 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for Large Language Diffusion Models
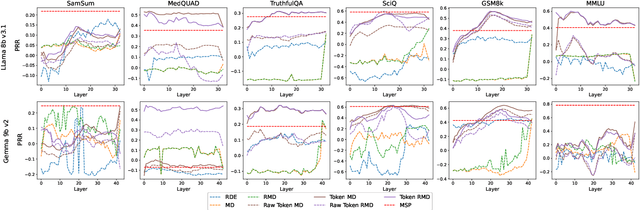
May 14, 2026Large Language Diffusion Models (LLDMs) are emerging as an alternative to autoregressive models, offering faster inference through higher parallelism. Similar to autoregressive LLMs, they remain prone to hallucinations, making reliable uncertainty quantification (UQ) crucial for safe deployment. However, existing UQ methods are fundamentally misaligned with this new paradigm: they assume autoregressive factorization or use expensive repeated sampling, negating the efficiency of LLDMs. In this work, we present the first systematic study of UQ for LLDMs and propose lightweight, zero-shot uncertainty signals derived from the iterative denoising process, leveraging intermediate generations, token remasking dynamics, and denoising complexity. We further adapt a state-of-the-art UQ method to LLDMs by combining masked diffusion likelihoods with trajectory-based semantic dissimilarity. We prove that expected trajectory dissimilarity lower bounds the masked diffusion training objective, which motivates its usage as an uncertainty score. Comprehensive experiments across three tasks, eight datasets, and two models show that our method achieves a great cost-performance trade-off: it approaches the strongest sampling-based baselines while incurring up to 100x lower computational overhead. Our work demonstrates that LLDMs can deliver both fast inference and reliable hallucination detection simultaneously.
Don't Throw Away Your Beams: Improving Consistency-based Uncertainties in LLMs via Beam Search
Dec 10, 2025Consistency-based methods have emerged as an effective approach to uncertainty quantification (UQ) in large language models. These methods typically rely on several generations obtained via multinomial sampling, measuring their agreement level. However, in short-form QA, multinomial sampling is prone to producing duplicates due to peaked distributions, and its stochasticity introduces considerable variance in uncertainty estimates across runs. We introduce a new family of methods that employ beam search to generate candidates for consistency-based UQ, yielding improved performance and reduced variance compared to multinomial sampling. We also provide a theoretical lower bound on the beam set probability mass under which beam search achieves a smaller error than multinomial sampling. We empirically evaluate our approach on six QA datasets and find that its consistent improvements over multinomial sampling lead to state-of-the-art UQ performance.
Reasoning with Confidence: Efficient Verification of LLM Reasoning Steps via Uncertainty Heads
Nov 11, 2025Solving complex tasks usually requires LLMs to generate long multi-step reasoning chains. Previous work has shown that verifying the correctness of individual reasoning steps can further improve the performance and efficiency of LLMs on such tasks and enhance solution interpretability. However, existing verification approaches, such as Process Reward Models (PRMs), are either computationally expensive, limited to specific domains, or require large-scale human or model-generated annotations. Thus, we propose a lightweight alternative for step-level reasoning verification based on data-driven uncertainty scores. We train transformer-based uncertainty quantification heads (UHeads) that use the internal states of a frozen LLM to estimate the uncertainty of its reasoning steps during generation. The approach is fully automatic: target labels are generated either by another larger LLM (e.g., DeepSeek R1) or in a self-supervised manner by the original model itself. UHeads are both effective and lightweight, containing less than 10M parameters. Across multiple domains, including mathematics, planning, and general knowledge question answering, they match or even surpass the performance of PRMs that are up to 810x larger. Our findings suggest that the internal states of LLMs encode their uncertainty and can serve as reliable signals for reasoning verification, offering a promising direction toward scalable and generalizable introspective LLMs.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking the Output of Retrieval Augmented Generation
May 28, 2025Large Language Models (LLMs) enhanced with external knowledge retrieval, an approach known as Retrieval-Augmented Generation (RAG), have shown strong performance in open-domain question answering. However, RAG systems remain susceptible to hallucinations: factually incorrect outputs that may arise either from inconsistencies in the model's internal knowledge or incorrect use of the retrieved context. Existing approaches often conflate factuality with faithfulness to the retrieved context, misclassifying factually correct statements as hallucinations if they are not directly supported by the retrieval. In this paper, we introduce FRANQ (Faithfulness-based Retrieval Augmented UNcertainty Quantification), a novel method for hallucination detection in RAG outputs. FRANQ applies different Uncertainty Quantification (UQ) techniques to estimate factuality based on whether a statement is faithful to the retrieved context or not. To evaluate FRANQ and other UQ techniques for RAG, we present a new long-form Question Answering (QA) dataset annotated for both factuality and faithfulness, combining automated labeling with manual validation of challenging examples. Extensive experiments on long- and short-form QA across multiple datasets and LLMs show that FRANQ achieves more accurate detection of factual errors in RAG-generated responses compared to existing methods.
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
May 13, 2025Large Language Models (LLMs) have the tendency to hallucinate, i.e., to sporadically generate false or fabricated information. This presents a major challenge, as hallucinations often appear highly convincing and users generally lack the tools to detect them. Uncertainty quantification (UQ) provides a framework for assessing the reliability of model outputs, aiding in the identification of potential hallucinations. In this work, we introduce pre-trained UQ heads: supervised auxiliary modules for LLMs that substantially enhance their ability to capture uncertainty compared to unsupervised UQ methods. Their strong performance stems from the powerful Transformer architecture in their design and informative features derived from LLM attention maps. Experimental evaluation shows that these heads are highly robust and achieve state-of-the-art performance in claim-level hallucination detection across both in-domain and out-of-domain prompts. Moreover, these modules demonstrate strong generalization to languages they were not explicitly trained on. We pre-train a collection of UQ heads for popular LLM series, including Mistral, Llama, and Gemma 2. We publicly release both the code and the pre-trained heads.
Uncertainty-aware abstention in medical diagnosis based on medical texts
Feb 25, 2025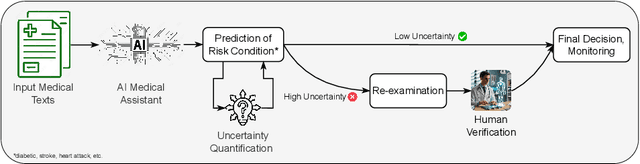
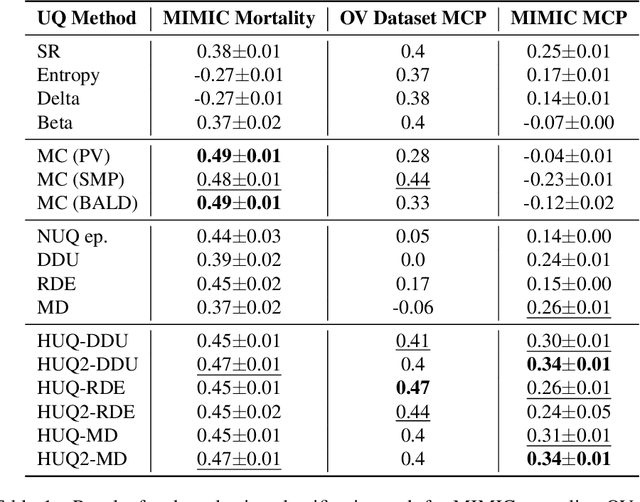
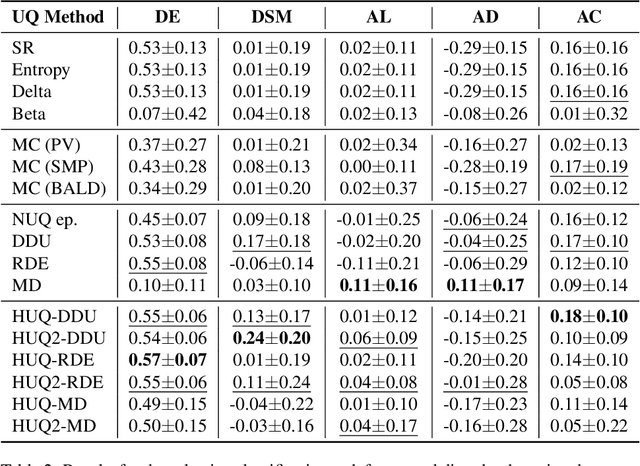
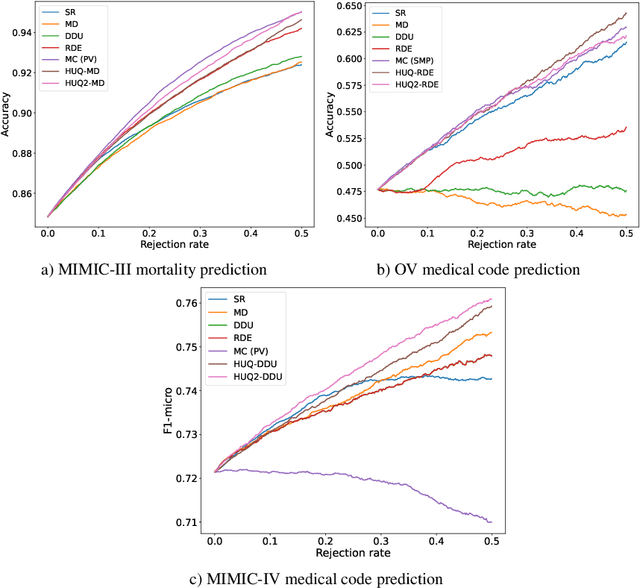
This study addresses the critical issue of reliability for AI-assisted medical diagnosis. We focus on the selection prediction approach that allows the diagnosis system to abstain from providing the decision if it is not confident in the diagnosis. Such selective prediction (or abstention) approaches are usually based on the modeling predictive uncertainty of machine learning models involved. This study explores uncertainty quantification in machine learning models for medical text analysis, addressing diverse tasks across multiple datasets. We focus on binary mortality prediction from textual data in MIMIC-III, multi-label medical code prediction using ICD-10 codes from MIMIC-IV, and multi-class classification with a private outpatient visits dataset. Additionally, we analyze mental health datasets targeting depression and anxiety detection, utilizing various text-based sources, such as essays, social media posts, and clinical descriptions. In addition to comparing uncertainty methods, we introduce HUQ-2, a new state-of-the-art method for enhancing reliability in selective prediction tasks. Our results provide a detailed comparison of uncertainty quantification methods. They demonstrate the effectiveness of HUQ-2 in capturing and evaluating uncertainty, paving the way for more reliable and interpretable applications in medical text analysis.
Argument-Based Comparative Question Answering Evaluation Benchmark
Feb 20, 2025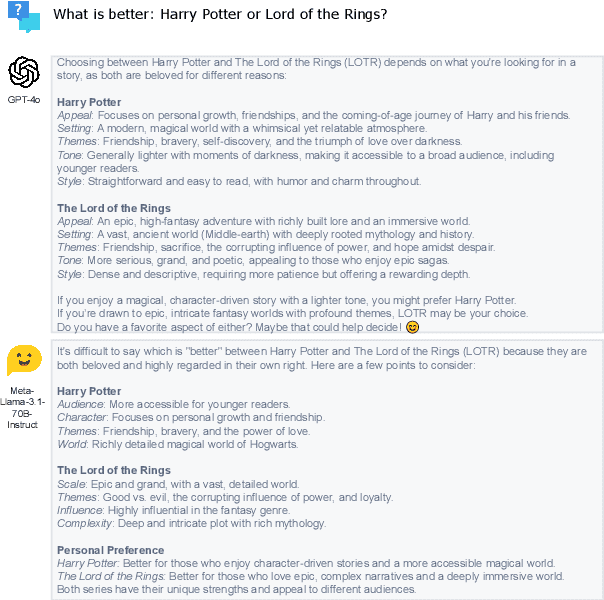

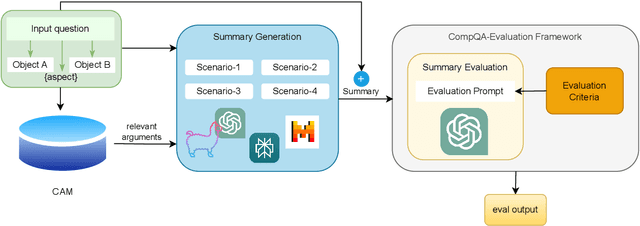
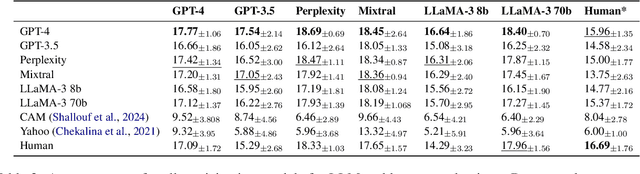
In this paper, we aim to solve the problems standing in the way of automatic comparative question answering. To this end, we propose an evaluation framework to assess the quality of comparative question answering summaries. We formulate 15 criteria for assessing comparative answers created using manual annotation and annotation from 6 large language models and two comparative question asnwering datasets. We perform our tests using several LLMs and manual annotation under different settings and demonstrate the constituency of both evaluations. Our results demonstrate that the Llama-3 70B Instruct model demonstrates the best results for summary evaluation, while GPT-4 is the best for answering comparative questions. All used data, code, and evaluation results are publicly available\footnote{\url{https://anonymous.4open.science/r/cqa-evaluation-benchmark-4561/README.md}}.
Token-Level Density-Based Uncertainty Quantification Methods for Eliciting Truthfulness of Large Language Models
Feb 20, 2025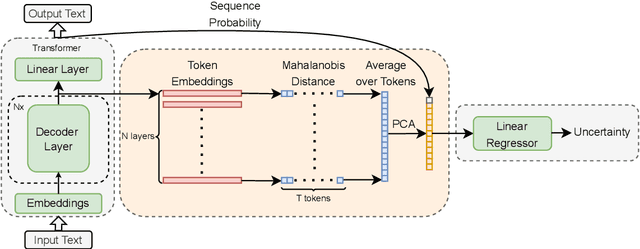

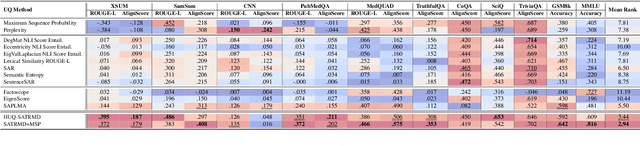
Uncertainty quantification (UQ) is a prominent approach for eliciting truthful answers from large language models (LLMs). To date, information-based and consistency-based UQ have been the dominant UQ methods for text generation via LLMs. Density-based methods, despite being very effective for UQ in text classification with encoder-based models, have not been very successful with generative LLMs. In this work, we adapt Mahalanobis Distance (MD) - a well-established UQ technique in classification tasks - for text generation and introduce a new supervised UQ method. Our method extracts token embeddings from multiple layers of LLMs, computes MD scores for each token, and uses linear regression trained on these features to provide robust uncertainty scores. Through extensive experiments on eleven datasets, we demonstrate that our approach substantially improves over existing UQ methods, providing accurate and computationally efficient uncertainty scores for both sequence-level selective generation and claim-level fact-checking tasks. Our method also exhibits strong generalization to out-of-domain data, making it suitable for a wide range of LLM-based applications.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.