 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Vision-Language Math Reasoning via Rendered Text
Nov 12, 2025



We present a lightweight yet effective pipeline for training vision-language models to solve math problems by rendering LaTeX encoded equations into images and pairing them with structured chain-of-thought prompts. This simple text-to-vision augmentation enables compact multimodal architectures to achieve state-of-the-art reasoning accuracy. Through systematic ablations, we find that rendering fidelity and prompt design are the primary drivers of performance. Despite its simplicity, our approach consistently matches or surpasses both open-source and proprietary math-focused vision-language solvers on widely used benchmarks, while preserving broad general-domain competence - showing gains on tasks such as MMMU, ChartQA, and DocVQA of up to 20%.
Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models
Jun 05, 2025Large language models (LLMs) excel at reasoning, yet post-training remains critical for aligning their behavior with task goals. Existing reinforcement learning (RL) methods often depend on costly human annotations or external reward models. We propose Reinforcement Learning via Self-Confidence (RLSC), which uses the model's own confidence as reward signals-eliminating the need for labels, preference models, or reward engineering. Applied to Qwen2.5-Math-7B with only 8 samples per question and 4 training epochs, RLSC improves accuracy by +20.10% on AIME2024, +49.40% on MATH500, and +52.50% on AMC23. RLSC offers a simple, scalable post-training method for reasoning models with minimal supervision.
MOVE: A Mixture-of-Vision-Encoders Approach for Domain-Focused Vision-Language Processing
Feb 21, 2025
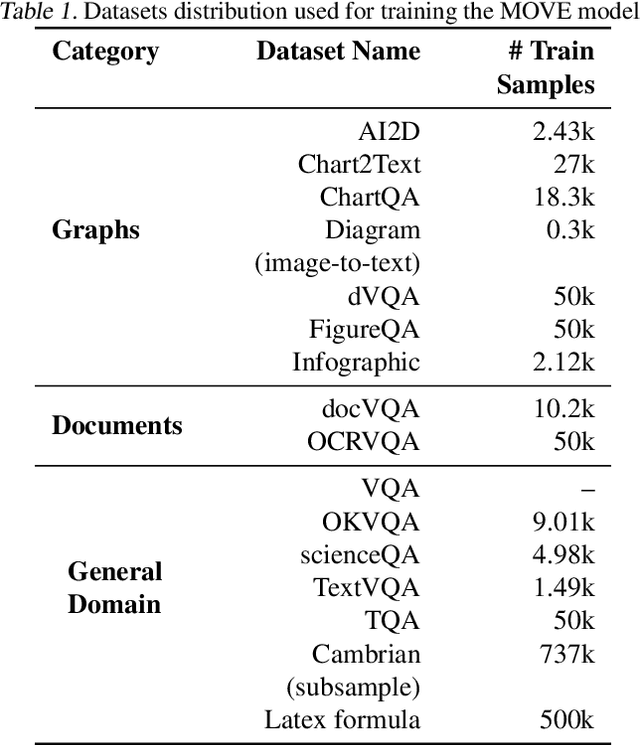


Multimodal language models (MLMs) integrate visual and textual information by coupling a vision encoder with a large language model through the specific adapter. While existing approaches commonly rely on a single pre-trained vision encoder, there is a great variability of specialized encoders that can boost model's performance in distinct domains. In this work, we propose MOVE (Mixture of Vision Encoders) a simple yet effective approach to leverage multiple pre-trained encoders for specialized multimodal tasks. MOVE automatically routes inputs to the most appropriate encoder among candidates such as Unichat, InternViT, and Texify, thereby enhancing performance across a diverse set of benchmarks, including ChartQA, MMBench, and MMMU. Experimental results demonstrate that MOVE achieves competitive accuracy without incurring the complexities of image slicing for high-resolution images.
UniDet3D: Multi-dataset Indoor 3D Object Detection
Sep 06, 2024
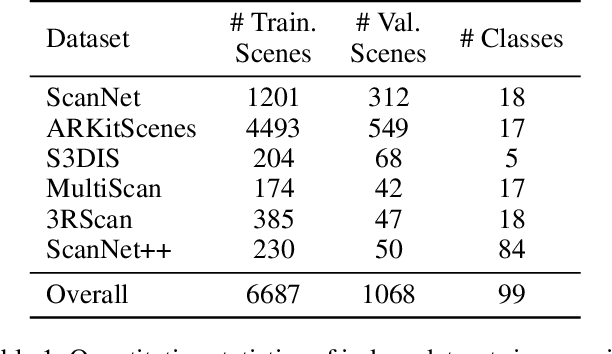
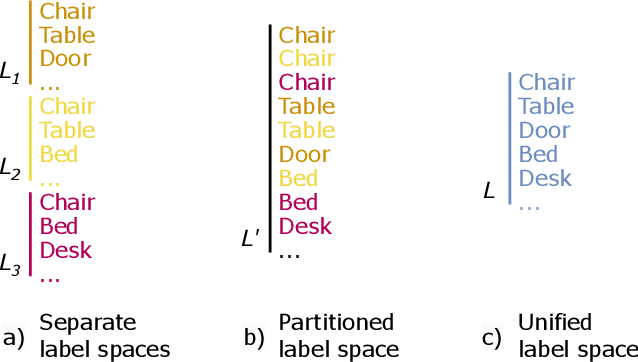
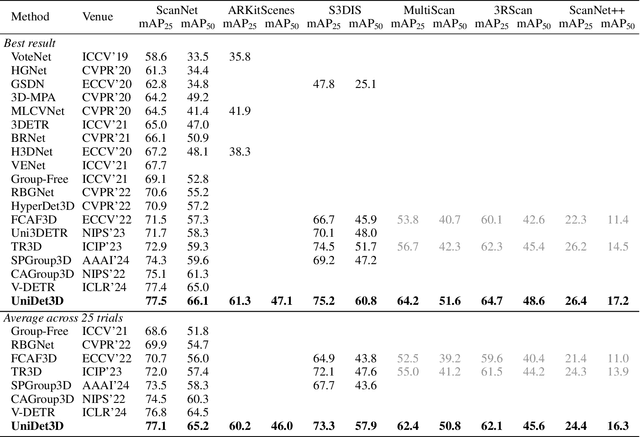
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose \ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, \ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that \ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
OmniFusion Technical Report
Apr 09, 2024



Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an \textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.