 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAWN: Floor-And-Walls Normal Regularization for Direct Neural TSDF Reconstruction
Jun 17, 2024



Leveraging 3D semantics for direct 3D reconstruction has a great potential yet unleashed. For instance, by assuming that walls are vertical, and a floor is planar and horizontal, we can correct distorted room shapes and eliminate local artifacts such as holes, pits, and hills. In this paper, we propose FAWN, a modification of truncated signed distance function (TSDF) reconstruction methods, which considers scene structure by detecting walls and floor in a scene, and penalizing the corresponding surface normals for deviating from the horizontal and vertical directions. Implemented as a 3D sparse convolutional module, FAWN can be incorporated into any trainable pipeline that predicts TSDF. Since FAWN requires 3D semantics only for training, no additional limitations on further use are imposed. We demonstrate, that FAWN-modified methods use semantics more effectively, than existing semantic-based approaches. Besides, we apply our modification to state-of-the-art TSDF reconstruction methods, and demonstrate a quality gain in SCANNET, ICL-NUIM, TUM RGB-D, and 7SCENES benchmarks.
MEDeA: Multi-view Efficient Depth Adjustment
Jun 17, 2024The majority of modern single-view depth estimation methods predict relative depth and thus cannot be directly applied in many real-world scenarios, despite impressive performance in the benchmarks. Moreover, single-view approaches cannot guarantee consistency across a sequence of frames. Consistency is typically addressed with test-time optimization of discrepancy across views; however, it takes hours to process a single scene. In this paper, we present MEDeA, an efficient multi-view test-time depth adjustment method, that is an order of magnitude faster than existing test-time approaches. Given RGB frames with camera parameters, MEDeA predicts initial depth maps, adjusts them by optimizing local scaling coefficients, and outputs temporally-consistent depth maps. Contrary to test-time methods requiring normals, optical flow, or semantics estimation, MEDeA produces high-quality predictions with a depth estimation network solely. Our method sets a new state-of-the-art on TUM RGB-D, 7Scenes, and ScanNet benchmarks and successfully handles smartphone-captured data from ARKitScenes dataset.
Floorplan-Aware Camera Poses Refinement
Oct 10, 2022
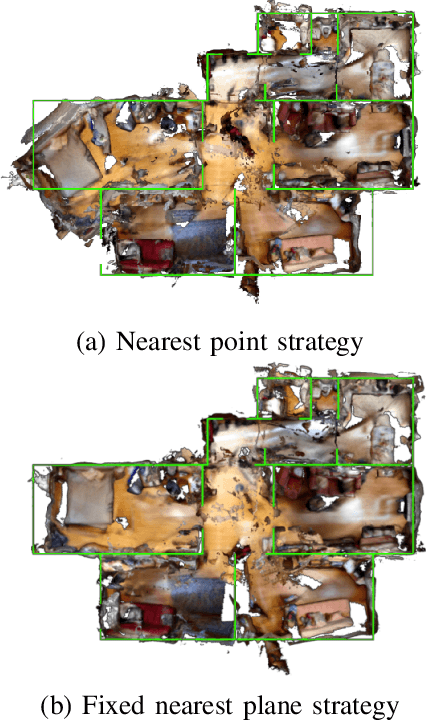
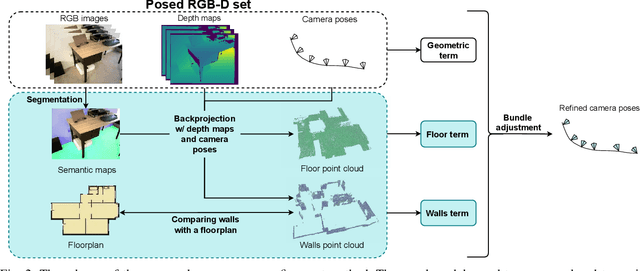

Processing large indoor scenes is a challenging task, as scan registration and camera trajectory estimation methods accumulate errors across time. As a result, the quality of reconstructed scans is insufficient for some applications, such as visual-based localization and navigation, where the correct position of walls is crucial. For many indoor scenes, there exists an image of a technical floorplan that contains information about the geometry and main structural elements of the scene, such as walls, partitions, and doors. We argue that such a floorplan is a useful source of spatial information, which can guide a 3D model optimization. The standard RGB-D 3D reconstruction pipeline consists of a tracking module applied to an RGB-D sequence and a bundle adjustment (BA) module that takes the posed RGB-D sequence and corrects the camera poses to improve consistency. We propose a novel optimization algorithm expanding conventional BA that leverages the prior knowledge about the scene structure in the form of a floorplan. Our experiments on the Redwood dataset and our self-captured data demonstrate that utilizing floorplan improves accuracy of 3D reconstructions.
Pose-based Deep Gait Recognition
Feb 08, 2018


Human gait or walking manner is a biometric feature that allows identification of a person when other biometric features such as the face or iris are not visible. In this paper, we present a new pose-based convolutional neural network model for gait recognition. Unlike many methods that consider the full-height silhouette of a moving person, we consider the motion of points in the areas around human joints. To extract motion information, we estimate the optical flow between consecutive frames. We propose a deep convolutional model that computes pose-based gait descriptors. We compare different network architectures and aggregation methods and experimentally assess various sets of body parts to determine which are the most important for gait recognition. In addition, we investigate the generalization ability of the developed algorithms by transferring them between datasets. The results of these experiments show that our approach outperforms state-of-the-art methods.