 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an indispensable paradigm for enhancing reasoning in Large Language Models (LLMs). However, standard policy optimization methods, such as Group Relative Policy Optimization (GRPO), often converge to low-entropy policies, leading to severe mode collapse and limited output diversity. We analyze this issue from the perspective of sampling probability dynamics, identifying that the standard objective disproportionately reinforces the highest-likelihood paths, thereby suppressing valid alternative reasoning chains. To address this, we propose a novel Advantage Re-weighting Mechanism (ARM) designed to equilibrate the confidence levels across all correct responses. By incorporating Prompt Perplexity and Answer Confidence into the advantage estimation, our method dynamically reshapes the reward signal to attenuate the gradient updates of over-confident reasoning paths, while redistributing probability mass toward under-explored correct solutions. Empirical results demonstrate that our approach significantly enhances generative diversity and response entropy while maintaining competitive accuracy, effectively achieving a superior trade-off between exploration and exploitation in reasoning tasks. Empirical results on Qwen2.5 and DeepSeek models across mathematical and coding benchmarks show that ProGRPO significantly mitigates entropy collapse. Specifically, on Qwen2.5-7B, our method outperforms GRPO by 5.7% in Pass@1 and, notably, by 13.9% in Pass@32, highlighting its superior capability in generating diverse correct reasoning paths.
NoReGeo: Non-Reasoning Geometry Benchmark
Jan 15, 2026We present NoReGeo, a novel benchmark designed to evaluate the intrinsic geometric understanding of large language models (LLMs) without relying on reasoning or algebraic computation. Unlike existing benchmarks that primarily assess models' proficiency in reasoning-based geometry-where solutions are derived using algebraic methods-NoReGeo focuses on evaluating whether LLMs can inherently encode spatial relationships and recognize geometric properties directly. Our benchmark comprises 2,500 trivial geometric problems spanning 25 categories, each carefully crafted to be solvable purely through native geometric understanding, assuming known object locations. We assess a range of state-of-the-art models on NoReGeo, including frontier models like GPT-4, observing that even the most advanced systems achieve an overall maximum of 65% accuracy in binary classification tasks. Further, our ablation experiments demonstrate that such geometric understanding does not emerge through fine-tuning alone, indicating that effective training for geometric comprehension requires a specialized approach from the outset. Our findings highlight a significant gap in current LLMs' ability to natively grasp geometric concepts, providing a foundation for future research toward models with true geometric cognition.
Simple Vision-Language Math Reasoning via Rendered Text
Nov 12, 2025



We present a lightweight yet effective pipeline for training vision-language models to solve math problems by rendering LaTeX encoded equations into images and pairing them with structured chain-of-thought prompts. This simple text-to-vision augmentation enables compact multimodal architectures to achieve state-of-the-art reasoning accuracy. Through systematic ablations, we find that rendering fidelity and prompt design are the primary drivers of performance. Despite its simplicity, our approach consistently matches or surpasses both open-source and proprietary math-focused vision-language solvers on widely used benchmarks, while preserving broad general-domain competence - showing gains on tasks such as MMMU, ChartQA, and DocVQA of up to 20%.
Sentence-Anchored Gist Compression for Long-Context LLMs
Nov 11, 2025


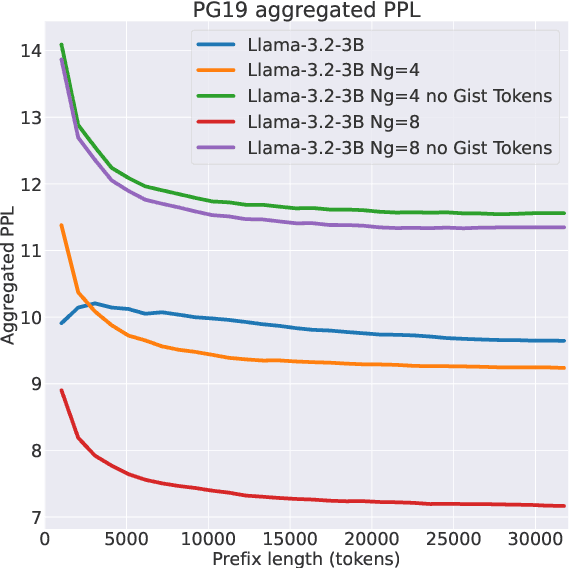
This work investigates context compression for Large Language Models (LLMs) using learned compression tokens to reduce the memory and computational demands of processing long sequences. We demonstrate that pre-trained LLMs can be fine-tuned to compress their context by factors of 2x to 8x without significant performance degradation, as evaluated on both short-context and long-context benchmarks. Furthermore, in experiments on a 3-billion-parameter LLaMA model, our method achieves results on par with alternative compression techniques while attaining higher compression ratios.
SONAR-LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens
Aug 07, 2025The recently proposed Large Concept Model (LCM) generates text by predicting a sequence of sentence-level embeddings and training with either mean-squared error or diffusion objectives. We present SONAR-LLM, a decoder-only transformer that "thinks" in the same continuous SONAR embedding space, yet is supervised through token-level cross-entropy propagated via the frozen SONAR decoder. This hybrid objective retains the semantic abstraction of LCM while eliminating its diffusion sampler and restoring a likelihood-based training signal. Across model sizes from 39M to 1.3B parameters, SONAR-LLM attains competitive generation quality. We report scaling trends, ablations, benchmark results, and release the complete training code and all pretrained checkpoints to foster reproducibility and future research.
Image Reconstruction as a Tool for Feature Analysis
Jun 09, 2025Vision encoders are increasingly used in modern applications, from vision-only models to multimodal systems such as vision-language models. Despite their remarkable success, it remains unclear how these architectures represent features internally. Here, we propose a novel approach for interpreting vision features via image reconstruction. We compare two related model families, SigLIP and SigLIP2, which differ only in their training objective, and show that encoders pre-trained on image-based tasks retain significantly more image information than those trained on non-image tasks such as contrastive learning. We further apply our method to a range of vision encoders, ranking them by the informativeness of their feature representations. Finally, we demonstrate that manipulating the feature space yields predictable changes in reconstructed images, revealing that orthogonal rotations (rather than spatial transformations) control color encoding. Our approach can be applied to any vision encoder, shedding light on the inner structure of its feature space. The code and model weights to reproduce the experiments are available in GitHub.
When Less is Enough: Adaptive Token Reduction for Efficient Image Representation
Mar 20, 2025Vision encoders typically generate a large number of visual tokens, providing information-rich representations but significantly increasing computational demands. This raises the question of whether all generated tokens are equally valuable or if some of them can be discarded to reduce computational costs without compromising quality. In this paper, we introduce a new method for determining feature utility based on the idea that less valuable features can be reconstructed from more valuable ones. We implement this concept by integrating an autoencoder with a Gumbel-Softmax selection mechanism, that allows identifying and retaining only the most informative visual tokens. To validate our approach, we compared the performance of the LLaVA-NeXT model, using features selected by our method with randomly selected features. We found that on OCR-based tasks, more than 50% of the visual context can be removed with minimal performance loss, whereas randomly discarding the same proportion of features significantly affects the model capabilities. Furthermore, in general-domain tasks, even randomly retaining only 30% of tokens achieves performance comparable to using the full set of visual tokens. Our results highlight a promising direction towards adaptive and efficient multimodal pruning that facilitates scalable and low-overhead inference without compromising performance.
MOVE: A Mixture-of-Vision-Encoders Approach for Domain-Focused Vision-Language Processing
Feb 21, 2025
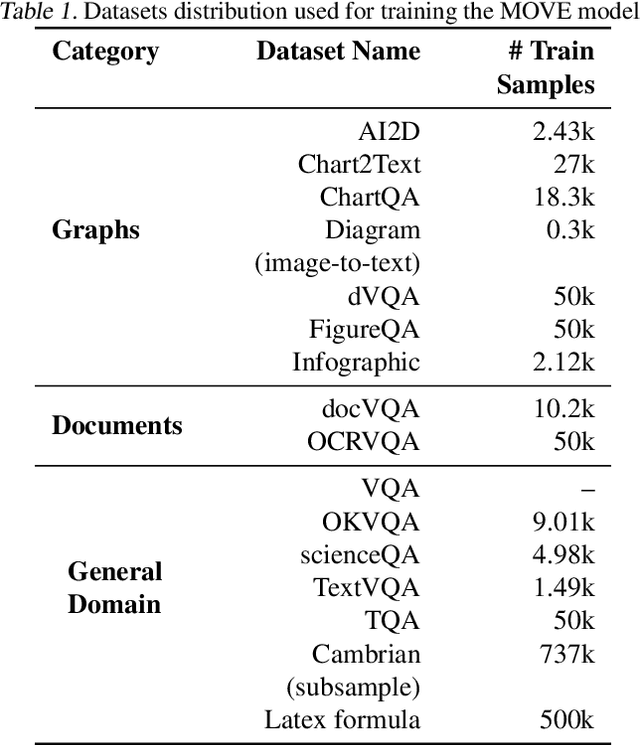


Multimodal language models (MLMs) integrate visual and textual information by coupling a vision encoder with a large language model through the specific adapter. While existing approaches commonly rely on a single pre-trained vision encoder, there is a great variability of specialized encoders that can boost model's performance in distinct domains. In this work, we propose MOVE (Mixture of Vision Encoders) a simple yet effective approach to leverage multiple pre-trained encoders for specialized multimodal tasks. MOVE automatically routes inputs to the most appropriate encoder among candidates such as Unichat, InternViT, and Texify, thereby enhancing performance across a diverse set of benchmarks, including ChartQA, MMBench, and MMMU. Experimental results demonstrate that MOVE achieves competitive accuracy without incurring the complexities of image slicing for high-resolution images.
LLM-Microscope: Uncovering the Hidden Role of Punctuation in Context Memory of Transformers
Feb 20, 2025We introduce methods to quantify how Large Language Models (LLMs) encode and store contextual information, revealing that tokens often seen as minor (e.g., determiners, punctuation) carry surprisingly high context. Notably, removing these tokens -- especially stopwords, articles, and commas -- consistently degrades performance on MMLU and BABILong-4k, even if removing only irrelevant tokens. Our analysis also shows a strong correlation between contextualization and linearity, where linearity measures how closely the transformation from one layer's embeddings to the next can be approximated by a single linear mapping. These findings underscore the hidden importance of filler tokens in maintaining context. For further exploration, we present LLM-Microscope, an open-source toolkit that assesses token-level nonlinearity, evaluates contextual memory, visualizes intermediate layer contributions (via an adapted Logit Lens), and measures the intrinsic dimensionality of representations. This toolkit illuminates how seemingly trivial tokens can be critical for long-range understanding.
Addressing Hallucinations in Language Models with Knowledge Graph Embeddings as an Additional Modality
Nov 18, 2024In this paper we present an approach to reduce hallucinations in Large Language Models (LLMs) by incorporating Knowledge Graphs (KGs) as an additional modality. Our method involves transforming input text into a set of KG embeddings and using an adapter to integrate these embeddings into the language model space, without relying on external retrieval processes. To facilitate this, we created WikiEntities, a dataset containing over 3 million Wikipedia texts annotated with entities from Wikidata and their corresponding embeddings from PyTorch-BigGraph. This dataset serves as a valuable resource for training Entity Linking models and adapting the described method to various LLMs using specialized adapters. Our method does not require fine-tuning of the language models themselves; instead, we only train the adapter. This ensures that the model's performance on other tasks is not affected. We trained an adapter for the Mistral 7B, LLaMA 2-7B (chat), and LLaMA 3-8B (instruct) models using this dataset and demonstrated that our approach improves performance on the HaluEval, True-False benchmarks and FEVER dataset. The results indicate that incorporating KGs as a new modality can effectively reduce hallucinations and improve the factual accuracy of language models, all without the need for external retrieval.