 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Revealing Asymmetric Development of Abilities in MLLM Pre-training
Feb 13, 2026Pre-trained Multi-modal Large Language Models (MLLMs) provide a knowledge-rich foundation for post-training by leveraging their inherent perception and reasoning capabilities to solve complex tasks. However, the lack of an efficient evaluation framework impedes the diagnosis of their performance bottlenecks. Current evaluation primarily relies on testing after supervised fine-tuning, which introduces laborious additional training and autoregressive decoding costs. Meanwhile, common pre-training metrics cannot quantify a model's perception and reasoning abilities in a disentangled manner. Furthermore, existing evaluation benchmarks are typically limited in scale or misaligned with pre-training objectives. Thus, we propose RADAR, an efficient ability-centric evaluation framework for Revealing Asymmetric Development of Abilities in MLLM pRe-training. RADAR involves two key components: (1) Soft Discrimination Score, a novel metric for robustly tracking ability development without fine-tuning, based on quantifying nuanced gradations of the model preference for the correct answer over distractors; and (2) Multi-Modal Mixture Benchmark, a new 15K+ sample benchmark for comprehensively evaluating pre-trained MLLMs' perception and reasoning abilities in a 0-shot manner, where we unify authoritative benchmark datasets and carefully collect new datasets, extending the evaluation scope and addressing the critical gaps in current benchmarks. With RADAR, we comprehensively reveal the asymmetric development of perceptual and reasoning capabilities in pretrained MLLMs across diverse factors, including data volume, model size, and pretraining strategy. Our RADAR underscores the need for a decomposed perspective on pre-training ability bottlenecks, informing targeted interventions to advance MLLMs efficiently. Our code is publicly available at https://github.com/Nieysh/RADAR.
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Feb 05, 2026Recent progress in spatial reasoning with Multimodal Large Language Models (MLLMs) increasingly leverages geometric priors from 3D encoders. However, most existing integration strategies remain passive: geometry is exposed as a global stream and fused in an indiscriminate manner, which often induces semantic-geometry misalignment and redundant signals. We propose GeoThinker, a framework that shifts the paradigm from passive fusion to active perception. Instead of feature mixing, GeoThinker enables the model to selectively retrieve geometric evidence conditioned on its internal reasoning demands. GeoThinker achieves this through Spatial-Grounded Fusion applied at carefully selected VLM layers, where semantic visual priors selectively query and integrate task-relevant geometry via frame-strict cross-attention, further calibrated by Importance Gating that biases per-frame attention toward task-relevant structures. Comprehensive evaluation results show that GeoThinker sets a new state-of-the-art in spatial intelligence, achieving a peak score of 72.6 on the VSI-Bench. Furthermore, GeoThinker demonstrates robust generalization and significantly improved spatial perception across complex downstream scenarios, including embodied referring and autonomous driving. Our results indicate that the ability to actively integrate spatial structures is essential for next-generation spatial intelligence. Code can be found at https://github.com/Li-Hao-yuan/GeoThinker.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025

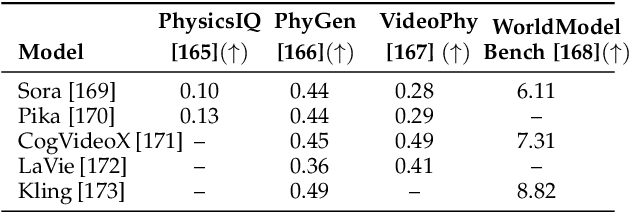
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
SeePhys: Does Seeing Help Thinking? -- Benchmarking Vision-Based Physics Reasoning
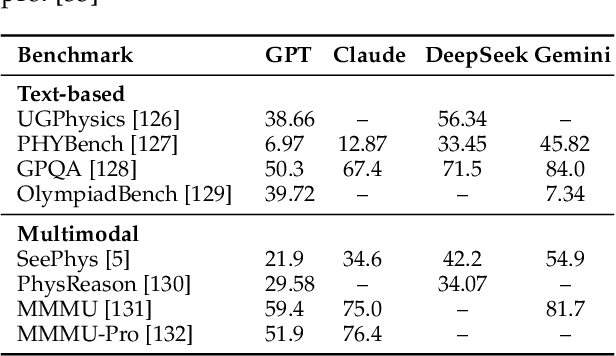
May 25, 2025We present SeePhys, a large-scale multimodal benchmark for LLM reasoning grounded in physics questions ranging from middle school to PhD qualifying exams. The benchmark covers 7 fundamental domains spanning the physics discipline, incorporating 21 categories of highly heterogeneous diagrams. In contrast to prior works where visual elements mainly serve auxiliary purposes, our benchmark features a substantial proportion of vision-essential problems (75\%) that mandate visual information extraction for correct solutions. Through extensive evaluation, we observe that even the most advanced visual reasoning models (e.g., Gemini-2.5-pro and o4-mini) achieve sub-60\% accuracy on our benchmark. These results reveal fundamental challenges in current large language models' visual understanding capabilities, particularly in: (i) establishing rigorous coupling between diagram interpretation and physics reasoning, and (ii) overcoming their persistent reliance on textual cues as cognitive shortcuts.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning
Nov 18, 2024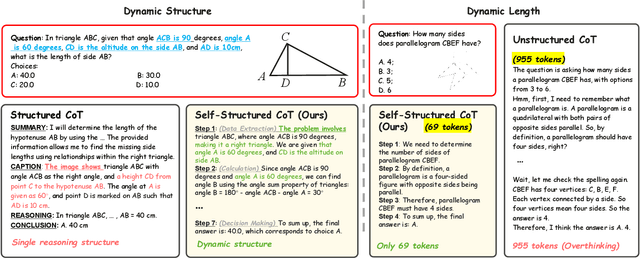
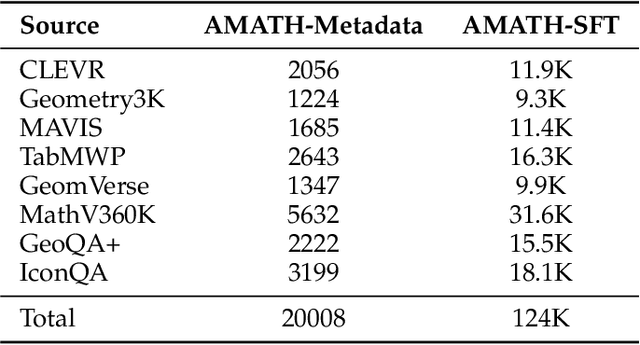
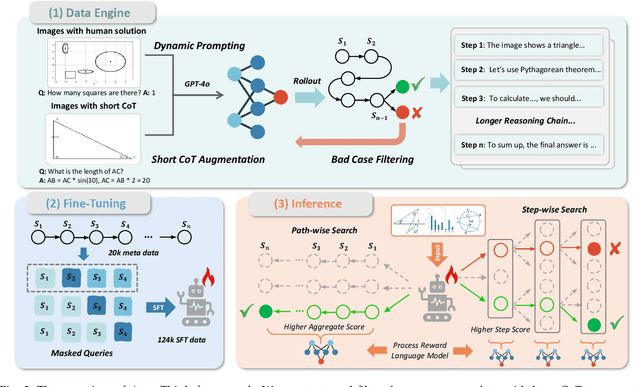
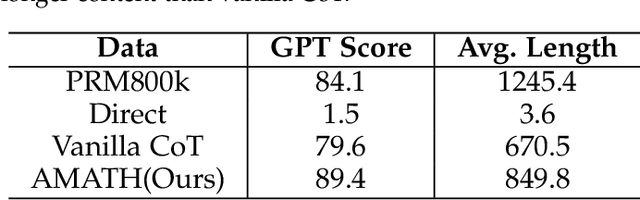
In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of ``slow thinking" into multimodal large language models (MLLMs). Contrary to existing methods that rely on direct or fast thinking, our key idea is to construct long chains of thought (CoT) consisting of atomic actions in a step-by-step manner, guiding MLLMs to perform complex reasoning. To this end, we design a novel AtomThink framework composed of three key modules: (i) a CoT annotation engine that automatically generates high-quality CoT annotations to address the lack of high-quality visual mathematical data; (ii) an atomic step fine-tuning strategy that jointly optimizes an MLLM and a policy reward model (PRM) for step-wise reasoning; and (iii) four different search strategies that can be applied with the PRM to complete reasoning. Additionally, we propose AtomMATH, a large-scale multimodal dataset of long CoTs, and an atomic capability evaluation metric for mathematical tasks. Extensive experimental results show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving approximately 50\% relative accuracy gains on MathVista and 120\% on MathVerse. To support the advancement of multimodal slow-thinking models, we will make our code and dataset publicly available on https://github.com/Quinn777/AtomThink.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024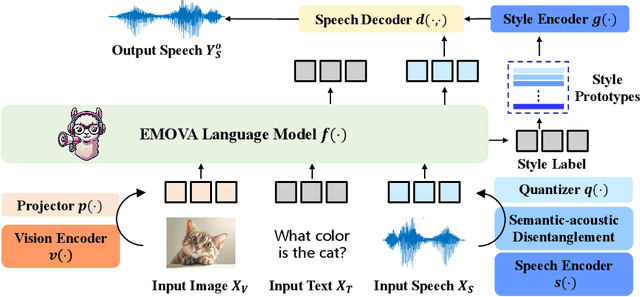
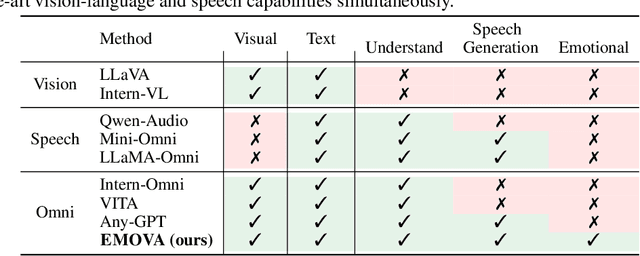
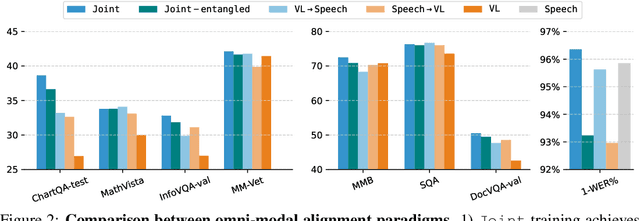

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
Toward Robust Diagnosis: A Contour Attention Preserving Adversarial Defense for COVID-19 Detection
Nov 30, 2022



As the COVID-19 pandemic puts pressure on healthcare systems worldwide, the computed tomography image based AI diagnostic system has become a sustainable solution for early diagnosis. However, the model-wise vulnerability under adversarial perturbation hinders its deployment in practical situation. The existing adversarial training strategies are difficult to generalized into medical imaging field challenged by complex medical texture features. To overcome this challenge, we propose a Contour Attention Preserving (CAP) method based on lung cavity edge extraction. The contour prior features are injected to attention layer via a parameter regularization and we optimize the robust empirical risk with hybrid distance metric. We then introduce a new cross-nation CT scan dataset to evaluate the generalization capability of the adversarial robustness under distribution shift. Experimental results indicate that the proposed method achieves state-of-the-art performance in multiple adversarial defense and generalization tasks. The code and dataset are available at https://github.com/Quinn777/CAP.