 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Geometry Representations for Vision-and-Language Navigation from Web Videos
Mar 10, 2026Vision-and-Language Navigation (VLN) has long been constrained by the limited diversity and scalability of simulator-curated datasets, which fail to capture the complexity of real-world environments. To overcome this limitation, we introduce a large-scale video-instruction framework derived from web-based room tour videos, enabling agents to learn from natural human walking demonstrations in diverse, realistic indoor settings. Unlike existing datasets, our framework integrates both open-ended description-enriched trajectories and action-enriched trajectories reconstructed in 3D, providing richer spatial and semantic supervision. A key extension in this work is the incorporation of implicit geometry representations, which extract spatial cues directly from RGB frames without requiring fragile 3D reconstruction. This approach substantially improves data utilization, alleviates reconstruction failures, and unlocks large portions of previously unusable video data. Comprehensive experiments across multiple VLN benchmarks (CVDN, SOON, R2R, and REVERIE) demonstrate that our method not only sets new state-of-the-art performance but also enables the development of robust zero-shot navigation agents. By bridging large-scale web videos with implicit spatial reasoning, this work advances embodied navigation towards more scalable, generalizable, and real-world applicable solutions.
RoomTour3D: Geometry-Aware Video-Instruction Tuning for Embodied Navigation
Dec 11, 2024Vision-and-Language Navigation (VLN) suffers from the limited diversity and scale of training data, primarily constrained by the manual curation of existing simulators. To address this, we introduce RoomTour3D, a video-instruction dataset derived from web-based room tour videos that capture real-world indoor spaces and human walking demonstrations. Unlike existing VLN datasets, RoomTour3D leverages the scale and diversity of online videos to generate open-ended human walking trajectories and open-world navigable instructions. To compensate for the lack of navigation data in online videos, we perform 3D reconstruction and obtain 3D trajectories of walking paths augmented with additional information on the room types, object locations and 3D shape of surrounding scenes. Our dataset includes $\sim$100K open-ended description-enriched trajectories with $\sim$200K instructions, and 17K action-enriched trajectories from 1847 room tour environments. We demonstrate experimentally that RoomTour3D enables significant improvements across multiple VLN tasks including CVDN, SOON, R2R, and REVERIE. Moreover, RoomTour3D facilitates the development of trainable zero-shot VLN agents, showcasing the potential and challenges of advancing towards open-world navigation.
SUPER: Selfie Undistortion and Head Pose Editing with Identity Preservation
Jun 18, 2024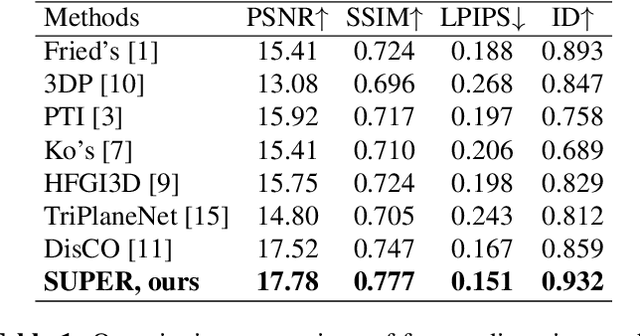
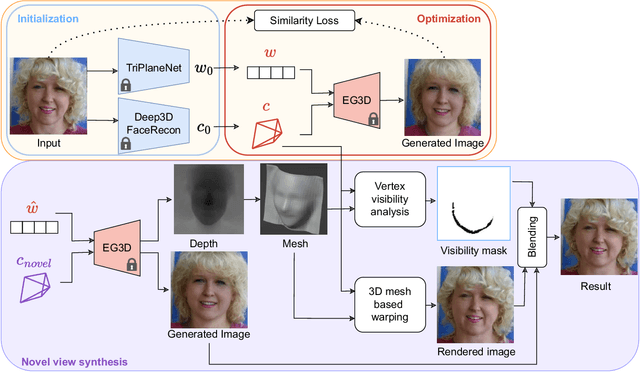
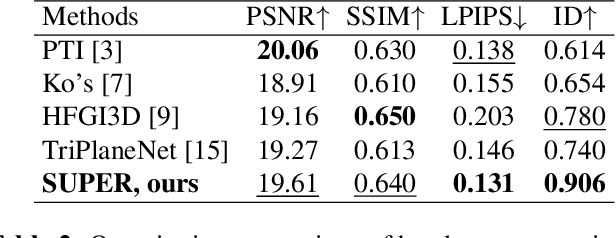

Self-portraits captured from a short distance might look unnatural or even unattractive due to heavy distortions making facial features malformed, and ill-placed head poses. In this paper, we propose SUPER, a novel method of eliminating distortions and adjusting head pose in a close-up face crop. We perform 3D GAN inversion for a facial image by optimizing camera parameters and face latent code, which gives a generated image. Besides, we estimate depth from the obtained latent code, create a depth-induced 3D mesh, and render it with updated camera parameters to obtain a warped portrait. Finally, we apply the visibility-based blending so that visible regions are reprojected, and occluded parts are restored with a generative model. Experiments on face undistortion benchmarks and on our self-collected Head Rotation dataset (HeRo), show that SUPER outperforms previous approaches both qualitatively and quantitatively, opening new possibilities for photorealistic selfie editing.