 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoreHOI: Physically Plausible Reconstruction of Human-Object Interaction via Score-Guided Diffusion
Sep 09, 2025Joint reconstruction of human-object interaction marks a significant milestone in comprehending the intricate interrelations between humans and their surrounding environment. Nevertheless, previous optimization methods often struggle to achieve physically plausible reconstruction results due to the lack of prior knowledge about human-object interactions. In this paper, we introduce ScoreHOI, an effective diffusion-based optimizer that introduces diffusion priors for the precise recovery of human-object interactions. By harnessing the controllability within score-guided sampling, the diffusion model can reconstruct a conditional distribution of human and object pose given the image observation and object feature. During inference, the ScoreHOI effectively improves the reconstruction results by guiding the denoising process with specific physical constraints. Furthermore, we propose a contact-driven iterative refinement approach to enhance the contact plausibility and improve the reconstruction accuracy. Extensive evaluations on standard benchmarks demonstrate ScoreHOI's superior performance over state-of-the-art methods, highlighting its ability to achieve a precise and robust improvement in joint human-object interaction reconstruction.
NovelGS: Consistent Novel-view Denoising via Large Gaussian Reconstruction Model
Nov 25, 2024

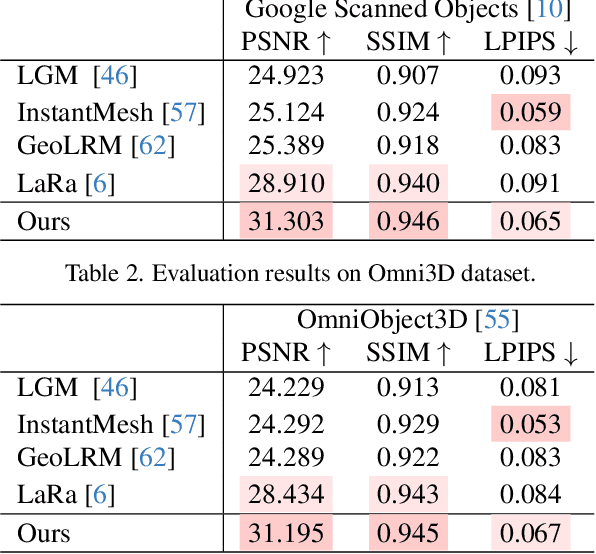

We introduce NovelGS, a diffusion model for Gaussian Splatting (GS) given sparse-view images. Recent works leverage feed-forward networks to generate pixel-aligned Gaussians, which could be fast rendered. Unfortunately, the method was unable to produce satisfactory results for areas not covered by the input images due to the formulation of these methods. In contrast, we leverage the novel view denoising through a transformer-based network to generate 3D Gaussians. Specifically, by incorporating both conditional views and noisy target views, the network predicts pixel-aligned Gaussians for each view. During training, the rendered target and some additional views of the Gaussians are supervised. During inference, the target views are iteratively rendered and denoised from pure noise. Our approach demonstrates state-of-the-art performance in addressing the multi-view image reconstruction challenge. Due to generative modeling of unseen regions, NovelGS effectively reconstructs 3D objects with consistent and sharp textures. Experimental results on publicly available datasets indicate that NovelGS substantially surpasses existing image-to-3D frameworks, both qualitatively and quantitatively. We also demonstrate the potential of NovelGS in generative tasks, such as text-to-3D and image-to-3D, by integrating it with existing multiview diffusion models. We will make the code publicly accessible.
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
Apr 30, 2024This work introduces MotionLCM, extending controllable motion generation to a real-time level. Existing methods for spatial control in text-conditioned motion generation suffer from significant runtime inefficiency. To address this issue, we first propose the motion latent consistency model (MotionLCM) for motion generation, building upon the latent diffusion model (MLD). By employing one-step (or few-step) inference, we further improve the runtime efficiency of the motion latent diffusion model for motion generation. To ensure effective controllability, we incorporate a motion ControlNet within the latent space of MotionLCM and enable explicit control signals (e.g., pelvis trajectory) in the vanilla motion space to control the generation process directly, similar to controlling other latent-free diffusion models for motion generation. By employing these techniques, our approach can generate human motions with text and control signals in real-time. Experimental results demonstrate the remarkable generation and controlling capabilities of MotionLCM while maintaining real-time runtime efficiency.
Plan, Posture and Go: Towards Open-World Text-to-Motion Generation
Dec 22, 2023Conventional text-to-motion generation methods are usually trained on limited text-motion pairs, making them hard to generalize to open-world scenarios. Some works use the CLIP model to align the motion space and the text space, aiming to enable motion generation from natural language motion descriptions. However, they are still constrained to generate limited and unrealistic in-place motions. To address these issues, we present a divide-and-conquer framework named PRO-Motion, which consists of three modules as motion planner, posture-diffuser and go-diffuser. The motion planner instructs Large Language Models (LLMs) to generate a sequence of scripts describing the key postures in the target motion. Differing from natural languages, the scripts can describe all possible postures following very simple text templates. This significantly reduces the complexity of posture-diffuser, which transforms a script to a posture, paving the way for open-world generation. Finally, go-diffuser, implemented as another diffusion model, estimates whole-body translations and rotations for all postures, resulting in realistic motions. Experimental results have shown the superiority of our method with other counterparts, and demonstrated its capability of generating diverse and realistic motions from complex open-world prompts such as "Experiencing a profound sense of joy". The project page is available at https://moonsliu.github.io/Pro-Motion.
FLAG3D: A 3D Fitness Activity Dataset with Language Instruction
Dec 09, 2022With the continuously thriving popularity around the world, fitness activity analytic has become an emerging research topic in computer vision. While a variety of new tasks and algorithms have been proposed recently, there are growing hunger for data resources involved in high-quality data, fine-grained labels, and diverse environments. In this paper, we present FLAG3D, a large-scale 3D fitness activity dataset with language instruction containing 180K sequences of 60 categories. FLAG3D features the following three aspects: 1) accurate and dense 3D human pose captured from advanced MoCap system to handle the complex activity and large movement, 2) detailed and professional language instruction to describe how to perform a specific activity, 3) versatile video resources from a high-tech MoCap system, rendering software, and cost-effective smartphones in natural environments. Extensive experiments and in-depth analysis show that FLAG3D contributes great research value for various challenges, such as cross-domain human action recognition, dynamic human mesh recovery, and language-guided human action generation. Our dataset and source code will be publicly available at https://andytang15.github.io/FLAG3D.
Toward Robust Diagnosis: A Contour Attention Preserving Adversarial Defense for COVID-19 Detection
Nov 30, 2022As the COVID-19 pandemic puts pressure on healthcare systems worldwide, the computed tomography image based AI diagnostic system has become a sustainable solution for early diagnosis. However, the model-wise vulnerability under adversarial perturbation hinders its deployment in practical situation. The existing adversarial training strategies are difficult to generalized into medical imaging field challenged by complex medical texture features. To overcome this challenge, we propose a Contour Attention Preserving (CAP) method based on lung cavity edge extraction. The contour prior features are injected to attention layer via a parameter regularization and we optimize the robust empirical risk with hybrid distance metric. We then introduce a new cross-nation CT scan dataset to evaluate the generalization capability of the adversarial robustness under distribution shift. Experimental results indicate that the proposed method achieves state-of-the-art performance in multiple adversarial defense and generalization tasks. The code and dataset are available at https://github.com/Quinn777/CAP.