 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
May 13, 2025Large Language Models (LLMs) have the tendency to hallucinate, i.e., to sporadically generate false or fabricated information. This presents a major challenge, as hallucinations often appear highly convincing and users generally lack the tools to detect them. Uncertainty quantification (UQ) provides a framework for assessing the reliability of model outputs, aiding in the identification of potential hallucinations. In this work, we introduce pre-trained UQ heads: supervised auxiliary modules for LLMs that substantially enhance their ability to capture uncertainty compared to unsupervised UQ methods. Their strong performance stems from the powerful Transformer architecture in their design and informative features derived from LLM attention maps. Experimental evaluation shows that these heads are highly robust and achieve state-of-the-art performance in claim-level hallucination detection across both in-domain and out-of-domain prompts. Moreover, these modules demonstrate strong generalization to languages they were not explicitly trained on. We pre-train a collection of UQ heads for popular LLM series, including Mistral, Llama, and Gemma 2. We publicly release both the code and the pre-trained heads.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
Hands-On Tutorial: Labeling with LLM and Human-in-the-Loop
Nov 07, 2024Training and deploying machine learning models relies on a large amount of human-annotated data. As human labeling becomes increasingly expensive and time-consuming, recent research has developed multiple strategies to speed up annotation and reduce costs and human workload: generating synthetic training data, active learning, and hybrid labeling. This tutorial is oriented toward practical applications: we will present the basics of each strategy, highlight their benefits and limitations, and discuss in detail real-life case studies. Additionally, we will walk through best practices for managing human annotators and controlling the quality of the final dataset. The tutorial includes a hands-on workshop, where attendees will be guided in implementing a hybrid annotation setup. This tutorial is designed for NLP practitioners from both research and industry backgrounds who are involved in or interested in optimizing data labeling projects.
LLM-DetectAIve: a Tool for Fine-Grained Machine-Generated Text Detection
Aug 08, 2024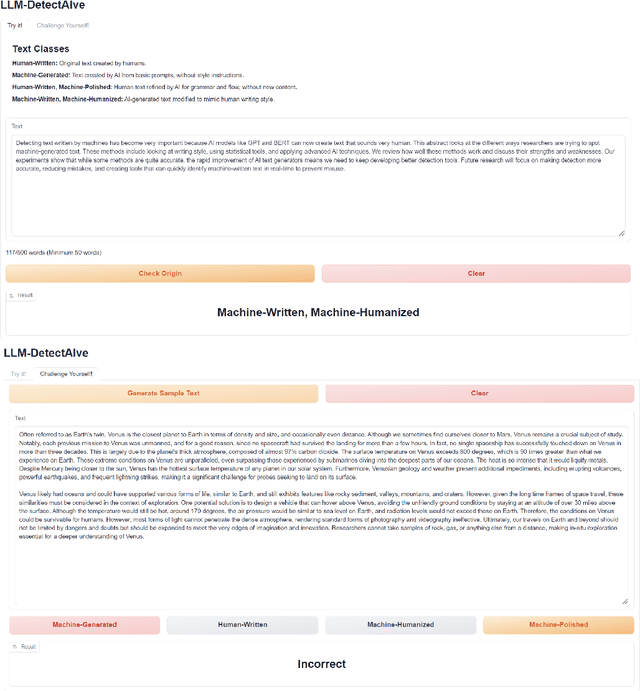
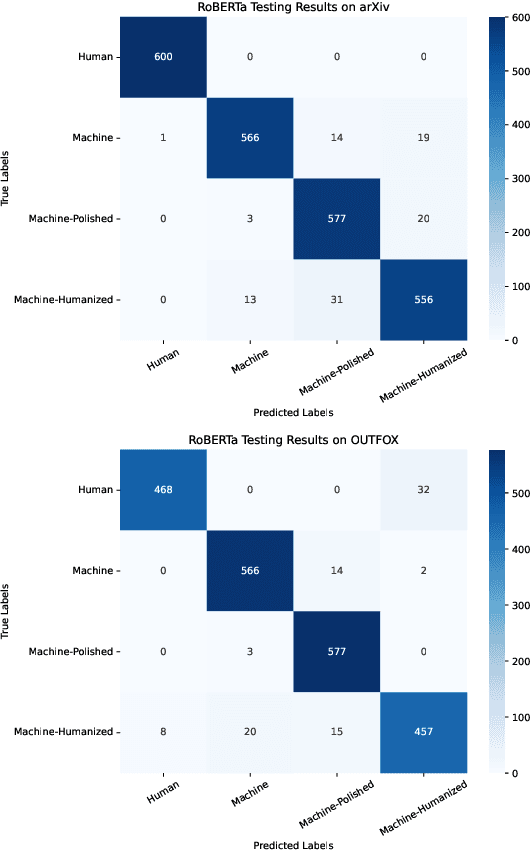
The widespread accessibility of large language models (LLMs) to the general public has significantly amplified the dissemination of machine-generated texts (MGTs). Advancements in prompt manipulation have exacerbated the difficulty in discerning the origin of a text (human-authored vs machinegenerated). This raises concerns regarding the potential misuse of MGTs, particularly within educational and academic domains. In this paper, we present $\textbf{LLM-DetectAIve}$ -- a system designed for fine-grained MGT detection. It is able to classify texts into four categories: human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Contrary to previous MGT detectors that perform binary classification, introducing two additional categories in LLM-DetectiAIve offers insights into the varying degrees of LLM intervention during the text creation. This might be useful in some domains like education, where any LLM intervention is usually prohibited. Experiments show that LLM-DetectAIve can effectively identify the authorship of textual content, proving its usefulness in enhancing integrity in education, academia, and other domains. LLM-DetectAIve is publicly accessible at https://huggingface.co/spaces/raj-tomar001/MGT-New. The video describing our system is available at https://youtu.be/E8eT_bE7k8c.
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Jun 21, 2024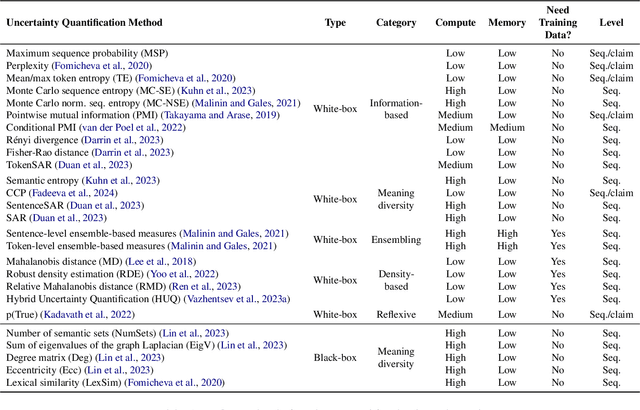
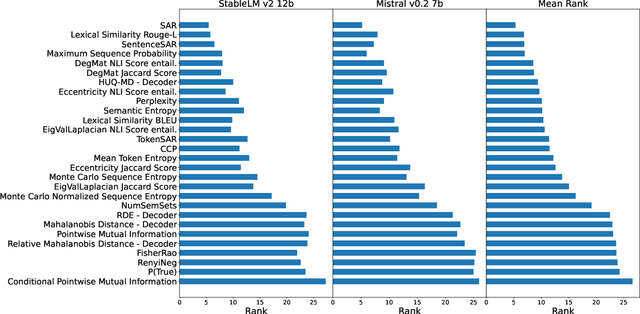
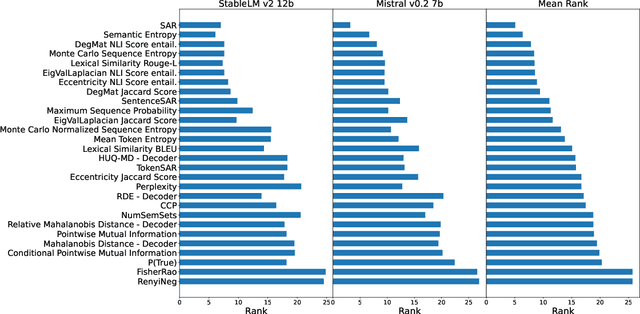
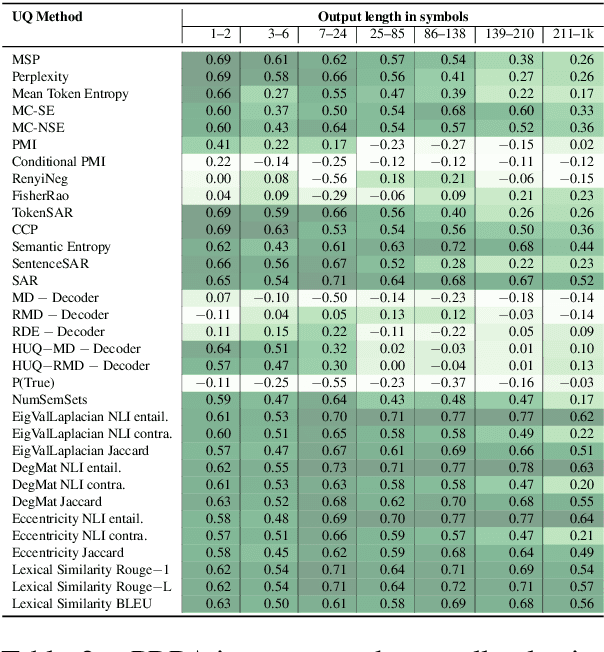
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024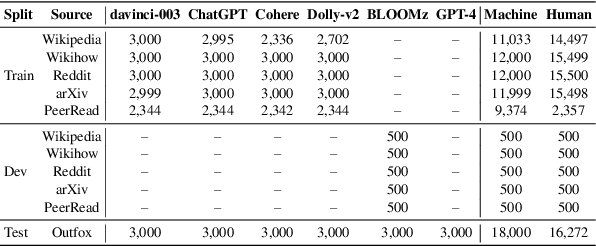


We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
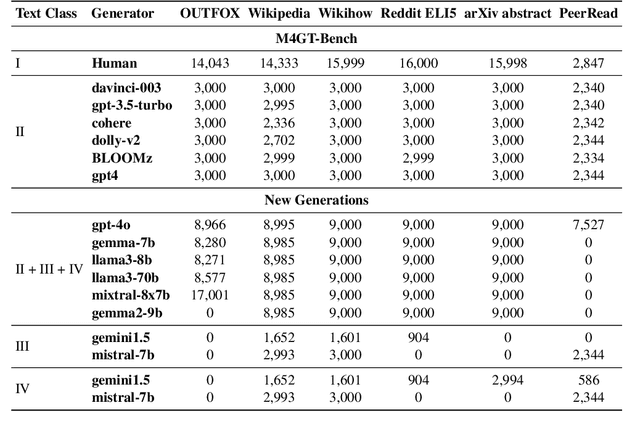
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Feb 17, 2024



The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark involving multilingual, multi-domain and multi-generator for MGT detection -- M4GT-Bench. It is collected for three task formulations: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection identifies which particular model generates the text; and (3) human-machine mixed text detection, where a word boundary delimiting MGT from human-written content should be determined. Human evaluation for Task 2 shows less than random guess performance, demonstrating the challenges to distinguish unique LLMs. Promising results always occur when training and test data distribute within the same domain or generators.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023
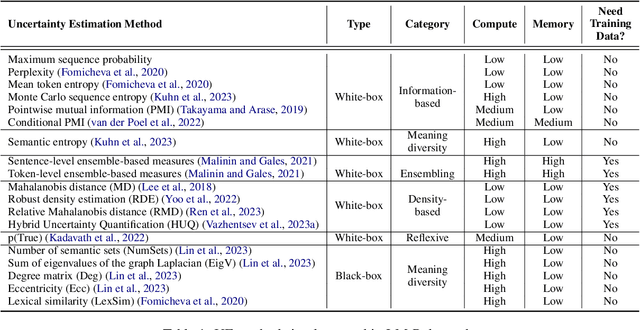
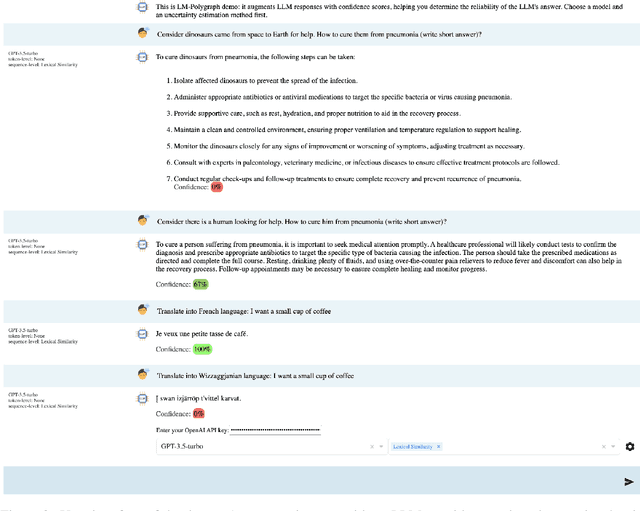
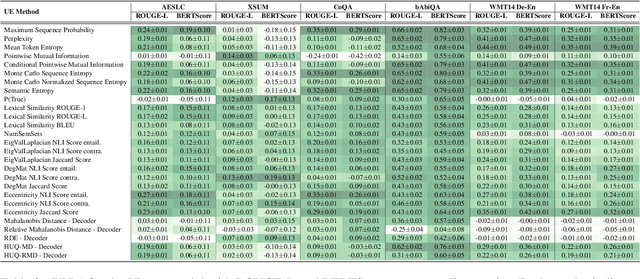
Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.
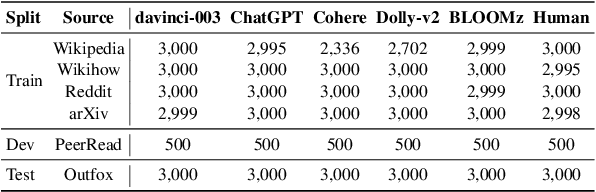
M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Generated Text Detection
May 24, 2023



Large language models (LLMs) have demonstrated remarkable capability to generate fluent responses to a wide variety of user queries, but this has also resulted in concerns regarding the potential misuse of such texts in journalism, educational, and academic context. In this work, we aim to develop automatic systems to identify machine-generated text and to detect potential misuse. We first introduce a large-scale benchmark M4, which is multi-generator, multi-domain, and multi-lingual corpus for machine-generated text detection. Using the dataset, we experiment with a number of methods and we show that it is challenging for detectors to generalize well on unseen examples if they are either from different domains or are generated by different large language models. In such cases, detectors tend to misclassify machine-generated text as human-written. These results show that the problem is far from solved and there is a lot of room for improvement. We believe that our dataset M4, which covers different generators, domains and languages, will enable future research towards more robust approaches for this pressing societal problem. The M4 dataset is available at https://github.com/mbzuai-nlp/M4.