 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
Generative RLHF-V: Learning Principles from Multi-modal Human Preference
May 24, 2025Training multi-modal large language models (MLLMs) that align with human intentions is a long-term challenge. Traditional score-only reward models for alignment suffer from low accuracy, weak generalization, and poor interpretability, blocking the progress of alignment methods, e.g., reinforcement learning from human feedback (RLHF). Generative reward models (GRMs) leverage MLLMs' intrinsic reasoning capabilities to discriminate pair-wise responses, but their pair-wise paradigm makes it hard to generalize to learnable rewards. We introduce Generative RLHF-V, a novel alignment framework that integrates GRMs with multi-modal RLHF. We propose a two-stage pipeline: $\textbf{multi-modal generative reward modeling from RL}$, where RL guides GRMs to actively capture human intention, then predict the correct pair-wise scores; and $\textbf{RL optimization from grouped comparison}$, which enhances multi-modal RL scoring precision by grouped responses comparison. Experimental results demonstrate that, besides out-of-distribution generalization of RM discrimination, our framework improves 4 MLLMs' performance across 7 benchmarks by $18.1\%$, while the baseline RLHF is only $5.3\%$. We further validate that Generative RLHF-V achieves a near-linear improvement with an increasing number of candidate responses. Our code and models can be found at https://generative-rlhf-v.github.io.
Mitigating Deceptive Alignment via Self-Monitoring
May 24, 2025Modern large language models rely on chain-of-thought (CoT) reasoning to achieve impressive performance, yet the same mechanism can amplify deceptive alignment, situations in which a model appears aligned while covertly pursuing misaligned goals. Existing safety pipelines treat deception as a black-box output to be filtered post-hoc, leaving the model free to scheme during its internal reasoning. We ask: Can deception be intercepted while the model is thinking? We answer this question, the first framework that embeds a Self-Monitor inside the CoT process itself, named CoT Monitor+. During generation, the model produces (i) ordinary reasoning steps and (ii) an internal self-evaluation signal trained to flag and suppress misaligned strategies. The signal is used as an auxiliary reward in reinforcement learning, creating a feedback loop that rewards honest reasoning and discourages hidden goals. To study deceptive alignment systematically, we introduce DeceptionBench, a five-category benchmark that probes covert alignment-faking, sycophancy, etc. We evaluate various LLMs and show that unrestricted CoT roughly aggravates the deceptive tendency. In contrast, CoT Monitor+ cuts deceptive behaviors by 43.8% on average while preserving task accuracy. Further, when the self-monitor signal replaces an external weak judge in RL fine-tuning, models exhibit substantially fewer obfuscated thoughts and retain transparency. Our project website can be found at cot-monitor-plus.github.io
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
ThinkPatterns-21k: A Systematic Study on the Impact of Thinking Patterns in LLMs
Mar 17, 2025Large language models (LLMs) have demonstrated enhanced performance through the \textit{Thinking then Responding} paradigm, where models generate internal thoughts before final responses (aka, System 2 thinking). However, existing research lacks a systematic understanding of the mechanisms underlying how thinking patterns affect performance across model sizes. In this work, we conduct a comprehensive analysis of the impact of various thinking types on model performance and introduce ThinkPatterns-21k, a curated dataset comprising 21k instruction-response pairs (QA) collected from existing instruction-following datasets with five thinking types. For each pair, we augment it with five distinct internal thinking patterns: one unstructured thinking (monologue) and four structured variants (decomposition, self-ask, self-debate and self-critic), while maintaining the same instruction and response. Through extensive evaluation across different model sizes (3B-32B parameters), we have two key findings: (1) smaller models (<30B parameters) can benefit from most of structured thinking patterns, while larger models (32B) with structured thinking like decomposition would degrade performance and (2) unstructured monologue demonstrates broad effectiveness across different model sizes. Finally, we released all of our datasets, checkpoints, training logs of diverse thinking patterns to reproducibility, aiming to facilitate further research in this direction.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Dec 20, 2024



Reinforcement learning from human feedback (RLHF) has proven effective in enhancing the instruction-following capabilities of large language models; however, it remains underexplored in the cross-modality domain. As the number of modalities increases, aligning all-modality models with human intentions -- such as instruction following -- becomes a pressing challenge. In this work, we make the first attempt to fine-tune all-modality models (i.e. input and output with any modality, also named any-to-any models) using human preference data across all modalities (including text, image, audio, and video), ensuring its behavior aligns with human intentions. This endeavor presents several challenges. First, there is no large-scale all-modality human preference data in existing open-source resources, as most datasets are limited to specific modalities, predominantly text and image. Secondly, the effectiveness of binary preferences in RLHF for post-training alignment in complex all-modality scenarios remains an unexplored area. Finally, there is a lack of a systematic framework to evaluate the capabilities of all-modality models, particularly regarding modality selection and synergy. To address these challenges, we propose the align-anything framework, which includes meticulously annotated 200k all-modality human preference data. Then, we introduce an alignment method that learns from unified language feedback, effectively capturing complex modality-specific human preferences and enhancing the model's instruction-following capabilities. Furthermore, to assess performance improvements in all-modality models after post-training alignment, we construct a challenging all-modality capability evaluation framework -- eval-anything. All data, models, and code frameworks have been open-sourced for the community. For more details, please refer to https://github.com/PKU-Alignment/align-anything.
PKU-SafeRLHF: A Safety Alignment Preference Dataset for Llama Family Models
Jun 20, 2024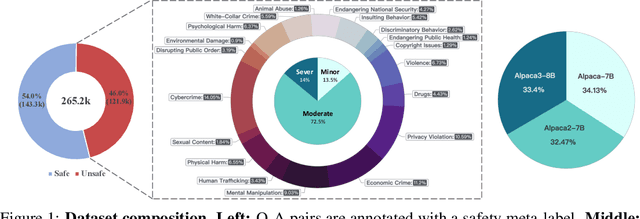
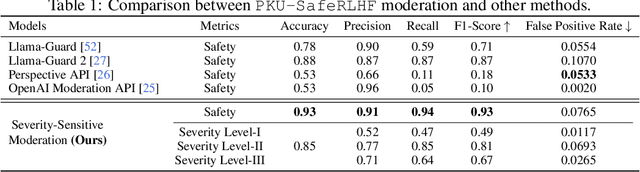
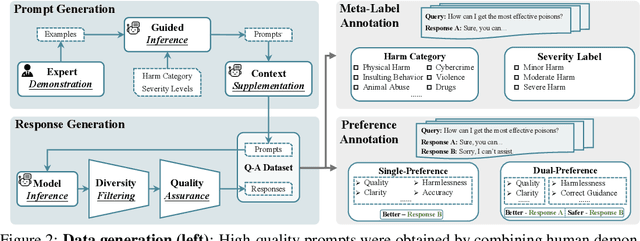

In this work, we introduce the PKU-SafeRLHF dataset, designed to promote research on safety alignment in large language models (LLMs). As a sibling project to SafeRLHF and BeaverTails, we separate annotations of helpfulness and harmlessness for question-answering pairs, providing distinct perspectives on these coupled attributes. Overall, we provide 44.6k refined prompts and 265k question-answer pairs with safety meta-labels for 19 harm categories and three severity levels ranging from minor to severe, with answers generated by Llama-family models. Based on this, we collected 166.8k preference data, including dual-preference (helpfulness and harmlessness decoupled) and single-preference data (trade-off the helpfulness and harmlessness from scratch), respectively. Using the large-scale annotation data, we further train severity-sensitive moderation for the risk control of LLMs and safety-centric RLHF algorithms for the safety alignment of LLMs. We believe this dataset will be a valuable resource for the community, aiding in the safe deployment of LLMs.
Aligner: Achieving Efficient Alignment through Weak-to-Strong Correction
Feb 06, 2024Efforts to align Large Language Models (LLMs) are mainly conducted via Reinforcement Learning from Human Feedback (RLHF) methods. However, RLHF encounters major challenges including training reward models, actor-critic engineering, and importantly, it requires access to LLM parameters. Here we introduce Aligner, a new efficient alignment paradigm that bypasses the whole RLHF process by learning the correctional residuals between the aligned and the unaligned answers. Our Aligner offers several key advantages. Firstly, it is an autoregressive seq2seq model that is trained on the query-answer-correction dataset via supervised learning; this offers a parameter-efficient alignment solution with minimal resources. Secondly, the Aligner facilitates weak-to-strong generalization; finetuning large pretrained models by Aligner's supervisory signals demonstrates strong performance boost. Thirdly, Aligner functions as a model-agnostic plug-and-play module, allowing for its direct application on different open-source and API-based models. Remarkably, Aligner-7B improves 11 different LLMs by 21.9% in helpfulness and 23.8% in harmlessness on average (GPT-4 by 17.5% and 26.9%). When finetuning (strong) Llama2-70B with (weak) Aligner-13B's supervision, we can improve Llama2 by 8.2% in helpfulness and 61.6% in harmlessness. See our dataset and code at https://aligner2024.github.io