 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Omni-Lite: Portable Speech Interfaces for Vision-Language Models
Mar 10, 2026While large-scale omni-models have demonstrated impressive capabilities across various modalities, their strong performance heavily relies on massive multimodal data and incurs substantial computational costs. This work introduces Speech-Omni-Lite, a cost-efficient framework for extending pre-trained Visual-Language (VL) backbones with speech understanding and generation capabilities, while fully preserving the backbones' vision-language performance. Specifically, the VL backbone is equipped with two lightweight, trainable plug-and-play modules, a speech projector and a speech token generator, while keeping the VL backbone fully frozen. To mitigate the scarcity of spoken QA corpora, a low-cost data construction strategy is proposed to generate Question-Text Answer-Text-Speech (QTATS) data from existing ASR speech-text pairs, facilitating effective speech generation training. Experimental results show that, even with only thousands of hours of speech training data, Speech-Omni-Lite achieves excellent spoken QA performance, which is comparable to omni-models trained on millions of hours of speech data. Furthermore, the learned speech modules exhibit strong transferability across VL backbones.
VGGT-Det: Mining VGGT Internal Priors for Sensor-Geometry-Free Multi-View Indoor 3D Object Detection
Mar 01, 2026Current multi-view indoor 3D object detectors rely on sensor geometry that is costly to obtain (i.e., precisely calibrated multi-view camera poses) to fuse multi-view information into a global scene representation, limiting deployment in real-world scenes. We target a more practical setting: Sensor-Geometry-Free (SG-Free) multi-view indoor 3D object detection, where there are no sensor-provided geometric inputs (multi-view poses or depth). Recent Visual Geometry Grounded Transformer (VGGT) shows that strong 3D cues can be inferred directly from images. Building on this insight, we present VGGT-Det, the first framework tailored for SG-Free multi-view indoor 3D object detection. Rather than merely consuming VGGT predictions, our method integrates VGGT encoder into a transformer-based pipeline. To effectively leverage both the semantic and geometric priors from inside VGGT, we introduce two novel key components: (i) Attention-Guided Query Generation (AG): exploits VGGT attention maps as semantic priors to initialize object queries, improving localization by focusing on object regions while preserving global spatial structure; (ii) Query-Driven Feature Aggregation (QD): a learnable See-Query interacts with object queries to 'see' what they need, and then dynamically aggregates multi-level geometric features across VGGT layers that progressively lift 2D features into 3D. Experiments show that VGGT-Det significantly surpasses the best-performing method in the SG-Free setting by 4.4 and 8.6 mAP@0.25 on ScanNet and ARKitScenes, respectively. Ablation study shows that VGGT's internally learned semantic and geometric priors can be effectively leveraged by our AG and QD.
AEQ-Bench: Measuring Empathy of Omni-Modal Large Models
Jan 15, 2026While the automatic evaluation of omni-modal large models (OLMs) is essential, assessing empathy remains a significant challenge due to its inherent affectivity. To investigate this challenge, we introduce AEQ-Bench (Audio Empathy Quotient Benchmark), a novel benchmark to systematically assess two core empathetic capabilities of OLMs: (i) generating empathetic responses by comprehending affective cues from multi-modal inputs (audio + text), and (ii) judging the empathy of audio responses without relying on text transcription. Compared to existing benchmarks, AEQ-Bench incorporates two novel settings that vary in context specificity and speech tone. Comprehensive assessment across linguistic and paralinguistic metrics reveals that (1) OLMs trained with audio output capabilities generally outperformed models with text-only outputs, and (2) while OLMs align with human judgments for coarse-grained quality assessment, they remain unreliable for evaluating fine-grained paralinguistic expressiveness.
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
Developing a Grounded View of AI
Nov 18, 2025As a capability coming from computation, how does AI differ fundamentally from the capabilities delivered by rule-based software program? The paper examines the behavior of artificial intelligence (AI) from engineering points of view to clarify its nature and limits. The paper argues that the rationality underlying humanity's impulse to pursue, articulate, and adhere to rules deserves to be valued and preserved. Identifying where rule-based practical rationality ends is the beginning of making it aware until action. Although the rules of AI behaviors are still hidden or only weakly observable, the paper has proposed a methodology to make a sense of discrimination possible and practical to identify the distinctions of the behavior of AI models with three types of decisions. It is a prerequisite for human responsibilities with alternative possibilities, considering how and when to use AI. It would be a solid start for people to ensure AI system soundness for the well-being of humans, society, and the environment.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning
Jun 05, 2025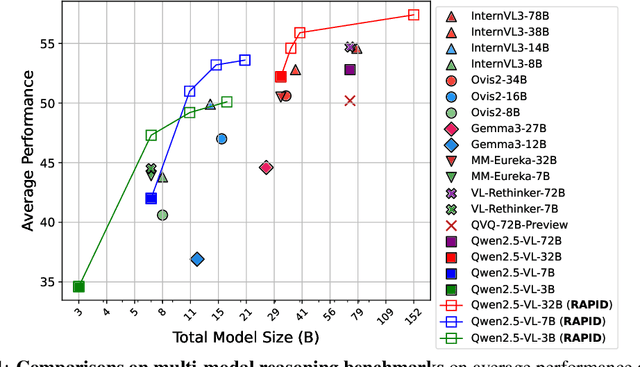
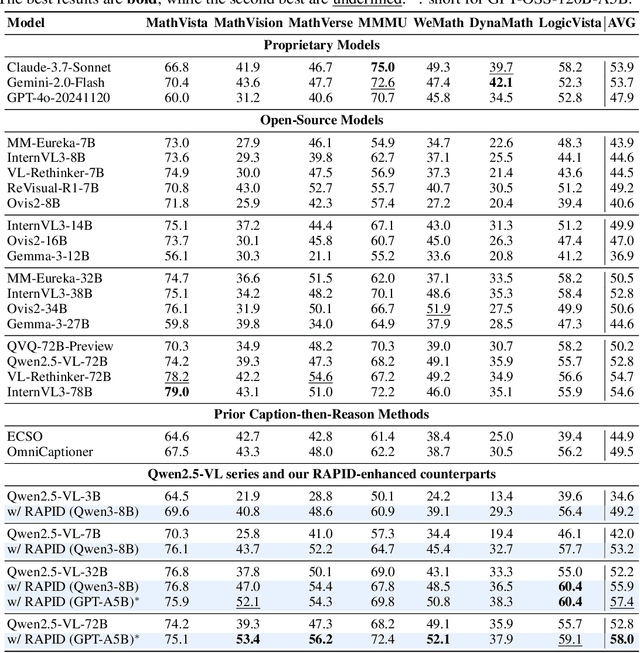
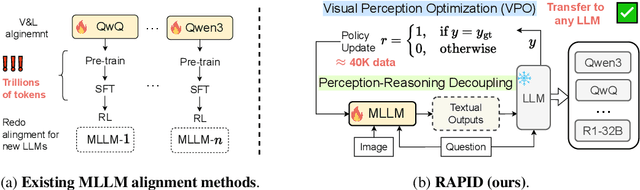
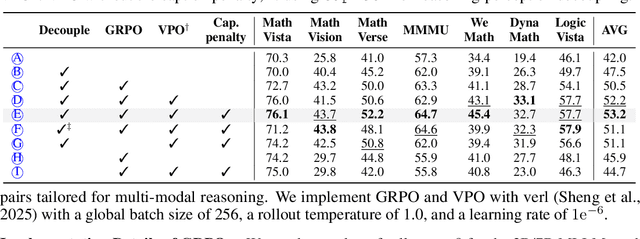
Recent advances in slow-thinking language models (e.g., OpenAI-o1 and DeepSeek-R1) have demonstrated remarkable abilities in complex reasoning tasks by emulating human-like reflective cognition. However, extending such capabilities to multi-modal large language models (MLLMs) remains challenging due to the high cost of retraining vision-language alignments when upgrading the underlying reasoner LLMs. A straightforward solution is to decouple perception from reasoning, i.e., converting visual inputs into language representations (e.g., captions) that are then passed to a powerful text-only reasoner. However, this decoupling introduces a critical challenge: the visual extractor must generate descriptions that are both faithful to the image and informative enough to support accurate downstream reasoning. To address this, we propose Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization (RACRO) - a reasoning-guided reinforcement learning strategy that aligns the extractor's captioning behavior with the reasoning objective. By closing the perception-reasoning loop via reward-based optimization, RACRO significantly enhances visual grounding and extracts reasoning-optimized representations. Experiments on multi-modal math and science benchmarks show that the proposed RACRO method achieves state-of-the-art average performance while enabling superior scalability and plug-and-play adaptation to more advanced reasoning LLMs without the necessity for costly multi-modal re-alignment.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
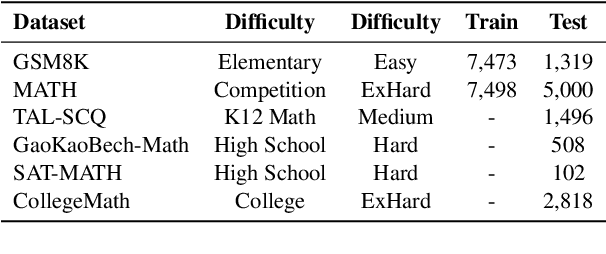

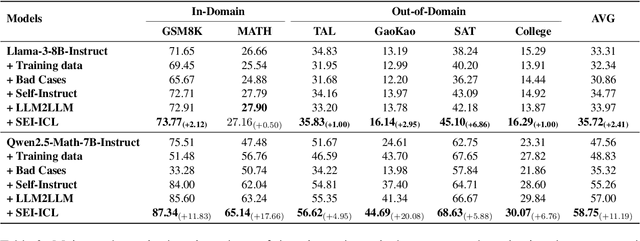
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025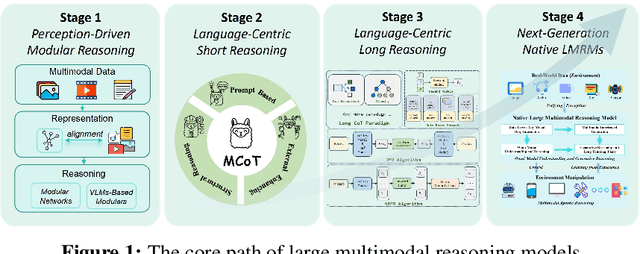
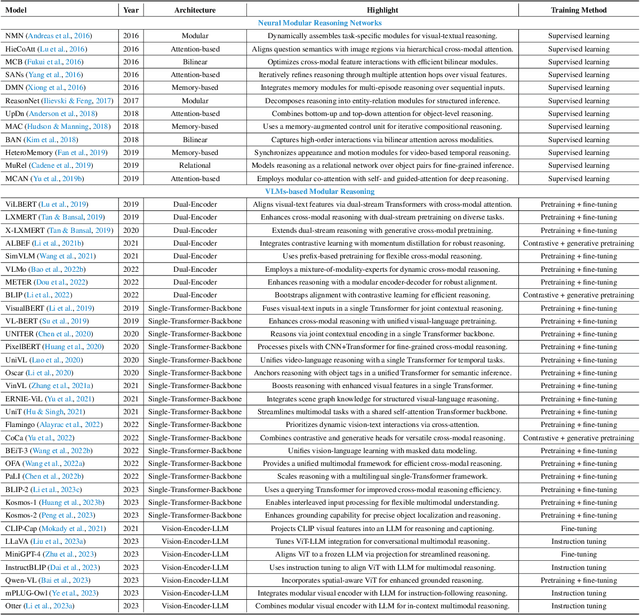
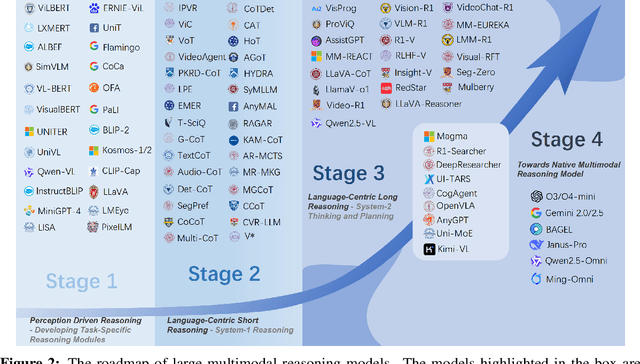
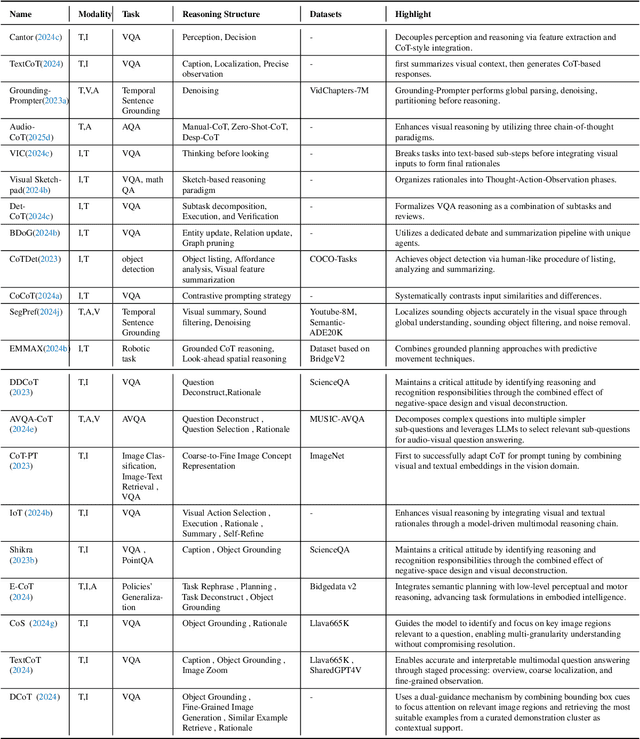
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
PaMi-VDPO: Mitigating Video Hallucinations by Prompt-Aware Multi-Instance Video Preference Learning
Apr 08, 2025



Direct Preference Optimization (DPO) helps reduce hallucinations in Video Multimodal Large Language Models (VLLMs), but its reliance on offline preference data limits adaptability and fails to capture true video-response misalignment. We propose Video Direct Preference Optimization (VDPO), an online preference learning framework that eliminates the need for preference annotation by leveraging video augmentations to generate rejected samples while keeping responses fixed. However, selecting effective augmentations is non-trivial, as some clips may be semantically identical to the original under specific prompts, leading to false rejections and disrupting alignment. To address this, we introduce Prompt-aware Multi-instance Learning VDPO (PaMi-VDPO), which selects augmentations based on prompt context. Instead of a single rejection, we construct a candidate set of augmented clips and apply a close-to-far selection strategy, initially ensuring all clips are semantically relevant while then prioritizing the most prompt-aware distinct clip. This allows the model to better capture meaningful visual differences, mitigating hallucinations, while avoiding false rejections, and improving alignment. PaMi-VDPOseamlessly integrates into existing VLLMs without additional parameters, GPT-4/human supervision. With only 10k SFT data, it improves the base model by 5.3% on VideoHallucer, surpassing GPT-4o, while maintaining stable performance on general video benchmarks.