 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Polarization Modulation: Enabling CSI-Free DCO-OFDM over Dynamic OWC Channels
Mar 18, 2026In dynamically varying optical wireless communication (OWC) links, conventional quadrature amplitude modulation (QAM) in optical orthogonal frequency-division multiplexing (OFDM) requires frequent channel estimation and equalization, incurring pilot overhead and processing latency. This paper proposes a virtual polarization modulation (VPM)-based direct-current-biased optical OFDM (DCO-OFDM) scheme that maps each data symbol onto the three-dimensional Stokes space and places its corresponding Jones vector across two adjacent OFDM subcarriers. Using a rotation-based analytical framework, closed-form symbol error rate (SER) expressions are derived for arbitrary spherical constellations, along with upper and lower bounds and high signal-to-noise ratio (SNR) approximations. The framework is further extended to practical OWC scenarios with frequency-selective channels and atmospheric turbulence. Monte Carlo (MC) simulations validate the theoretical results. The results show that under practical OWC impairments, VPM outperforms QAM with least-squares (LS) channel estimation and minimum mean square error (MMSE) equalization. At a target SER of $10^{-5}$, 16-VPM achieves SNR gains of approximately 7.5 dB and 4 dB over equalized 16-QAM and 8-QAM, respectively, in frequency-selective channels, and a 6 dB advantage over equalized 16-QAM under atmospheric turbulence. By eliminating the need for channel state information, the proposed VPM-based DCO-OFDM provides a robust and low-latency solution for dynamic OWC links.
FedRD: Reducing Divergences for Generalized Federated Learning via Heterogeneity-aware Parameter Guidance
Jan 28, 2026Heterogeneous federated learning (HFL) aims to ensure effective and privacy-preserving collaboration among different entities. As newly joined clients require significant adjustments and additional training to align with the existing system, the problem of generalizing federated learning models to unseen clients under heterogeneous data has become progressively crucial. Consequently, we highlight two unsolved challenging issues in federated domain generalization: Optimization Divergence and Performance Divergence. To tackle the above challenges, we propose FedRD, a novel heterogeneity-aware federated learning algorithm that collaboratively utilizes parameter-guided global generalization aggregation and local debiased classification to reduce divergences, aiming to obtain an optimal global model for participating and unseen clients. Extensive experiments on public multi-domain datasets demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
FedCCA: Client-Centric Adaptation against Data Heterogeneity in Federated Learning on IoT Devices
Jan 25, 2026With the rapid development of the Internet of Things (IoT), AI model training on private data such as human sensing data is highly desired. Federated learning (FL) has emerged as a privacy-preserving distributed training framework for this purpuse. However, the data heterogeneity issue among IoT devices can significantly degrade the model performance and convergence speed in FL. Existing approaches limit in fixed client selection and aggregation on cloud server, making the privacy-preserving extraction of client-specific information during local training challenging. To this end, we propose Client-Centric Adaptation federated learning (FedCCA), an algorithm that optimally utilizes client-specific knowledge to learn a unique model for each client through selective adaptation, aiming to alleviate the influence of data heterogeneity. Specifically, FedCCA employs dynamic client selection and adaptive aggregation based on the additional client-specific encoder. To enhance multi-source knowledge transfer, we adopt an attention-based global aggregation strategy. We conducted extensive experiments on diverse datasets to assess the efficacy of FedCCA. The experimental results demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
Mitigating Deceptive Alignment via Self-Monitoring
May 24, 2025Modern large language models rely on chain-of-thought (CoT) reasoning to achieve impressive performance, yet the same mechanism can amplify deceptive alignment, situations in which a model appears aligned while covertly pursuing misaligned goals. Existing safety pipelines treat deception as a black-box output to be filtered post-hoc, leaving the model free to scheme during its internal reasoning. We ask: Can deception be intercepted while the model is thinking? We answer this question, the first framework that embeds a Self-Monitor inside the CoT process itself, named CoT Monitor+. During generation, the model produces (i) ordinary reasoning steps and (ii) an internal self-evaluation signal trained to flag and suppress misaligned strategies. The signal is used as an auxiliary reward in reinforcement learning, creating a feedback loop that rewards honest reasoning and discourages hidden goals. To study deceptive alignment systematically, we introduce DeceptionBench, a five-category benchmark that probes covert alignment-faking, sycophancy, etc. We evaluate various LLMs and show that unrestricted CoT roughly aggravates the deceptive tendency. In contrast, CoT Monitor+ cuts deceptive behaviors by 43.8% on average while preserving task accuracy. Further, when the self-monitor signal replaces an external weak judge in RL fine-tuning, models exhibit substantially fewer obfuscated thoughts and retain transparency. Our project website can be found at cot-monitor-plus.github.io
Stream Aligner: Efficient Sentence-Level Alignment via Distribution Induction
Jan 09, 2025The rapid advancement of large language models (LLMs) has led to significant improvements in their capabilities, but also to increased concerns about their alignment with human values and intentions. Current alignment strategies, including adaptive training and inference-time methods, have demonstrated potential in this area. However, these approaches still struggle to balance deployment complexity and capability across various tasks and difficulties. In this work, we introduce the Streaming Distribution Induce Aligner (Stream Aligner), a novel alignment paradigm that combines efficiency with enhanced performance in various tasks throughout the generation process. Stream Aligner achieves dynamic sentence-level correction by using a small model to learn the preferences of the suffix sentence, iteratively correcting the suffix sentence output by the upstream model, and then using the corrected sentence to replace the suffix sentence in subsequent generations. Compared to Aligner, our experiments demonstrate that Stream Aligner reduces reliance on the capabilities of additional models, enhances the reasoning abilities of LLMs, and decreases latency during user interaction. Specifically, Stream Aligner-2B model has achieved an improvement of 76.1% in helpfulness, 36.0% in harmlessness on the tested Llama2-70B-chat model, and Stream Aligner-8B has achieved an improvement of 3.5% on the math ability of the tested Llama3-70B-Instruct model.
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Dec 20, 2024



Reinforcement learning from human feedback (RLHF) has proven effective in enhancing the instruction-following capabilities of large language models; however, it remains underexplored in the cross-modality domain. As the number of modalities increases, aligning all-modality models with human intentions -- such as instruction following -- becomes a pressing challenge. In this work, we make the first attempt to fine-tune all-modality models (i.e. input and output with any modality, also named any-to-any models) using human preference data across all modalities (including text, image, audio, and video), ensuring its behavior aligns with human intentions. This endeavor presents several challenges. First, there is no large-scale all-modality human preference data in existing open-source resources, as most datasets are limited to specific modalities, predominantly text and image. Secondly, the effectiveness of binary preferences in RLHF for post-training alignment in complex all-modality scenarios remains an unexplored area. Finally, there is a lack of a systematic framework to evaluate the capabilities of all-modality models, particularly regarding modality selection and synergy. To address these challenges, we propose the align-anything framework, which includes meticulously annotated 200k all-modality human preference data. Then, we introduce an alignment method that learns from unified language feedback, effectively capturing complex modality-specific human preferences and enhancing the model's instruction-following capabilities. Furthermore, to assess performance improvements in all-modality models after post-training alignment, we construct a challenging all-modality capability evaluation framework -- eval-anything. All data, models, and code frameworks have been open-sourced for the community. For more details, please refer to https://github.com/PKU-Alignment/align-anything.
FedAli: Personalized Federated Learning with Aligned Prototypes through Optimal Transport
Nov 15, 2024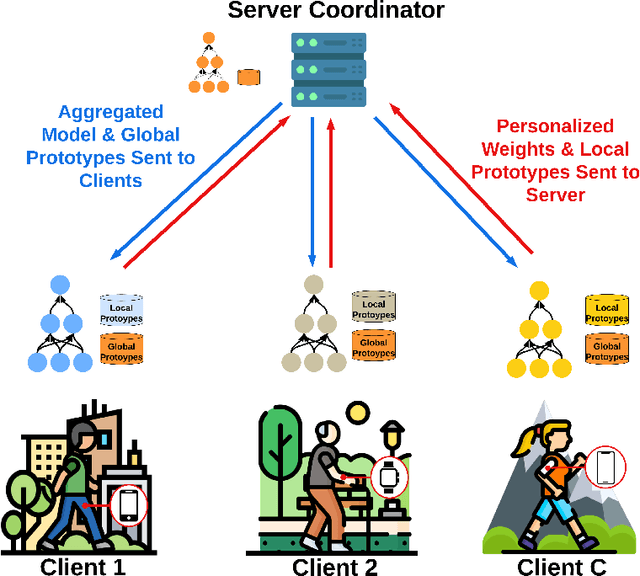
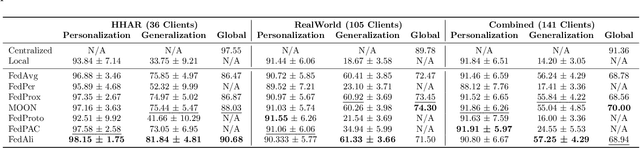
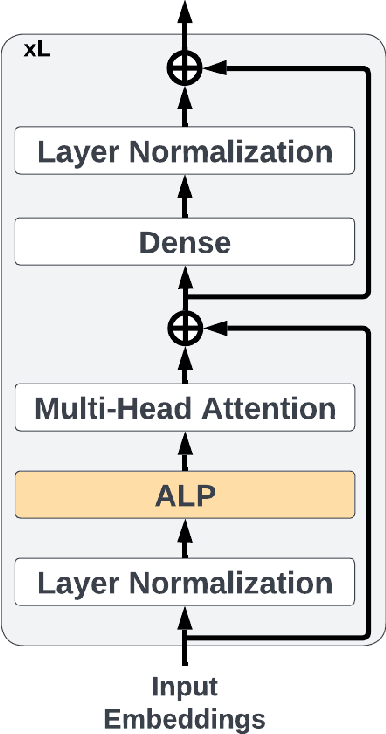

Federated Learning (FL) enables collaborative, personalized model training across multiple devices without sharing raw data, making it ideal for pervasive computing applications that optimize user-centric performances in diverse environments. However, data heterogeneity among clients poses a significant challenge, leading to inconsistencies among trained client models and reduced performance. To address this, we introduce the Alignment with Prototypes (ALP) layers, which align incoming embeddings closer to learnable prototypes through an optimal transport plan. During local training, the ALP layer updates local prototypes and aligns embeddings toward global prototypes aggregated from all clients using our novel FL framework, Federated Alignment (FedAli). For model inferences, embeddings are guided toward local prototypes to better reflect the client's local data distribution. We evaluate FedAli on heterogeneous sensor-based human activity recognition and vision benchmark datasets, demonstrating that it outperforms existing FL strategies. We publicly release our source code to facilitate reproducibility and furthered research.
Language Models Resist Alignment
Jun 10, 2024



Large language models (LLMs) may exhibit undesirable behaviors. Recent efforts have focused on aligning these models to prevent harmful generation. Despite these efforts, studies have shown that even a well-conducted alignment process can be easily circumvented, whether intentionally or accidentally. Do alignment fine-tuning have robust effects on models, or are merely superficial? In this work, we answer this question through both theoretical and empirical means. Empirically, we demonstrate the elasticity of post-alignment models, i.e., the tendency to revert to the behavior distribution formed during the pre-training phase upon further fine-tuning. Using compression theory, we formally derive that such fine-tuning process \textit{disproportionately} undermines alignment compared to pre-training, potentially by orders of magnitude. We conduct experimental validations to confirm the presence of elasticity across models of varying types and sizes. Specifically, we find that model performance declines rapidly before reverting to the pre-training distribution, after which the rate of decline drops significantly. We further reveal that elasticity positively correlates with increased model size and the expansion of pre-training data. Our discovery signifies the importance of taming the inherent elasticity of LLMs, thereby overcoming the resistance of LLMs to alignment finetuning.
Rethinking Information Structures in RLHF: Reward Generalization from a Graph Theory Perspective
Feb 20, 2024There is a trilemma in reinforcement learning from human feedback (RLHF): the incompatibility between highly diverse contexts, low labeling cost, and reliable alignment performance. Here we aim to mitigate such incompatibility through the design of dataset information structures during reward modeling, and meanwhile propose new, generalizable methods of analysis that have wider applications, including potentially shedding light on goal misgeneralization. Specifically, we first reexamine the RLHF process and propose a theoretical framework portraying it as an autoencoding process over text distributions. Our framework formalizes the RLHF objective of ensuring distributional consistency between human preference and large language model (LLM) behavior. Based on this framework, we introduce a new method to model generalization in the reward modeling stage of RLHF, the induced Bayesian network (IBN). Drawing from random graph theory and causal analysis, it enables empirically grounded derivation of generalization error bounds, a key improvement over classical methods of generalization analysis. An insight from our analysis is the superiority of the tree-based information structure in reward modeling, compared to chain-based baselines in conventional RLHF methods. We derive that in complex contexts with limited data, the tree-based reward model (RM) induces up to $\Theta(\log n/\log\log n)$ times less variance than chain-based RM where $n$ is the dataset size. As validation, we demonstrate that on three NLP tasks, the tree-based RM achieves 65% win rate on average against chain-based baselines. Looking ahead, we hope to extend the IBN analysis to help understand the phenomenon of goal misgeneralization.