 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
May 28, 2025Computer-Aided Design (CAD) plays a central role in engineering and manufacturing, making it possible to create precise and editable 3D models. Using a variety of sensor or user-provided data as inputs for CAD reconstruction can democratize access to design applications. However, existing methods typically focus on a single input modality, such as point clouds, images, or text, which limits their generalizability and robustness. Leveraging recent advances in vision-language models (VLM), we propose a multi-modal CAD reconstruction model that simultaneously processes all three input modalities. Inspired by large language model (LLM) training paradigms, we adopt a two-stage pipeline: supervised fine-tuning (SFT) on large-scale procedurally generated data, followed by reinforcement learning (RL) fine-tuning using online feedback, obtained programatically. Furthermore, we are the first to explore RL fine-tuning of LLMs for CAD tasks demonstrating that online RL algorithms such as Group Relative Preference Optimization (GRPO) outperform offline alternatives. In the DeepCAD benchmark, our SFT model outperforms existing single-modal approaches in all three input modalities simultaneously. More importantly, after RL fine-tuning, cadrille sets new state-of-the-art on three challenging datasets, including a real-world one.
UniDet3D: Multi-dataset Indoor 3D Object Detection
Sep 06, 2024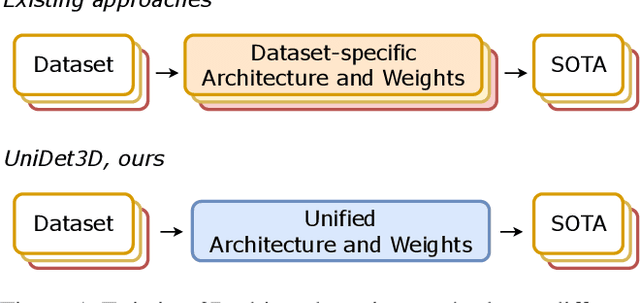
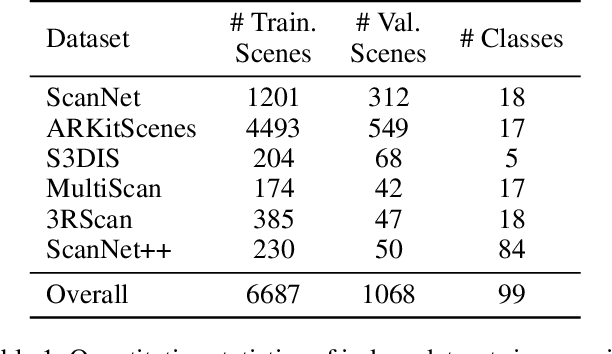
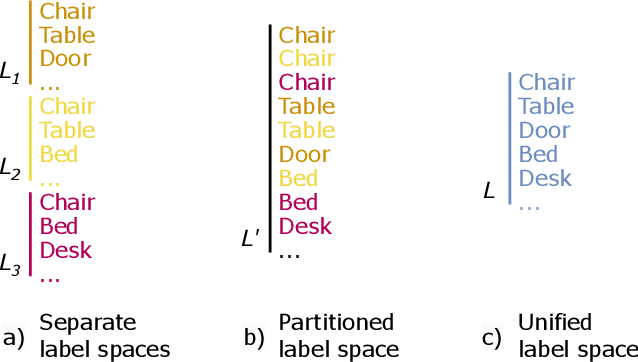
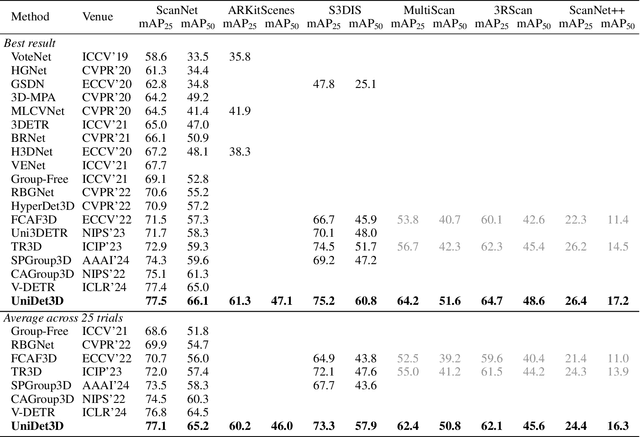
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose \ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, \ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that \ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
SUPER: Selfie Undistortion and Head Pose Editing with Identity Preservation
Jun 18, 2024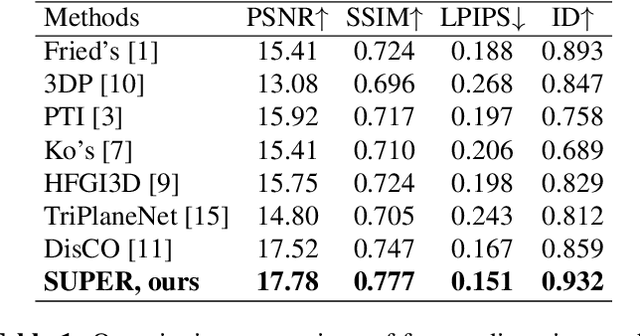
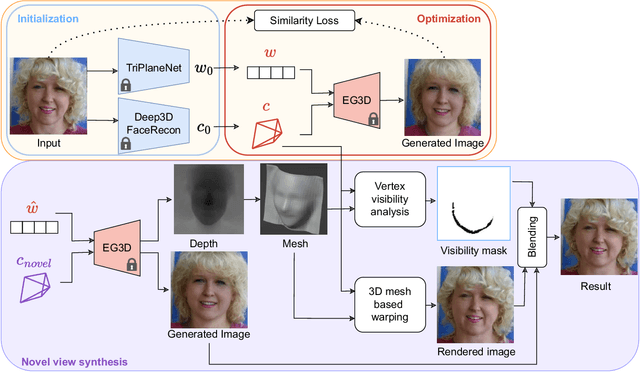
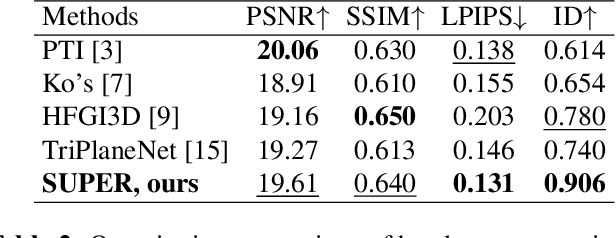

Self-portraits captured from a short distance might look unnatural or even unattractive due to heavy distortions making facial features malformed, and ill-placed head poses. In this paper, we propose SUPER, a novel method of eliminating distortions and adjusting head pose in a close-up face crop. We perform 3D GAN inversion for a facial image by optimizing camera parameters and face latent code, which gives a generated image. Besides, we estimate depth from the obtained latent code, create a depth-induced 3D mesh, and render it with updated camera parameters to obtain a warped portrait. Finally, we apply the visibility-based blending so that visible regions are reprojected, and occluded parts are restored with a generative model. Experiments on face undistortion benchmarks and on our self-collected Head Rotation dataset (HeRo), show that SUPER outperforms previous approaches both qualitatively and quantitatively, opening new possibilities for photorealistic selfie editing.
MEDeA: Multi-view Efficient Depth Adjustment
Jun 17, 2024The majority of modern single-view depth estimation methods predict relative depth and thus cannot be directly applied in many real-world scenarios, despite impressive performance in the benchmarks. Moreover, single-view approaches cannot guarantee consistency across a sequence of frames. Consistency is typically addressed with test-time optimization of discrepancy across views; however, it takes hours to process a single scene. In this paper, we present MEDeA, an efficient multi-view test-time depth adjustment method, that is an order of magnitude faster than existing test-time approaches. Given RGB frames with camera parameters, MEDeA predicts initial depth maps, adjusts them by optimizing local scaling coefficients, and outputs temporally-consistent depth maps. Contrary to test-time methods requiring normals, optical flow, or semantics estimation, MEDeA produces high-quality predictions with a depth estimation network solely. Our method sets a new state-of-the-art on TUM RGB-D, 7Scenes, and ScanNet benchmarks and successfully handles smartphone-captured data from ARKitScenes dataset.
FAWN: Floor-And-Walls Normal Regularization for Direct Neural TSDF Reconstruction
Jun 17, 2024



Leveraging 3D semantics for direct 3D reconstruction has a great potential yet unleashed. For instance, by assuming that walls are vertical, and a floor is planar and horizontal, we can correct distorted room shapes and eliminate local artifacts such as holes, pits, and hills. In this paper, we propose FAWN, a modification of truncated signed distance function (TSDF) reconstruction methods, which considers scene structure by detecting walls and floor in a scene, and penalizing the corresponding surface normals for deviating from the horizontal and vertical directions. Implemented as a 3D sparse convolutional module, FAWN can be incorporated into any trainable pipeline that predicts TSDF. Since FAWN requires 3D semantics only for training, no additional limitations on further use are imposed. We demonstrate, that FAWN-modified methods use semantics more effectively, than existing semantic-based approaches. Besides, we apply our modification to state-of-the-art TSDF reconstruction methods, and demonstrate a quality gain in SCANNET, ICL-NUIM, TUM RGB-D, and 7SCENES benchmarks.
TETRIS: Towards Exploring the Robustness of Interactive Segmentation
Feb 09, 2024Interactive segmentation methods rely on user inputs to iteratively update the selection mask. A click specifying the object of interest is arguably the most simple and intuitive interaction type, and thereby the most common choice for interactive segmentation. However, user clicking patterns in the interactive segmentation context remain unexplored. Accordingly, interactive segmentation evaluation strategies rely more on intuition and common sense rather than empirical studies (e.g., assuming that users tend to click in the center of the area with the largest error). In this work, we conduct a real user study to investigate real user clicking patterns. This study reveals that the intuitive assumption made in the common evaluation strategy may not hold. As a result, interactive segmentation models may show high scores in the standard benchmarks, but it does not imply that they would perform well in a real world scenario. To assess the applicability of interactive segmentation methods, we propose a novel evaluation strategy providing a more comprehensive analysis of a model's performance. To this end, we propose a methodology for finding extreme user inputs by a direct optimization in a white-box adversarial attack on the interactive segmentation model. Based on the performance with such adversarial user inputs, we assess the robustness of interactive segmentation models w.r.t click positions. Besides, we introduce a novel benchmark for measuring the robustness of interactive segmentation, and report the results of an extensive evaluation of dozens of models.
OneFormer3D: One Transformer for Unified Point Cloud Segmentation
Nov 24, 2023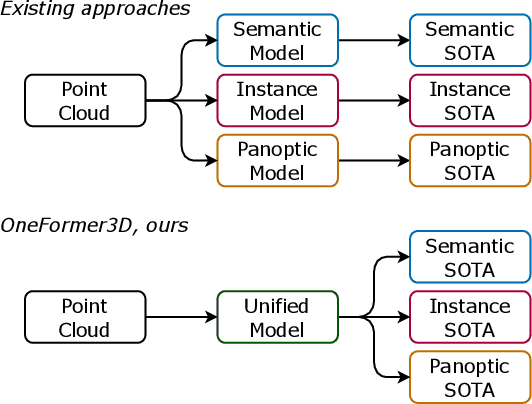



Semantic, instance, and panoptic segmentation of 3D point clouds have been addressed using task-specific models of distinct design. Thereby, the similarity of all segmentation tasks and the implicit relationship between them have not been utilized effectively. This paper presents a unified, simple, and effective model addressing all these tasks jointly. The model, named OneFormer3D, performs instance and semantic segmentation consistently, using a group of learnable kernels, where each kernel is responsible for generating a mask for either an instance or a semantic category. These kernels are trained with a transformer-based decoder with unified instance and semantic queries passed as an input. Such a design enables training a model end-to-end in a single run, so that it achieves top performance on all three segmentation tasks simultaneously. Specifically, our OneFormer3D ranks 1st and sets a new state-of-the-art (+2.1 mAP50) in the ScanNet test leaderboard. We also demonstrate the state-of-the-art results in semantic, instance, and panoptic segmentation of ScanNet (+21 PQ), ScanNet200 (+3.8 mAP50), and S3DIS (+0.8 mIoU) datasets.
Single-Stage 3D Geometry-Preserving Depth Estimation Model Training on Dataset Mixtures with Uncalibrated Stereo Data
Jun 05, 2023



Nowadays, robotics, AR, and 3D modeling applications attract considerable attention to single-view depth estimation (SVDE) as it allows estimating scene geometry from a single RGB image. Recent works have demonstrated that the accuracy of an SVDE method hugely depends on the diversity and volume of the training data. However, RGB-D datasets obtained via depth capturing or 3D reconstruction are typically small, synthetic datasets are not photorealistic enough, and all these datasets lack diversity. The large-scale and diverse data can be sourced from stereo images or stereo videos from the web. Typically being uncalibrated, stereo data provides disparities up to unknown shift (geometrically incomplete data), so stereo-trained SVDE methods cannot recover 3D geometry. It was recently shown that the distorted point clouds obtained with a stereo-trained SVDE method can be corrected with additional point cloud modules (PCM) separately trained on the geometrically complete data. On the contrary, we propose GP$^{2}$, General-Purpose and Geometry-Preserving training scheme, and show that conventional SVDE models can learn correct shifts themselves without any post-processing, benefiting from using stereo data even in the geometry-preserving setting. Through experiments on different dataset mixtures, we prove that GP$^{2}$-trained models outperform methods relying on PCM in both accuracy and speed, and report the state-of-the-art results in the general-purpose geometry-preserving SVDE. Moreover, we show that SVDE models can learn to predict geometrically correct depth even when geometrically complete data comprises the minor part of the training set.
Contour-based Interactive Segmentation
Feb 13, 2023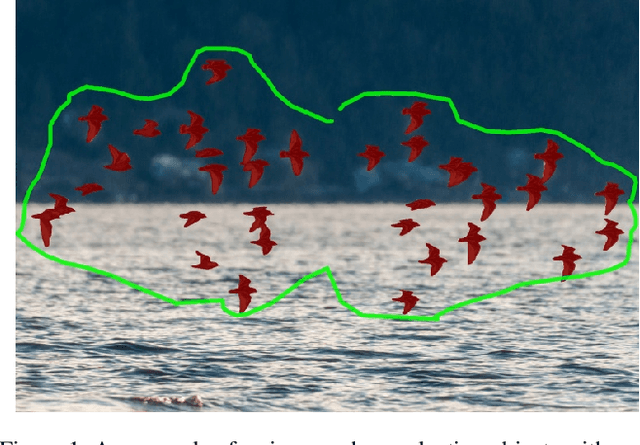
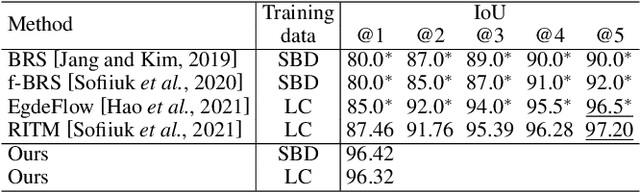
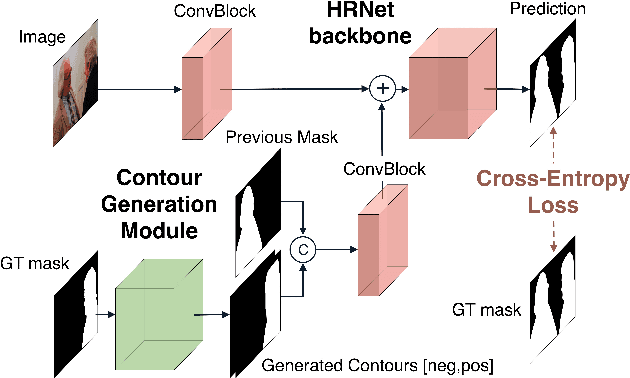
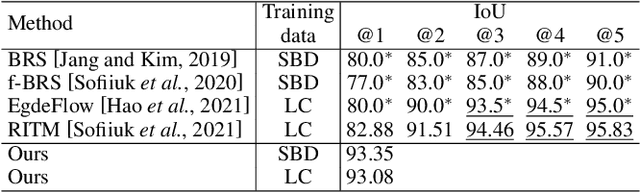
Recent advances in interactive segmentation (IS) allow speeding up and simplifying image editing and labeling greatly. The majority of modern IS approaches accept user input in the form of clicks. However, using clicks may require too many user interactions, especially when selecting small objects, minor parts of an object, or a group of objects of the same type. In this paper, we consider such a natural form of user interaction as a loose contour, and introduce a contour-based IS method. We evaluate the proposed method on the standard segmentation benchmarks, our novel UserContours dataset, and its subset UserContours-G containing difficult segmentation cases. Through experiments, we demonstrate that a single contour provides the same accuracy as multiple clicks, thus reducing the required amount of user interactions.
TR3D: Towards Real-Time Indoor 3D Object Detection
Feb 08, 2023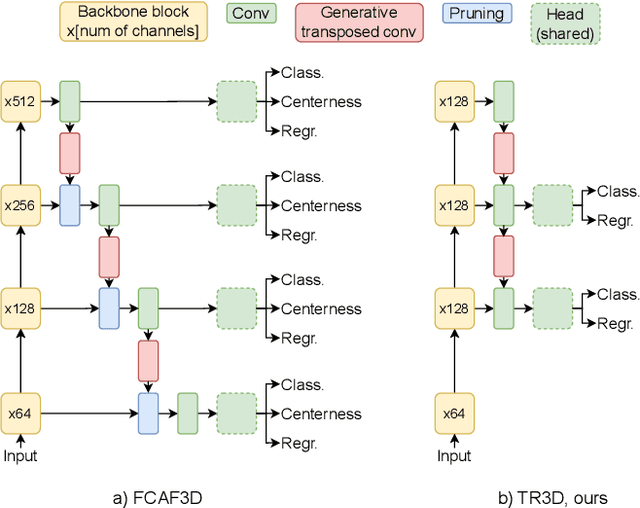
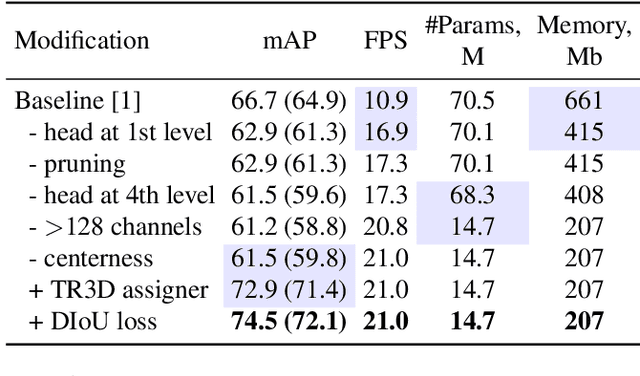

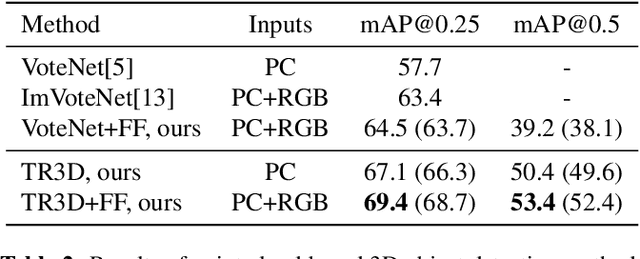
Recently, sparse 3D convolutions have changed 3D object detection. Performing on par with the voting-based approaches, 3D CNNs are memory-efficient and scale to large scenes better. However, there is still room for improvement. With a conscious, practice-oriented approach to problem-solving, we analyze the performance of such methods and localize the weaknesses. Applying modifications that resolve the found issues one by one, we end up with TR3D: a fast fully-convolutional 3D object detection model trained end-to-end, that achieves state-of-the-art results on the standard benchmarks, ScanNet v2, SUN RGB-D, and S3DIS. Moreover, to take advantage of both point cloud and RGB inputs, we introduce an early fusion of 2D and 3D features. We employ our fusion module to make conventional 3D object detection methods multimodal and demonstrate an impressive boost in performance. Our model with early feature fusion, which we refer to as TR3D+FF, outperforms existing 3D object detection approaches on the SUN RGB-D dataset. Overall, besides being accurate, both TR3D and TR3D+FF models are lightweight, memory-efficient, and fast, thereby marking another milestone on the way toward real-time 3D object detection. Code is available at https://github.com/SamsungLabs/tr3d .