 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActCam: Zero-Shot Joint Camera and 3D Motion Control for Video Generation
May 07, 2026For artistic applications, video generation requires fine-grained control over both performance and cinematography, i.e., the actor's motion and the camera trajectory. We present ActCam, a zero-shot method for video generation that jointly transfers character motion from a driving video into a new scene and enables per-frame control of intrinsic and extrinsic camera parameters. ActCam builds on any pretrained image-to-video diffusion model that accepts conditioning in terms of scene depth and character pose. Given a source video with a moving character and a target camera motion, ActCam generates pose and depth conditions that remain geometrically consistent across frames. We then run a single sampling process with a two-phase conditioning schedule: early denoising steps condition on both pose and sparse depth to enforce scene structure, after which depth is dropped and pose-only guidance refines high-frequency details without over-constraining the generation. We evaluate ActCam on multiple benchmarks spanning diverse character motions and challenging viewpoint changes. We find that, compared to pose-only control and other pose and camera methods, ActCam improves camera adherence and motion fidelity, and is preferred in human evaluations, especially under large viewpoint changes. Our results highlight that careful camera-consistent conditioning and staged guidance can enable strong joint camera and motion control without training. Project page: https://elkhomar.github.io/actcam/.
LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
A1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Apr 07, 2026Vision--Language--Action (VLA) models have emerged as a powerful paradigm for open-world robot manipulation, but their practical deployment is often constrained by \emph{cost}: billion-scale VLM backbones and iterative diffusion/flow-based action heads incur high latency and compute, making real-time control expensive on commodity hardware. We present A1, a fully open-source and transparent VLA framework designed for low-cost, high-throughput inference without sacrificing manipulation success; Our approach leverages pretrained VLMs that provide implicit affordance priors for action generation. We release the full training stack (training code, data/data-processing pipeline, intermediate checkpoints, and evaluation scripts) to enable end-to-end reproducibility. Beyond optimizing the VLM alone, A1 targets the full inference pipeline by introducing a budget-aware adaptive inference scheme that jointly accelerates the backbone and the \emph{action head}. Specifically, we monitor action consistency across intermediate VLM layers to trigger early termination, and propose Inter-Layer Truncated Flow Matching that warm-starts denoising across layers, enabling accurate actions with substantially fewer effective denoising iterations. Across simulation benchmarks (LIBERO, VLABench) and real robots (Franka, AgiBot), A1 achieves state-of-the-art success rates while significantly reducing inference cost (e.g., up to 72% lower per-episode latency for flow-matching inference and up to 76.6% backbone computation reduction with minor performance degradation). On RoboChallenge, A1 achieves an average success rate of 29.00%, outperforming baselines including pi0(28.33%), X-VLA (21.33%), and RDT-1B (15.00%).
ManipArena: Comprehensive Real-world Evaluation of Reasoning-Oriented Generalist Robot Manipulation
Mar 30, 2026Vision-Language-Action (VLA) models and world models have recently emerged as promising paradigms for general-purpose robotic intelligence, yet their progress is hindered by the lack of reliable evaluation protocols that reflect real-world deployment. Existing benchmarks are largely simulator-centric, which provide controllability but fail to capture the reality gap caused by perception noise, complex contact dynamics, hardware constraints, and system latency. Moreover, fragmented real-world evaluations across different robot platforms prevent fair and reproducible comparison. To address these challenges, we introduce ManipArena, a standardized evaluation framework designed to bridge simulation and real-world execution. ManipArena comprises 20 diverse tasks across 10,812 expert trajectories emphasizing reasoning-oriented manipulation tasks requiring semantic and spatial reasoning, supports multi-level generalization through controlled out-of-distribution settings, and incorporates long-horizon mobile manipulation beyond tabletop scenarios. The framework further provides rich sensory diagnostics, including low-level motor signals, and synchronized real-to-sim environments constructed via high-quality 3D scanning. Together, these features enable fair, realistic, and reproducible evaluation for both VLA and world model approaches, providing a scalable foundation for diagnosing and advancing embodied intelligence systems.
MessyKitchens: Contact-rich object-level 3D scene reconstruction
Mar 17, 2026Monocular 3D scene reconstruction has recently seen significant progress. Powered by the modern neural architectures and large-scale data, recent methods achieve high performance in depth estimation from a single image. Meanwhile, reconstructing and decomposing common scenes into individual 3D objects remains a hard challenge due to the large variety of objects, frequent occlusions and complex object relations. Notably, beyond shape and pose estimation of individual objects, applications in robotics and animation require physically-plausible scene reconstruction where objects obey physical principles of non-penetration and realistic contacts. In this work we advance object-level scene reconstruction along two directions. First, we introduceMessyKitchens, a new dataset with real-world scenes featuring cluttered environments and providing high-fidelity object-level ground truth in terms of 3D object shapes, poses and accurate object contacts. Second, we build on the recent SAM 3D approach for single-object reconstruction and extend it with Multi-Object Decoder (MOD) for joint object-level scene reconstruction. To validate our contributions, we demonstrate MessyKitchens to significantly improve previous datasets in registration accuracy and inter-object penetration. We also compare our multi-object reconstruction approach on three datasets and demonstrate consistent and significant improvements of MOD over the state of the art. Our new benchmark, code and pre-trained models will become publicly available on our project website: https://messykitchens.github.io/.
PhysMoDPO: Physically-Plausible Humanoid Motion with Preference Optimization
Mar 16, 2026Recent progress in text-conditioned human motion generation has been largely driven by diffusion models trained on large-scale human motion data. Building on this progress, recent methods attempt to transfer such models for character animation and real robot control by applying a Whole-Body Controller (WBC) that converts diffusion-generated motions into executable trajectories. While WBC trajectories become compliant with physics, they may expose substantial deviations from original motion. To address this issue, we here propose PhysMoDPO, a Direct Preference Optimization framework. Unlike prior work that relies on hand-crafted physics-aware heuristics such as foot-sliding penalties, we integrate WBC into our training pipeline and optimize diffusion model such that the output of WBC becomes compliant both with physics and original text instructions. To train PhysMoDPO we deploy physics-based and task-specific rewards and use them to assign preference to synthesized trajectories. Our extensive experiments on text-to-motion and spatial control tasks demonstrate consistent improvements of PhysMoDPO in both physical realism and task-related metrics on simulated robots. Moreover, we demonstrate that PhysMoDPO results in significant improvements when applied to zero-shot motion transfer in simulation and for real-world deployment on a G1 humanoid robot.
World2Act: Latent Action Post-Training via Skill-Compositional World Models
Mar 11, 2026World Models (WMs) have emerged as a promising approach for post-training Vision-Language-Action (VLA) policies to improve robustness and generalization under environmental changes. However, most WM-based post-training methods rely on pixel-space supervision, making policies sensitive to pixel-level artifacts and hallucination from imperfect WM rollouts. We introduce World2Act, a post-training framework that aligns VLA actions directly with WM video-dynamics latents using a contrastive matching objective, reducing dependence on pixels. Post-training performance is tied to rollout quality, yet current WMs struggle with arbitrary-length video generation as they are mostly trained on fixed-length clips while robotic execution durations vary widely. To address this, we propose an automatic LLM-based skill-decomposition pipeline that segments high-level instructions into low-level prompts. Our pipeline produces RoboCasa-Skill and LIBERO-Skill, supporting skill-compositional WMs that remain temporally consistent across diverse task horizons. Empirically, applying World2Act to VLAs like GR00T-N1.6 and Cosmos Policy achieves state-of-the-art results on RoboCasa and LIBERO, and improves real-world performance by 6.7%, enhancing embodied agent generalization.
Implicit Geometry Representations for Vision-and-Language Navigation from Web Videos
Mar 10, 2026Vision-and-Language Navigation (VLN) has long been constrained by the limited diversity and scalability of simulator-curated datasets, which fail to capture the complexity of real-world environments. To overcome this limitation, we introduce a large-scale video-instruction framework derived from web-based room tour videos, enabling agents to learn from natural human walking demonstrations in diverse, realistic indoor settings. Unlike existing datasets, our framework integrates both open-ended description-enriched trajectories and action-enriched trajectories reconstructed in 3D, providing richer spatial and semantic supervision. A key extension in this work is the incorporation of implicit geometry representations, which extract spatial cues directly from RGB frames without requiring fragile 3D reconstruction. This approach substantially improves data utilization, alleviates reconstruction failures, and unlocks large portions of previously unusable video data. Comprehensive experiments across multiple VLN benchmarks (CVDN, SOON, R2R, and REVERIE) demonstrate that our method not only sets new state-of-the-art performance but also enables the development of robust zero-shot navigation agents. By bridging large-scale web videos with implicit spatial reasoning, this work advances embodied navigation towards more scalable, generalizable, and real-world applicable solutions.
Choose What to Observe: Task-Aware Semantic-Geometric Representations for Visuomotor Policy
Mar 09, 2026Visuomotor policies learned from demonstrations often overfit to nuisance visual factors in raw RGB observations, resulting in brittle behavior under appearance shifts such as background changes and object recoloring. We propose a task-aware observation interface that canonicalizes visual input into a shared representation, improving robustness to out-of-distribution (OOD) appearance changes without modifying or fine-tuning the policy. Given an RGB image and an open-vocabulary specification of task-relevant entities, we use SAM3 to segment the target object and robot/gripper. We construct an L0 observation by repainting segmented entities with predefined semantic colors on a constant background. For tasks requiring stronger geometric cues, we further inject monocular depth from Depth Anything 3 into the segmented regions via depth-guided overwrite, yielding a unified semantic--geometric observation (L1) that remains a standard 3-channel, image-like input. We evaluate on RoboMimic (Lift), ManiSkill YCB grasping under clutter, four RLBench tasks under controlled appearance shifts, and two real-world Franka tasks (ReachX and CloseCabinet). Across benchmarks and policy backbones (Flow Matching Policy and SmolVLA), our interface preserves in-distribution performance while substantially improving robustness under OOD visual shifts.
GLaD: Geometric Latent Distillation for Vision-Language-Action Models
Dec 10, 2025
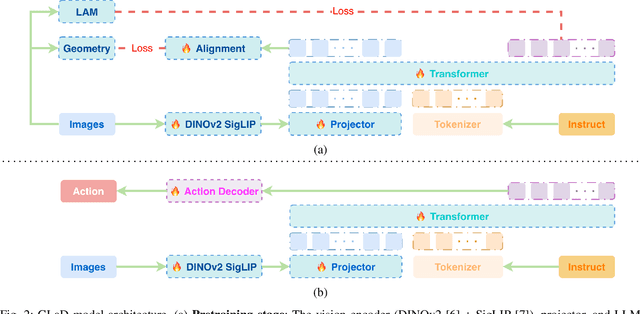
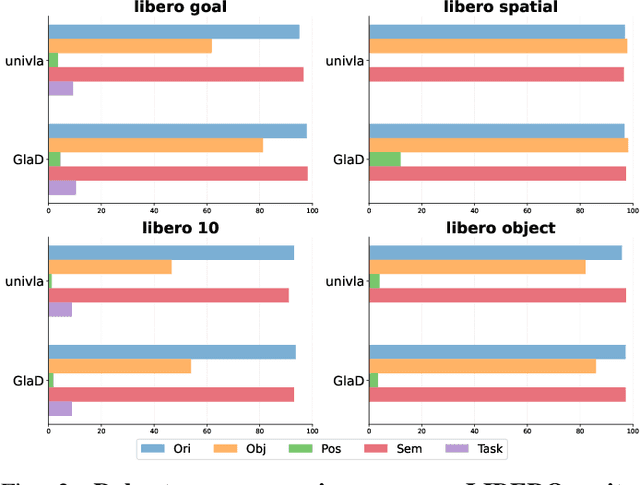

Most existing Vision-Language-Action (VLA) models rely primarily on RGB information, while ignoring geometric cues crucial for spatial reasoning and manipulation. In this work, we introduce GLaD, a geometry-aware VLA framework that incorporates 3D geometric priors during pretraining through knowledge distillation. Rather than distilling geometric features solely into the vision encoder, we align the LLM's hidden states corresponding to visual tokens with features from a frozen geometry-aware vision transformer (VGGT), ensuring that geometric understanding is deeply integrated into the multimodal representations that drive action prediction. Pretrained on the Bridge dataset with this geometry distillation mechanism, GLaD achieves 94.1% average success rate across four LIBERO task suites, outperforming UniVLA (92.5%) which uses identical pretraining data. These results validate that geometry-aware pretraining enhances spatial reasoning and policy generalization without requiring explicit depth sensors or 3D annotations.