 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReText: Text Boosts Generalization in Image-Based Person Re-identification
Feb 05, 2026Generalizable image-based person re-identification (Re-ID) aims to recognize individuals across cameras in unseen domains without retraining. While multiple existing approaches address the domain gap through complex architectures, recent findings indicate that better generalization can be achieved by stylistically diverse single-camera data. Although this data is easy to collect, it lacks complexity due to minimal cross-view variation. We propose ReText, a novel method trained on a mixture of multi-camera Re-ID data and single-camera data, where the latter is complemented by textual descriptions to enrich semantic cues. During training, ReText jointly optimizes three tasks: (1) Re-ID on multi-camera data, (2) image-text matching, and (3) image reconstruction guided by text on single-camera data. Experiments demonstrate that ReText achieves strong generalization and significantly outperforms state-of-the-art methods on cross-domain Re-ID benchmarks. To the best of our knowledge, this is the first work to explore multimodal joint learning on a mixture of multi-camera and single-camera data in image-based person Re-ID.
Unified Sensor Simulation for Autonomous Driving
Feb 05, 2026In this work, we introduce \textbf{XSIM}, a sensor simulation framework for autonomous driving. XSIM extends 3DGUT splatting with a generalized rolling-shutter modeling tailored for autonomous driving applications. Our framework provides a unified and flexible formulation for appearance and geometric sensor modeling, enabling rendering of complex sensor distortions in dynamic environments. We identify spherical cameras, such as LiDARs, as a critical edge case for existing 3DGUT splatting due to cyclic projection and time discontinuities at azimuth boundaries leading to incorrect particle projection. To address this issue, we propose a phase modeling mechanism that explicitly accounts temporal and shape discontinuities of Gaussians projected by the Unscented Transform at azimuth borders. In addition, we introduce an extended 3D Gaussian representation that incorporates two distinct opacity parameters to resolve mismatches between geometry and color distributions. As a result, our framework provides enhanced scene representations with improved geometric consistency and photorealistic appearance. We evaluate our framework extensively on multiple autonomous driving datasets, including Waymo Open Dataset, Argoverse 2, and PandaSet. Our framework consistently outperforms strong recent baselines and achieves state-of-the-art performance across all datasets. The source code is publicly available at \href{https://github.com/whesense/XSIM}{https://github.com/whesense/XSIM}.
Visual Implicit Geometry Transformer for Autonomous Driving
Feb 05, 2026We introduce the Visual Implicit Geometry Transformer (ViGT), an autonomous driving geometric model that estimates continuous 3D occupancy fields from surround-view camera rigs. ViGT represents a step towards foundational geometric models for autonomous driving, prioritizing scalability, architectural simplicity, and generalization across diverse sensor configurations. Our approach achieves this through a calibration-free architecture, enabling a single model to adapt to different sensor setups. Unlike general-purpose geometric foundational models that focus on pixel-aligned predictions, ViGT estimates a continuous 3D occupancy field in a birds-eye-view (BEV) addressing domain-specific requirements. ViGT naturally infers geometry from multiple camera views into a single metric coordinate frame, providing a common representation for multiple geometric tasks. Unlike most existing occupancy models, we adopt a self-supervised training procedure that leverages synchronized image-LiDAR pairs, eliminating the need for costly manual annotations. We validate the scalability and generalizability of our approach by training our model on a mixture of five large-scale autonomous driving datasets (NuScenes, Waymo, NuPlan, ONCE, and Argoverse) and achieving state-of-the-art performance on the pointmap estimation task, with the best average rank across all evaluated baselines. We further evaluate ViGT on the Occ3D-nuScenes benchmark, where ViGT achieves comparable performance with supervised methods. The source code is publicly available at \href{https://github.com/whesense/ViGT}{https://github.com/whesense/ViGT}.
Z3D: Zero-Shot 3D Visual Grounding from Images
Feb 03, 20263D visual grounding (3DVG) aims to localize objects in a 3D scene based on natural language queries. In this work, we explore zero-shot 3DVG from multi-view images alone, without requiring any geometric supervision or object priors. We introduce Z3D, a universal grounding pipeline that flexibly operates on multi-view images while optionally incorporating camera poses and depth maps. We identify key bottlenecks in prior zero-shot methods causing significant performance degradation and address them with (i) a state-of-the-art zero-shot 3D instance segmentation method to generate high-quality 3D bounding box proposals and (ii) advanced reasoning via prompt-based segmentation, which utilizes full capabilities of modern VLMs. Extensive experiments on the ScanRefer and Nr3D benchmarks demonstrate that our approach achieves state-of-the-art performance among zero-shot methods. Code is available at https://github.com/col14m/z3d .
cadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
May 28, 2025Computer-Aided Design (CAD) plays a central role in engineering and manufacturing, making it possible to create precise and editable 3D models. Using a variety of sensor or user-provided data as inputs for CAD reconstruction can democratize access to design applications. However, existing methods typically focus on a single input modality, such as point clouds, images, or text, which limits their generalizability and robustness. Leveraging recent advances in vision-language models (VLM), we propose a multi-modal CAD reconstruction model that simultaneously processes all three input modalities. Inspired by large language model (LLM) training paradigms, we adopt a two-stage pipeline: supervised fine-tuning (SFT) on large-scale procedurally generated data, followed by reinforcement learning (RL) fine-tuning using online feedback, obtained programatically. Furthermore, we are the first to explore RL fine-tuning of LLMs for CAD tasks demonstrating that online RL algorithms such as Group Relative Preference Optimization (GRPO) outperform offline alternatives. In the DeepCAD benchmark, our SFT model outperforms existing single-modal approaches in all three input modalities simultaneously. More importantly, after RL fine-tuning, cadrille sets new state-of-the-art on three challenging datasets, including a real-world one.
ReMix: Training Generalized Person Re-identification on a Mixture of Data
Oct 29, 2024
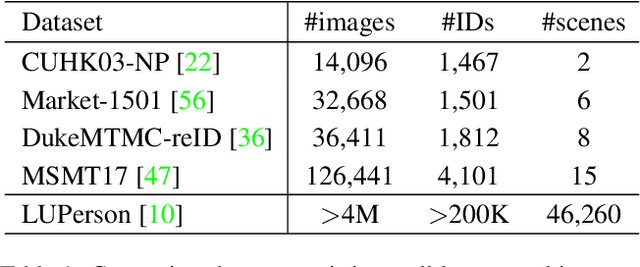
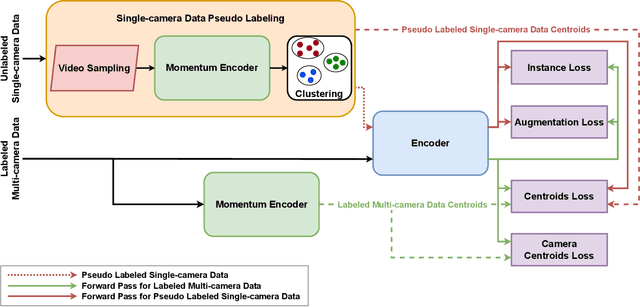
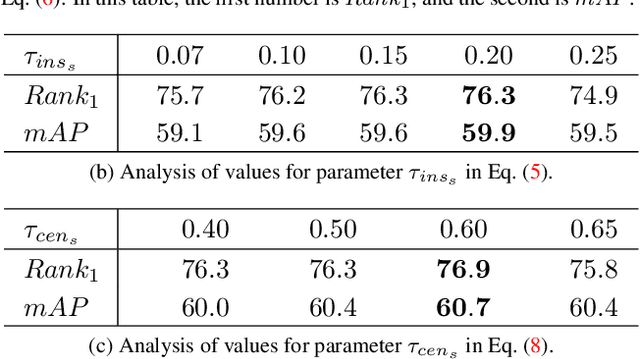
Modern person re-identification (Re-ID) methods have a weak generalization ability and experience a major accuracy drop when capturing environments change. This is because existing multi-camera Re-ID datasets are limited in size and diversity, since such data is difficult to obtain. At the same time, enormous volumes of unlabeled single-camera records are available. Such data can be easily collected, and therefore, it is more diverse. Currently, single-camera data is used only for self-supervised pre-training of Re-ID methods. However, the diversity of single-camera data is suppressed by fine-tuning on limited multi-camera data after pre-training. In this paper, we propose ReMix, a generalized Re-ID method jointly trained on a mixture of limited labeled multi-camera and large unlabeled single-camera data. Effective training of our method is achieved through a novel data sampling strategy and new loss functions that are adapted for joint use with both types of data. Experiments show that ReMix has a high generalization ability and outperforms state-of-the-art methods in generalizable person Re-ID. To the best of our knowledge, this is the first work that explores joint training on a mixture of multi-camera and single-camera data in person Re-ID.
RClicks: Realistic Click Simulation for Benchmarking Interactive Segmentation
Oct 15, 2024The emergence of Segment Anything (SAM) sparked research interest in the field of interactive segmentation, especially in the context of image editing tasks and speeding up data annotation. Unlike common semantic segmentation, interactive segmentation methods allow users to directly influence their output through prompts (e.g. clicks). However, click patterns in real-world interactive segmentation scenarios remain largely unexplored. Most methods rely on the assumption that users would click in the center of the largest erroneous area. Nevertheless, recent studies show that this is not always the case. Thus, methods may have poor performance in real-world deployment despite high metrics in a baseline benchmark. To accurately simulate real-user clicks, we conducted a large crowdsourcing study of click patterns in an interactive segmentation scenario and collected 475K real-user clicks. Drawing on ideas from saliency tasks, we develop a clickability model that enables sampling clicks, which closely resemble actual user inputs. Using our model and dataset, we propose RClicks benchmark for a comprehensive comparison of existing interactive segmentation methods on realistic clicks. Specifically, we evaluate not only the average quality of methods, but also the robustness w.r.t. click patterns. According to our benchmark, in real-world usage interactive segmentation models may perform worse than it has been reported in the baseline benchmark, and most of the methods are not robust. We believe that RClicks is a significant step towards creating interactive segmentation methods that provide the best user experience in real-world cases.
UniDet3D: Multi-dataset Indoor 3D Object Detection
Sep 06, 2024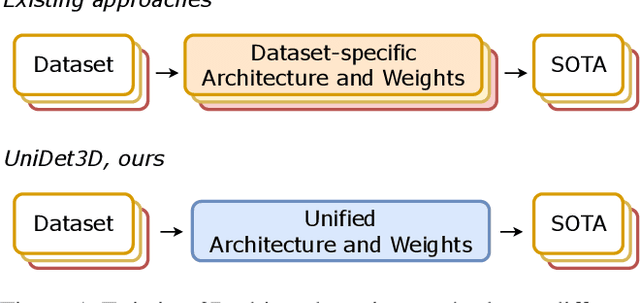
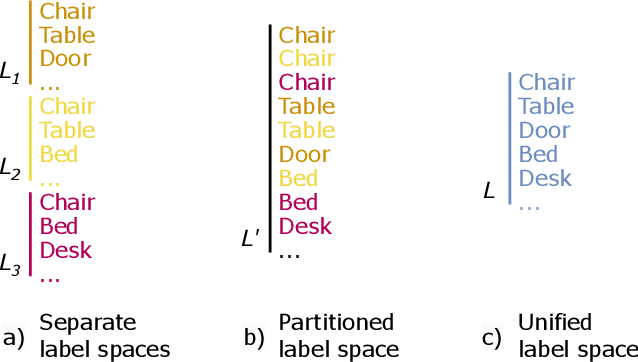
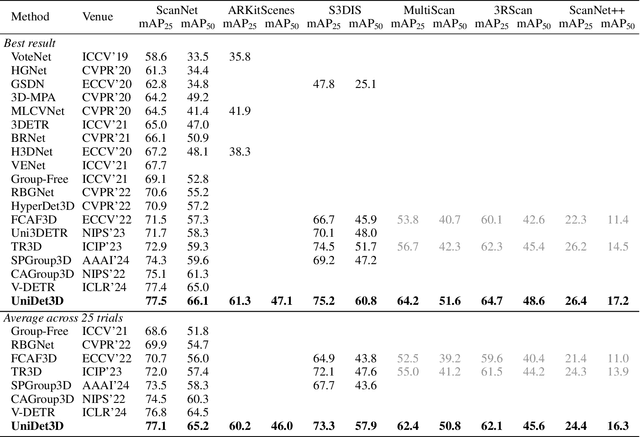
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose \ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, \ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that \ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
A3D: Does Diffusion Dream about 3D Alignment?
Jun 21, 2024



We tackle the problem of text-driven 3D generation from a geometry alignment perspective. We aim at the generation of multiple objects which are consistent in terms of semantics and geometry. Recent methods based on Score Distillation have succeeded in distilling the knowledge from 2D diffusion models to high-quality objects represented by 3D neural radiance fields. These methods handle multiple text queries separately, and therefore, the resulting objects have a high variability in object pose and structure. However, in some applications such as geometry editing, it is desirable to obtain aligned objects. In order to achieve alignment, we propose to optimize the continuous trajectories between the aligned objects, by modeling a space of linear pairwise interpolations of the textual embeddings with a single NeRF representation. We demonstrate that similar objects, consisting of semantically corresponding parts, can be well aligned in 3D space without costly modifications to the generation process. We provide several practical scenarios including mesh editing and object hybridization that benefit from geometry alignment and experimentally demonstrate the efficiency of our method. https://voyleg.github.io/a3d/
Features Fusion for Dual-View Mammography Mass Detection
Apr 25, 2024
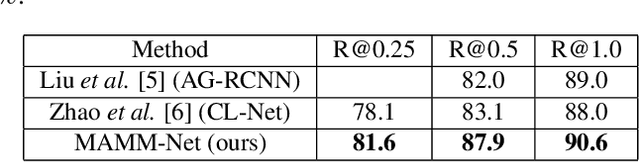

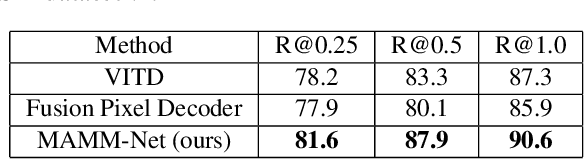
Detection of malignant lesions on mammography images is extremely important for early breast cancer diagnosis. In clinical practice, images are acquired from two different angles, and radiologists can fully utilize information from both views, simultaneously locating the same lesion. However, for automatic detection approaches such information fusion remains a challenge. In this paper, we propose a new model called MAMM-Net, which allows the processing of both mammography views simultaneously by sharing information not only on an object level, as seen in existing works, but also on a feature level. MAMM-Net's key component is the Fusion Layer, based on deformable attention and designed to increase detection precision while keeping high recall. Our experiments show superior performance on the public DDSM dataset compared to the previous state-of-the-art model, while introducing new helpful features such as lesion annotation on pixel-level and classification of lesions malignancy.