 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool Detectors
May 30, 2025Recent advancements in Generative AI and Large Language Models (LLMs) have enabled the creation of highly realistic synthetic content, raising concerns about the potential for malicious use, such as misinformation and manipulation. Moreover, detecting Machine-Generated Text (MGT) remains challenging due to the lack of robust benchmarks that assess generalization to real-world scenarios. In this work, we present a pipeline to test the resilience of state-of-the-art MGT detectors (e.g., Mage, Radar, LLM-DetectAIve) to linguistically informed adversarial attacks. To challenge the detectors, we fine-tune language models using Direct Preference Optimization (DPO) to shift the MGT style toward human-written text (HWT). This exploits the detectors' reliance on stylistic clues, making new generations more challenging to detect. Additionally, we analyze the linguistic shifts induced by the alignment and which features are used by detectors to detect MGT texts. Our results show that detectors can be easily fooled with relatively few examples, resulting in a significant drop in detection performance. This highlights the importance of improving detection methods and making them robust to unseen in-domain texts.
Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary Adaptation
Apr 23, 2025The number of pretrained Large Language Models (LLMs) is increasing steadily, though the majority are designed predominantly for the English language. While state-of-the-art LLMs can handle other languages, due to language contamination or some degree of multilingual pretraining data, they are not optimized for non-English languages, leading to inefficient encoding (high token "fertility") and slower inference speed. In this work, we thoroughly compare a variety of vocabulary adaptation techniques for optimizing English LLMs for the Italian language, and put forward Semantic Alignment Vocabulary Adaptation (SAVA), a novel method that leverages neural mapping for vocabulary substitution. SAVA achieves competitive performance across multiple downstream tasks, enhancing grounded alignment strategies. We adapt two LLMs: Mistral-7b-v0.1, reducing token fertility by 25\%, and Llama-3.1-8B, optimizing the vocabulary and reducing the number of parameters by 1 billion. We show that, following the adaptation of the vocabulary, these models can recover their performance with a relatively limited stage of continual training on the target language. Finally, we test the capabilities of the adapted models on various multi-choice and generative tasks.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
AI "News" Content Farms Are Easy to Make and Hard to Detect: A Case Study in Italian
Jun 17, 2024Large Language Models (LLMs) are increasingly used as "content farm" models (CFMs), to generate synthetic text that could pass for real news articles. This is already happening even for languages that do not have high-quality monolingual LLMs. We show that fine-tuning Llama (v1), mostly trained on English, on as little as 40K Italian news articles, is sufficient for producing news-like texts that native speakers of Italian struggle to identify as synthetic. We investigate three LLMs and three methods of detecting synthetic texts (log-likelihood, DetectGPT, and supervised classification), finding that they all perform better than human raters, but they are all impractical in the real world (requiring either access to token likelihood information or a large dataset of CFM texts). We also explore the possibility of creating a proxy CFM: an LLM fine-tuned on a similar dataset to one used by the real "content farm". We find that even a small amount of fine-tuning data suffices for creating a successful detector, but we need to know which base LLM is used, which is a major challenge. Our results suggest that there are currently no practical methods for detecting synthetic news-like texts 'in the wild', while generating them is too easy. We highlight the urgency of more NLP research on this problem.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024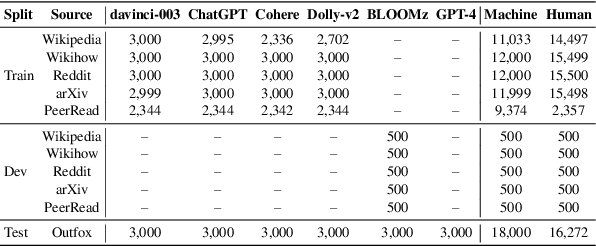

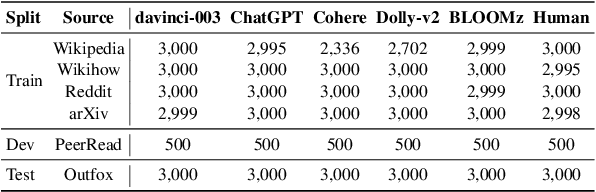

We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
The Invalsi Benchmark: measuring Language Models Mathematical and Language understanding in Italian
Mar 27, 2024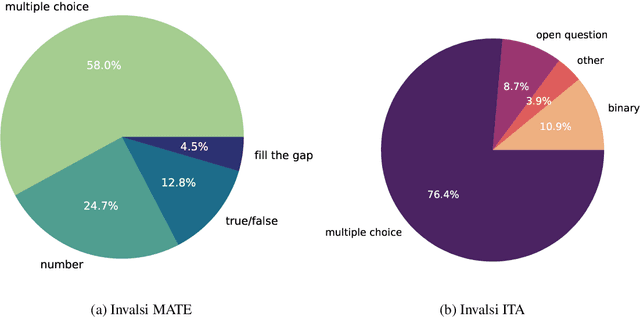
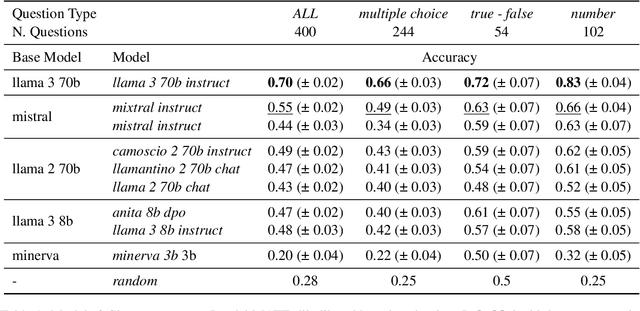
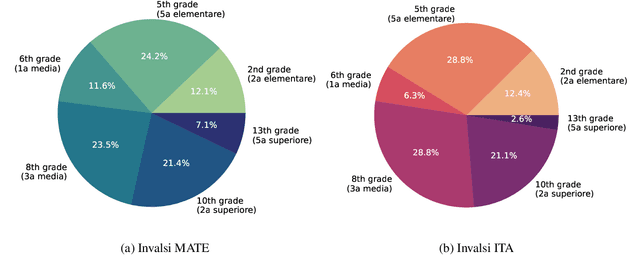
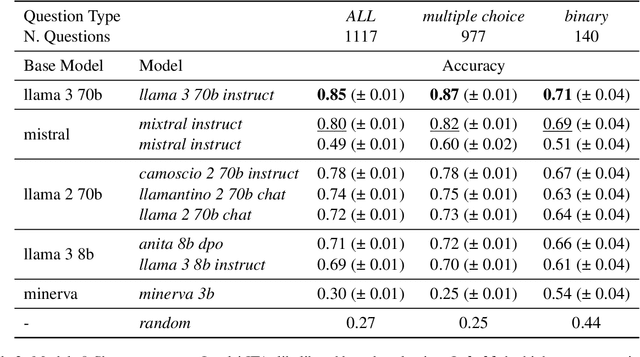
While Italian is by all metrics a high resource language, currently, there are isn't a Language Model pre-trained exclusively in this language. This results in a lower number of available benchmarks to evaluate the performance of language models in Italian. This work presents two new benchmarks to evaluate the models performance on mathematical understanding and language understanding in Italian. These benchmarks are based on real tests that are undertaken by students of age between 11 and 18 within the Italian school system and have therefore been validated by several experts in didactics and pedagogy. To validate this dataset we evaluate the performance of 9 language models that are the best performing when writing in Italian, including our own fine-tuned models. We show that this is a challenging benchmark where current language models are bound by 60\% accuracy. We believe that the release of this dataset paves the way for improving future models mathematical and language understanding in Italian.
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Feb 17, 2024



The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark involving multilingual, multi-domain and multi-generator for MGT detection -- M4GT-Bench. It is collected for three task formulations: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection identifies which particular model generates the text; and (3) human-machine mixed text detection, where a word boundary delimiting MGT from human-written content should be determined. Human evaluation for Task 2 shows less than random guess performance, demonstrating the challenges to distinguish unique LLMs. Promising results always occur when training and test data distribute within the same domain or generators.
Outliers Dimensions that Disrupt Transformers Are Driven by Frequency
May 23, 2022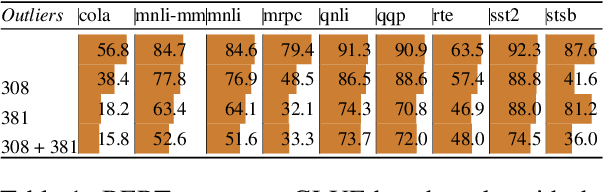
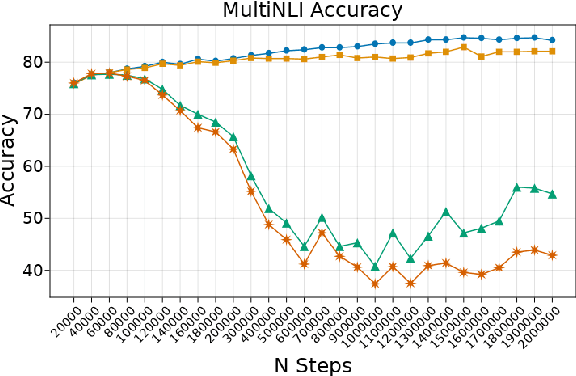
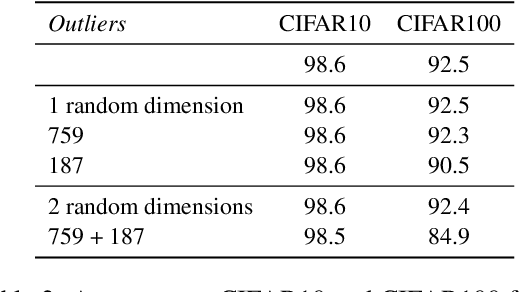
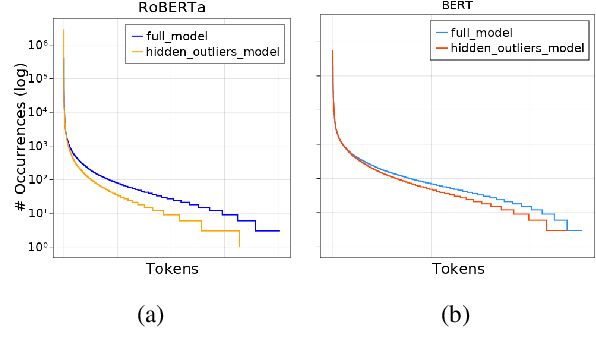
Transformer-based language models are known to display anisotropic behavior: the token embeddings are not homogeneously spread in space, but rather accumulate along certain directions. A related recent finding is the outlier phenomenon: the parameters in the final element of Transformer layers that consistently have unusual magnitude in the same dimension across the model, and significantly degrade its performance if disabled. We replicate the evidence for the outlier phenomenon and we link it to the geometry of the embedding space. Our main finding is that in both BERT and RoBERTa the token frequency, known to contribute to anisotropicity, also contributes to the outlier phenomenon. In its turn, the outlier phenomenon contributes to the "vertical" self-attention pattern that enables the model to focus on the special tokens. We also find that, surprisingly, the outlier effect on the model performance varies by layer, and that variance is also related to the correlation between outlier magnitude and encoded token frequency.