 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoReGeo: Non-Reasoning Geometry Benchmark
Jan 15, 2026We present NoReGeo, a novel benchmark designed to evaluate the intrinsic geometric understanding of large language models (LLMs) without relying on reasoning or algebraic computation. Unlike existing benchmarks that primarily assess models' proficiency in reasoning-based geometry-where solutions are derived using algebraic methods-NoReGeo focuses on evaluating whether LLMs can inherently encode spatial relationships and recognize geometric properties directly. Our benchmark comprises 2,500 trivial geometric problems spanning 25 categories, each carefully crafted to be solvable purely through native geometric understanding, assuming known object locations. We assess a range of state-of-the-art models on NoReGeo, including frontier models like GPT-4, observing that even the most advanced systems achieve an overall maximum of 65% accuracy in binary classification tasks. Further, our ablation experiments demonstrate that such geometric understanding does not emerge through fine-tuning alone, indicating that effective training for geometric comprehension requires a specialized approach from the outset. Our findings highlight a significant gap in current LLMs' ability to natively grasp geometric concepts, providing a foundation for future research toward models with true geometric cognition.
Generalized Fisher-Weighted SVD: Scalable Kronecker-Factored Fisher Approximation for Compressing Large Language Models
May 23, 2025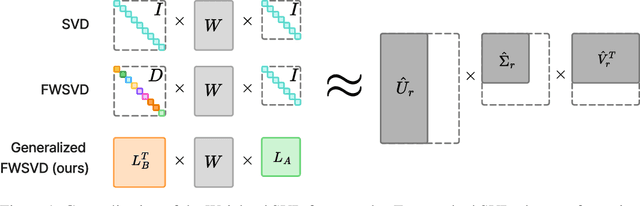
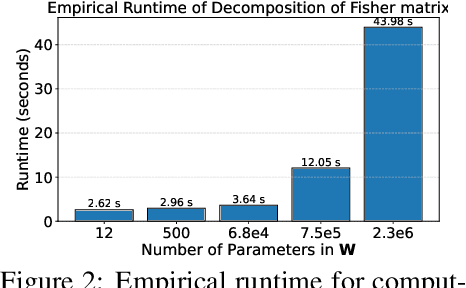

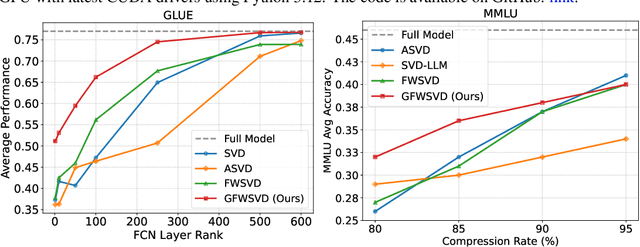
The Fisher information is a fundamental concept for characterizing the sensitivity of parameters in neural networks. However, leveraging the full observed Fisher information is too expensive for large models, so most methods rely on simple diagonal approximations. While efficient, this approach ignores parameter correlations, often resulting in reduced performance on downstream tasks. In this work, we mitigate these limitations and propose Generalized Fisher-Weighted SVD (GFWSVD), a post-training LLM compression technique that accounts for both diagonal and off-diagonal elements of the Fisher information matrix, providing a more accurate reflection of parameter importance. To make the method tractable, we introduce a scalable adaptation of the Kronecker-factored approximation algorithm for the observed Fisher information. We demonstrate the effectiveness of our method on LLM compression, showing improvements over existing compression baselines. For example, at a 20 compression rate on the MMLU benchmark, our method outperforms FWSVD, which is based on a diagonal approximation of the Fisher information, by 5 percent, SVD-LLM by 3 percent, and ASVD by 6 percent compression rate.
OmniFusion Technical Report
Apr 09, 2024



Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an \textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.