 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUPER: Selfie Undistortion and Head Pose Editing with Identity Preservation
Jun 18, 2024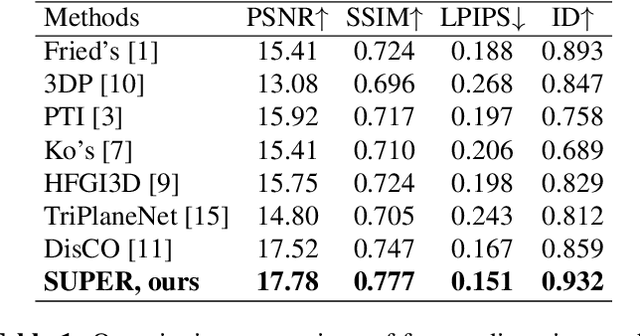
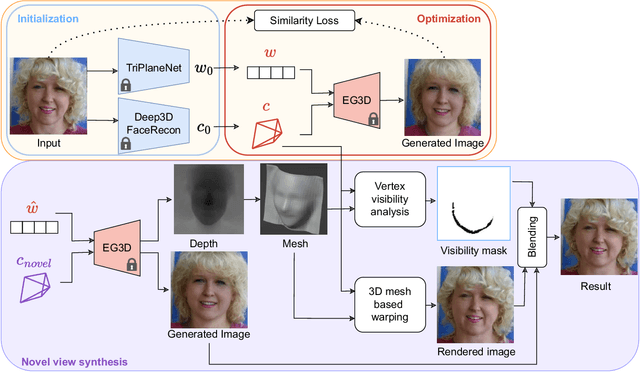
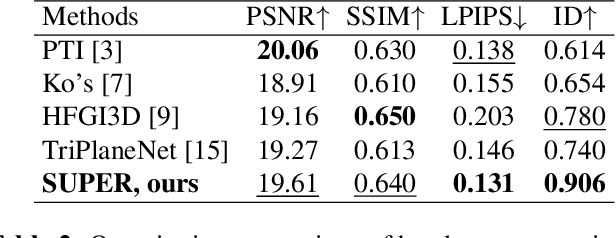

Self-portraits captured from a short distance might look unnatural or even unattractive due to heavy distortions making facial features malformed, and ill-placed head poses. In this paper, we propose SUPER, a novel method of eliminating distortions and adjusting head pose in a close-up face crop. We perform 3D GAN inversion for a facial image by optimizing camera parameters and face latent code, which gives a generated image. Besides, we estimate depth from the obtained latent code, create a depth-induced 3D mesh, and render it with updated camera parameters to obtain a warped portrait. Finally, we apply the visibility-based blending so that visible regions are reprojected, and occluded parts are restored with a generative model. Experiments on face undistortion benchmarks and on our self-collected Head Rotation dataset (HeRo), show that SUPER outperforms previous approaches both qualitatively and quantitatively, opening new possibilities for photorealistic selfie editing.
MEDeA: Multi-view Efficient Depth Adjustment
Jun 17, 2024The majority of modern single-view depth estimation methods predict relative depth and thus cannot be directly applied in many real-world scenarios, despite impressive performance in the benchmarks. Moreover, single-view approaches cannot guarantee consistency across a sequence of frames. Consistency is typically addressed with test-time optimization of discrepancy across views; however, it takes hours to process a single scene. In this paper, we present MEDeA, an efficient multi-view test-time depth adjustment method, that is an order of magnitude faster than existing test-time approaches. Given RGB frames with camera parameters, MEDeA predicts initial depth maps, adjusts them by optimizing local scaling coefficients, and outputs temporally-consistent depth maps. Contrary to test-time methods requiring normals, optical flow, or semantics estimation, MEDeA produces high-quality predictions with a depth estimation network solely. Our method sets a new state-of-the-art on TUM RGB-D, 7Scenes, and ScanNet benchmarks and successfully handles smartphone-captured data from ARKitScenes dataset.
FAWN: Floor-And-Walls Normal Regularization for Direct Neural TSDF Reconstruction
Jun 17, 2024



Leveraging 3D semantics for direct 3D reconstruction has a great potential yet unleashed. For instance, by assuming that walls are vertical, and a floor is planar and horizontal, we can correct distorted room shapes and eliminate local artifacts such as holes, pits, and hills. In this paper, we propose FAWN, a modification of truncated signed distance function (TSDF) reconstruction methods, which considers scene structure by detecting walls and floor in a scene, and penalizing the corresponding surface normals for deviating from the horizontal and vertical directions. Implemented as a 3D sparse convolutional module, FAWN can be incorporated into any trainable pipeline that predicts TSDF. Since FAWN requires 3D semantics only for training, no additional limitations on further use are imposed. We demonstrate, that FAWN-modified methods use semantics more effectively, than existing semantic-based approaches. Besides, we apply our modification to state-of-the-art TSDF reconstruction methods, and demonstrate a quality gain in SCANNET, ICL-NUIM, TUM RGB-D, and 7SCENES benchmarks.