the generalization properties of social choice mechanisms using the theory of machine learning. We further formulate axioms for representative social choice, and prove Arrow-like impossibility theorems with new combinatorial tools of analysis. Our framework introduces the representative approach to social choice, opening up research directions at the intersection of social choice, learning theory, and AI alignment.
ProgressGym: Alignment with a Millennium of Moral Progress
Jun 28, 2024



Frontier AI systems, including large language models (LLMs), hold increasing influence over the epistemology of human users. Such influence can reinforce prevailing societal values, potentially contributing to the lock-in of misguided moral beliefs and, consequently, the perpetuation of problematic moral practices on a broad scale. We introduce progress alignment as a technical solution to mitigate this imminent risk. Progress alignment algorithms learn to emulate the mechanics of human moral progress, thereby addressing the susceptibility of existing alignment methods to contemporary moral blindspots. To empower research in progress alignment, we introduce ProgressGym, an experimental framework allowing the learning of moral progress mechanics from history, in order to facilitate future progress in real-world moral decisions. Leveraging 9 centuries of historical text and 18 historical LLMs, ProgressGym enables codification of real-world progress alignment challenges into concrete benchmarks. Specifically, we introduce three core challenges: tracking evolving values (PG-Follow), preemptively anticipating moral progress (PG-Predict), and regulating the feedback loop between human and AI value shifts (PG-Coevolve). Alignment methods without a temporal dimension are inapplicable to these tasks. In response, we present lifelong and extrapolative algorithms as baseline methods of progress alignment, and build an open leaderboard soliciting novel algorithms and challenges. The framework and the leaderboard are available at https://github.com/PKU-Alignment/ProgressGym and https://huggingface.co/spaces/PKU-Alignment/ProgressGym-LeaderBoard respectively.
PKU-SafeRLHF: A Safety Alignment Preference Dataset for Llama Family Models
Jun 20, 2024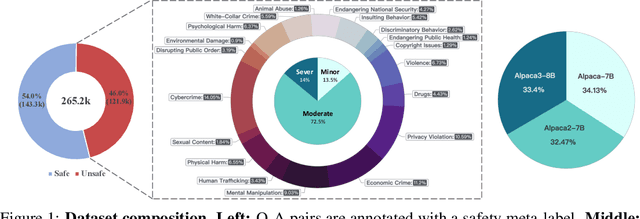
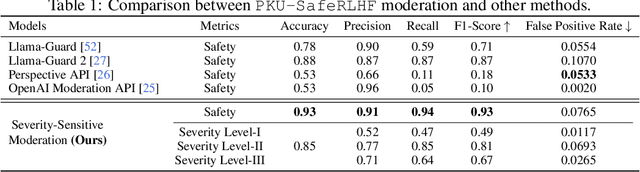
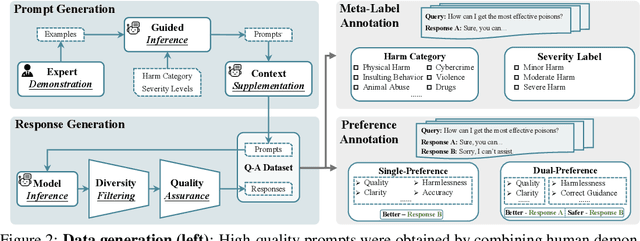

In this work, we introduce the PKU-SafeRLHF dataset, designed to promote research on safety alignment in large language models (LLMs). As a sibling project to SafeRLHF and BeaverTails, we separate annotations of helpfulness and harmlessness for question-answering pairs, providing distinct perspectives on these coupled attributes. Overall, we provide 44.6k refined prompts and 265k question-answer pairs with safety meta-labels for 19 harm categories and three severity levels ranging from minor to severe, with answers generated by Llama-family models. Based on this, we collected 166.8k preference data, including dual-preference (helpfulness and harmlessness decoupled) and single-preference data (trade-off the helpfulness and harmlessness from scratch), respectively. Using the large-scale annotation data, we further train severity-sensitive moderation for the risk control of LLMs and safety-centric RLHF algorithms for the safety alignment of LLMs. We believe this dataset will be a valuable resource for the community, aiding in the safe deployment of LLMs.
Language Models Resist Alignment
Jun 10, 2024



Large language models (LLMs) may exhibit undesirable behaviors. Recent efforts have focused on aligning these models to prevent harmful generation. Despite these efforts, studies have shown that even a well-conducted alignment process can be easily circumvented, whether intentionally or accidentally. Do alignment fine-tuning have robust effects on models, or are merely superficial? In this work, we answer this question through both theoretical and empirical means. Empirically, we demonstrate the elasticity of post-alignment models, i.e., the tendency to revert to the behavior distribution formed during the pre-training phase upon further fine-tuning. Using compression theory, we formally derive that such fine-tuning process \textit{disproportionately} undermines alignment compared to pre-training, potentially by orders of magnitude. We conduct experimental validations to confirm the presence of elasticity across models of varying types and sizes. Specifically, we find that model performance declines rapidly before reverting to the pre-training distribution, after which the rate of decline drops significantly. We further reveal that elasticity positively correlates with increased model size and the expansion of pre-training data. Our discovery signifies the importance of taming the inherent elasticity of LLMs, thereby overcoming the resistance of LLMs to alignment finetuning.
Rethinking Information Structures in RLHF: Reward Generalization from a Graph Theory Perspective
Feb 20, 2024There is a trilemma in reinforcement learning from human feedback (RLHF): the incompatibility between highly diverse contexts, low labeling cost, and reliable alignment performance. Here we aim to mitigate such incompatibility through the design of dataset information structures during reward modeling, and meanwhile propose new, generalizable methods of analysis that have wider applications, including potentially shedding light on goal misgeneralization. Specifically, we first reexamine the RLHF process and propose a theoretical framework portraying it as an autoencoding process over text distributions. Our framework formalizes the RLHF objective of ensuring distributional consistency between human preference and large language model (LLM) behavior. Based on this framework, we introduce a new method to model generalization in the reward modeling stage of RLHF, the induced Bayesian network (IBN). Drawing from random graph theory and causal analysis, it enables empirically grounded derivation of generalization error bounds, a key improvement over classical methods of generalization analysis. An insight from our analysis is the superiority of the tree-based information structure in reward modeling, compared to chain-based baselines in conventional RLHF methods. We derive that in complex contexts with limited data, the tree-based reward model (RM) induces up to $\Theta(\log n/\log\log n)$ times less variance than chain-based RM where $n$ is the dataset size. As validation, we demonstrate that on three NLP tasks, the tree-based RM achieves 65% win rate on average against chain-based baselines. Looking ahead, we hope to extend the IBN analysis to help understand the phenomenon of goal misgeneralization.
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.