 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePO-VLA: Recovery-Driven Policy Optimization for Vision-Language-Action Models
May 10, 2026Vision-Language-Action (VLA) models remain brittle in long-horizon, contact-rich manipulation because success-only imitation provides little supervision for execution drift, while failed rollouts are often discarded. We introduce RePO-VLA, a recovery-driven policy optimization framework that assigns distinct roles to success, recovery, and failure trajectories. RePO-VLA first applies Recovery-Aware Initialization (RAI), slicing recovery segments and resetting history so corrective actions depend on the current adverse state rather than the preceding failure. It then learns a Progress-Aware Semantic Value Function (PAS-VF), aligning spatiotemporal trajectory features with instructions and successful references. The resulting labels salvage useful failure prefixes via reliability decay, while low-value labels mark drift and terminal breakdowns, teaching differences among nominal, failed, and corrective actions. The data engine turns adverse states into planner-generated or human-collected corrective rollouts, teaching recovery to the success manifold. Value-Conditioned Refinement (VCR) trains the policy to prefer high-progress actions. At deployment, a fixed high value ($v=1.0$) biases actions toward the learned success manifold without online failure detectors or heuristic retries. We introduce FRBench, with standardized error injection and recovery-focused evaluation. Across simulated and real-world bimanual tasks, RePO-VLA improves robustness, raising adversarial success from 20% to 75% on average and up to 80% in scaled real-world trials.
PhyBlock: A Progressive Benchmark for Physical Understanding and Planning via 3D Block Assembly
Jun 10, 2025While vision-language models (VLMs) have demonstrated promising capabilities in reasoning and planning for embodied agents, their ability to comprehend physical phenomena, particularly within structured 3D environments, remains severely limited. To close this gap, we introduce PhyBlock, a progressive benchmark designed to assess VLMs on physical understanding and planning through robotic 3D block assembly tasks. PhyBlock integrates a novel four-level cognitive hierarchy assembly task alongside targeted Visual Question Answering (VQA) samples, collectively aimed at evaluating progressive spatial reasoning and fundamental physical comprehension, including object properties, spatial relationships, and holistic scene understanding. PhyBlock includes 2600 block tasks (400 assembly tasks, 2200 VQA tasks) and evaluates models across three key dimensions: partial completion, failure diagnosis, and planning robustness. We benchmark 21 state-of-the-art VLMs, highlighting their strengths and limitations in physically grounded, multi-step planning. Our empirical findings indicate that the performance of VLMs exhibits pronounced limitations in high-level planning and reasoning capabilities, leading to a notable decline in performance for the growing complexity of the tasks. Error analysis reveals persistent difficulties in spatial orientation and dependency reasoning. Surprisingly, chain-of-thought prompting offers minimal improvements, suggesting spatial tasks heavily rely on intuitive model comprehension. We position PhyBlock as a unified testbed to advance embodied reasoning, bridging vision-language understanding and real-world physical problem-solving.
Structured Preference Optimization for Vision-Language Long-Horizon Task Planning
Feb 28, 2025Existing methods for vision-language task planning excel in short-horizon tasks but often fall short in complex, long-horizon planning within dynamic environments. These challenges primarily arise from the difficulty of effectively training models to produce high-quality reasoning processes for long-horizon tasks. To address this, we propose Structured Preference Optimization (SPO), which aims to enhance reasoning and action selection in long-horizon task planning through structured preference evaluation and optimized training strategies. Specifically, SPO introduces: 1) Preference-Based Scoring and Optimization, which systematically evaluates reasoning chains based on task relevance, visual grounding, and historical consistency; and 2) Curriculum-Guided Training, where the model progressively adapts from simple to complex tasks, improving its generalization ability in long-horizon scenarios and enhancing reasoning robustness. To advance research in vision-language long-horizon task planning, we introduce ExtendaBench, a comprehensive benchmark covering 1,509 tasks across VirtualHome and Habitat 2.0, categorized into ultra-short, short, medium, and long tasks. Experimental results demonstrate that SPO significantly improves reasoning quality and final decision accuracy, outperforming prior methods on long-horizon tasks and underscoring the effectiveness of preference-driven optimization in vision-language task planning. Specifically, SPO achieves a +5.98% GCR and +4.68% SR improvement in VirtualHome and a +3.30% GCR and +2.11% SR improvement in Habitat over the best-performing baselines.
MO-VLN: A Multi-Task Benchmark for Open-set Zero-Shot Vision-and-Language Navigation
Jun 17, 2023
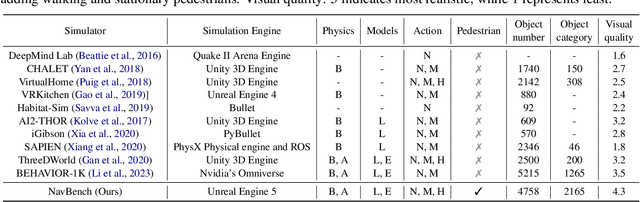


Given a natural language, a general robot has to comprehend the instruction and find the target object or location based on visual observations even in unexplored environments. Most agents rely on massive diverse training data to achieve better generalization, which requires expensive labor. These agents often focus on common objects and fewer tasks, thus are not intelligent enough to handle different types of instructions. To facilitate research in open-set vision-and-language navigation, we propose a benchmark named MO-VLN, aiming at testing the effectiveness and generalization of the agent in the multi-task setting. First, we develop a 3D simulator rendered by realistic scenarios using Unreal Engine 5, containing more realistic lights and details. The simulator contains three scenes, i.e., cafe, restaurant, and nursing house, of high value in the industry. Besides, our simulator involves multiple uncommon objects, such as takeaway cup and medical adhesive tape, which are more complicated compared with existing environments. Inspired by the recent success of large language models (e.g., ChatGPT, Vicuna), we construct diverse high-quality data of instruction type without human annotation. Our benchmark MO-VLN provides four tasks: 1) goal-conditioned navigation given a specific object category (e.g., "fork"); 2) goal-conditioned navigation given simple instructions (e.g., "Search for and move towards a tennis ball"); 3) step-by-step instruction following; 4) finding abstract object based on high-level instruction (e.g., "I am thirsty").
Visual Exemplar Driven Task-Prompting for Unified Perception in Autonomous Driving
Mar 03, 2023Multi-task learning has emerged as a powerful paradigm to solve a range of tasks simultaneously with good efficiency in both computation resources and inference time. However, these algorithms are designed for different tasks mostly not within the scope of autonomous driving, thus making it hard to compare multi-task methods in autonomous driving. Aiming to enable the comprehensive evaluation of present multi-task learning methods in autonomous driving, we extensively investigate the performance of popular multi-task methods on the large-scale driving dataset, which covers four common perception tasks, i.e., object detection, semantic segmentation, drivable area segmentation, and lane detection. We provide an in-depth analysis of current multi-task learning methods under different common settings and find out that the existing methods make progress but there is still a large performance gap compared with single-task baselines. To alleviate this dilemma in autonomous driving, we present an effective multi-task framework, VE-Prompt, which introduces visual exemplars via task-specific prompting to guide the model toward learning high-quality task-specific representations. Specifically, we generate visual exemplars based on bounding boxes and color-based markers, which provide accurate visual appearances of target categories and further mitigate the performance gap. Furthermore, we bridge transformer-based encoders and convolutional layers for efficient and accurate unified perception in autonomous driving. Comprehensive experimental results on the diverse self-driving dataset BDD100K show that the VE-Prompt improves the multi-task baseline and further surpasses single-task models.
NLIP: Noise-robust Language-Image Pre-training
Jan 04, 2023



Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.
Effective Adaptation in Multi-Task Co-Training for Unified Autonomous Driving
Sep 19, 2022
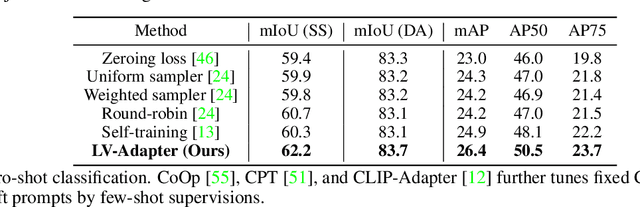
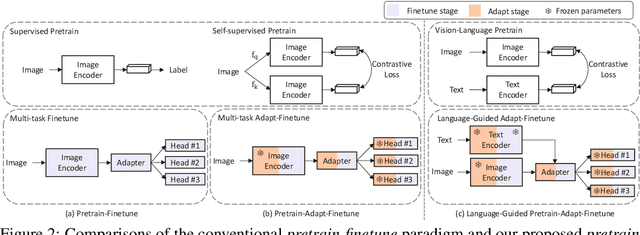

Aiming towards a holistic understanding of multiple downstream tasks simultaneously, there is a need for extracting features with better transferability. Though many latest self-supervised pre-training methods have achieved impressive performance on various vision tasks under the prevailing pretrain-finetune paradigm, their generalization capacity to multi-task learning scenarios is yet to be explored. In this paper, we extensively investigate the transfer performance of various types of self-supervised methods, e.g., MoCo and SimCLR, on three downstream tasks, including semantic segmentation, drivable area segmentation, and traffic object detection, on the large-scale driving dataset BDD100K. We surprisingly find that their performances are sub-optimal or even lag far behind the single-task baseline, which may be due to the distinctions of training objectives and architectural design lied in the pretrain-finetune paradigm. To overcome this dilemma as well as avoid redesigning the resource-intensive pre-training stage, we propose a simple yet effective pretrain-adapt-finetune paradigm for general multi-task training, where the off-the-shelf pretrained models can be effectively adapted without increasing the training overhead. During the adapt stage, we utilize learnable multi-scale adapters to dynamically adjust the pretrained model weights supervised by multi-task objectives while leaving the pretrained knowledge untouched. Furthermore, we regard the vision-language pre-training model CLIP as a strong complement to the pretrain-adapt-finetune paradigm and propose a novel adapter named LV-Adapter, which incorporates language priors in the multi-task model via task-specific prompting and alignment between visual and textual features.
ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts
May 31, 2022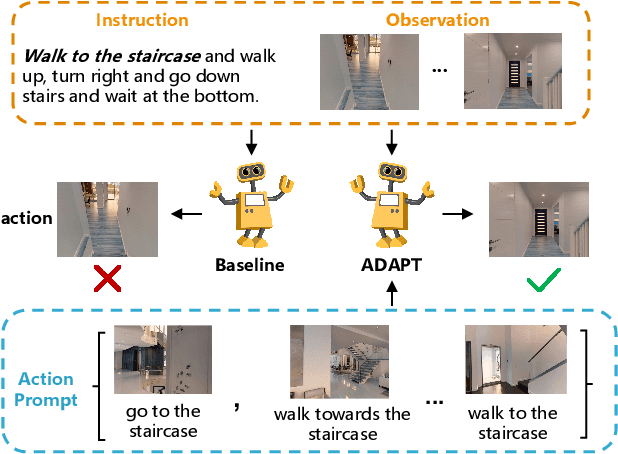

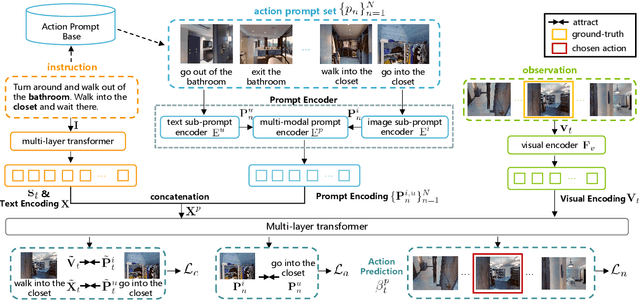

Vision-Language Navigation (VLN) is a challenging task that requires an embodied agent to perform action-level modality alignment, i.e., make instruction-asked actions sequentially in complex visual environments. Most existing VLN agents learn the instruction-path data directly and cannot sufficiently explore action-level alignment knowledge inside the multi-modal inputs. In this paper, we propose modAlity-aligneD Action PrompTs (ADAPT), which provides the VLN agent with action prompts to enable the explicit learning of action-level modality alignment to pursue successful navigation. Specifically, an action prompt is defined as a modality-aligned pair of an image sub-prompt and a text sub-prompt, where the former is a single-view observation and the latter is a phrase like ''walk past the chair''. When starting navigation, the instruction-related action prompt set is retrieved from a pre-built action prompt base and passed through a prompt encoder to obtain the prompt feature. Then the prompt feature is concatenated with the original instruction feature and fed to a multi-layer transformer for action prediction. To collect high-quality action prompts into the prompt base, we use the Contrastive Language-Image Pretraining (CLIP) model which has powerful cross-modality alignment ability. A modality alignment loss and a sequential consistency loss are further introduced to enhance the alignment of the action prompt and enforce the agent to focus on the related prompt sequentially. Experimental results on both R2R and RxR show the superiority of ADAPT over state-of-the-art methods.
Visual-Language Navigation Pretraining via Prompt-based Environmental Self-exploration
Mar 08, 2022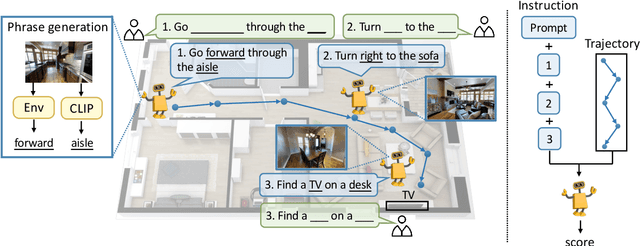

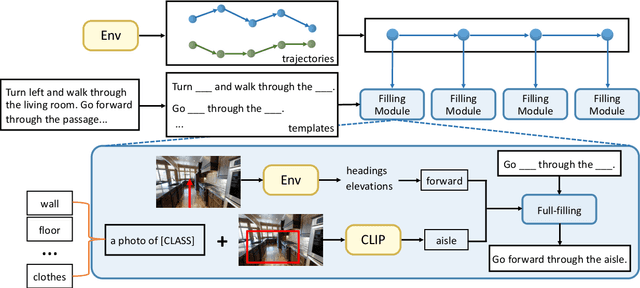
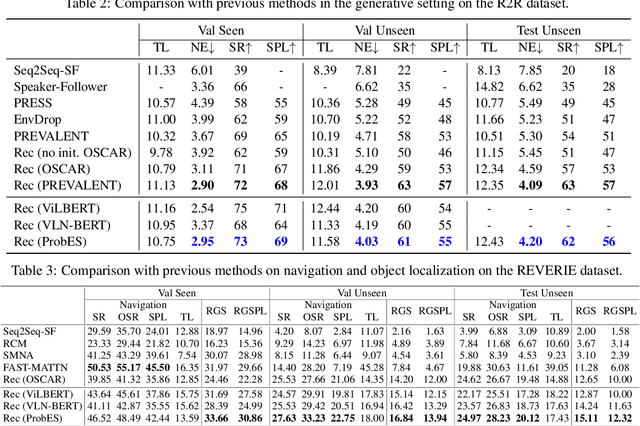
Vision-language navigation (VLN) is a challenging task due to its large searching space in the environment. To address this problem, previous works have proposed some methods of fine-tuning a large model that pretrained on large-scale datasets. However, the conventional fine-tuning methods require extra human-labeled navigation data and lack self-exploration capabilities in environments, which hinders their generalization of unseen scenes. To improve the ability of fast cross-domain adaptation, we propose Prompt-based Environmental Self-exploration (ProbES), which can self-explore the environments by sampling trajectories and automatically generates structured instructions via a large-scale cross-modal pretrained model (CLIP). Our method fully utilizes the knowledge learned from CLIP to build an in-domain dataset by self-exploration without human labeling. Unlike the conventional approach of fine-tuning, we introduce prompt-based learning to achieve fast adaptation for language embeddings, which substantially improves the learning efficiency by leveraging prior knowledge. By automatically synthesizing trajectory-instruction pairs in any environment without human supervision and efficient prompt-based learning, our model can adapt to diverse vision-language navigation tasks, including VLN and REVERIE. Both qualitative and quantitative results show that our ProbES significantly improves the generalization ability of the navigation model.
Contrastive Instruction-Trajectory Learning for Vision-Language Navigation
Dec 09, 2021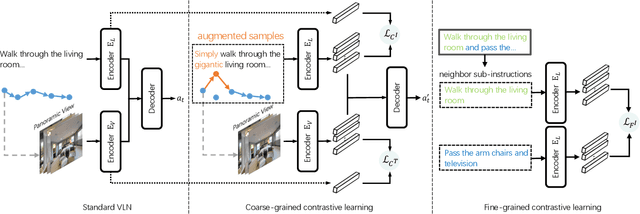
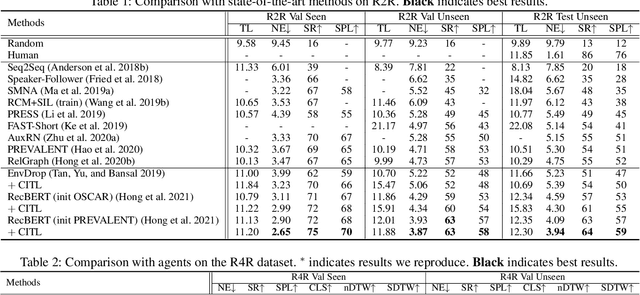
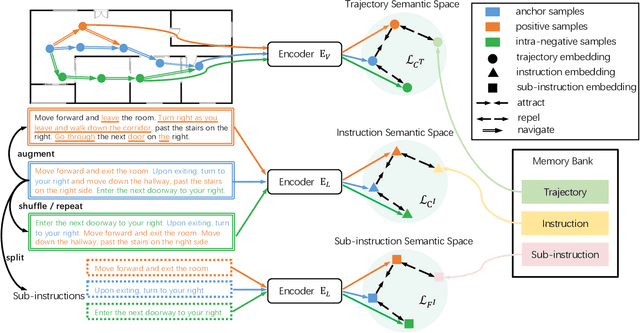
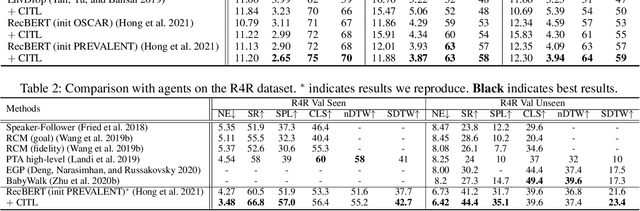
The vision-language navigation (VLN) task requires an agent to reach a target with the guidance of natural language instruction. Previous works learn to navigate step-by-step following an instruction. However, these works may fail to discriminate the similarities and discrepancies across instruction-trajectory pairs and ignore the temporal continuity of sub-instructions. These problems hinder agents from learning distinctive vision-and-language representations, harming the robustness and generalizability of the navigation policy. In this paper, we propose a Contrastive Instruction-Trajectory Learning (CITL) framework that explores invariance across similar data samples and variance across different ones to learn distinctive representations for robust navigation. Specifically, we propose: (1) a coarse-grained contrastive learning objective to enhance vision-and-language representations by contrasting semantics of full trajectory observations and instructions, respectively; (2) a fine-grained contrastive learning objective to perceive instructions by leveraging the temporal information of the sub-instructions; (3) a pairwise sample-reweighting mechanism for contrastive learning to mine hard samples and hence mitigate the influence of data sampling bias in contrastive learning. Our CITL can be easily integrated with VLN backbones to form a new learning paradigm and achieve better generalizability in unseen environments. Extensive experiments show that the model with CITL surpasses the previous state-of-the-art methods on R2R, R4R, and RxR.