 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion2Motion: Cross-topology Motion Transfer with Sparse Correspondence
Aug 18, 2025

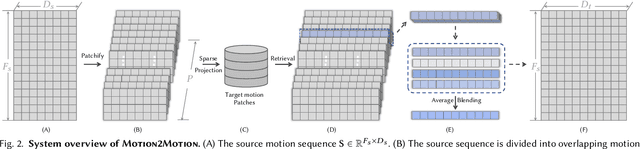

This work studies the challenge of transfer animations between characters whose skeletal topologies differ substantially. While many techniques have advanced retargeting techniques in decades, transfer motions across diverse topologies remains less-explored. The primary obstacle lies in the inherent topological inconsistency between source and target skeletons, which restricts the establishment of straightforward one-to-one bone correspondences. Besides, the current lack of large-scale paired motion datasets spanning different topological structures severely constrains the development of data-driven approaches. To address these limitations, we introduce Motion2Motion, a novel, training-free framework. Simply yet effectively, Motion2Motion works with only one or a few example motions on the target skeleton, by accessing a sparse set of bone correspondences between the source and target skeletons. Through comprehensive qualitative and quantitative evaluations, we demonstrate that Motion2Motion achieves efficient and reliable performance in both similar-skeleton and cross-species skeleton transfer scenarios. The practical utility of our approach is further evidenced by its successful integration in downstream applications and user interfaces, highlighting its potential for industrial applications. Code and data are available at https://lhchen.top/Motion2Motion.
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025

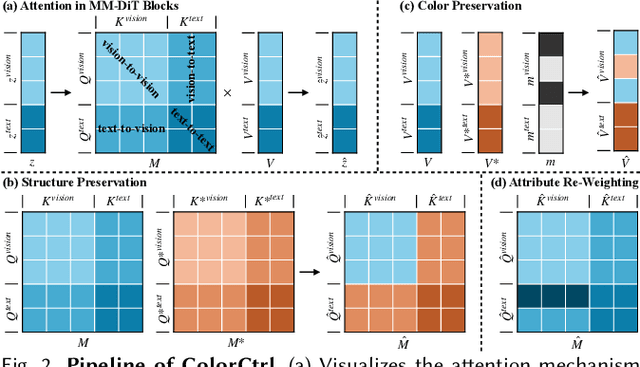
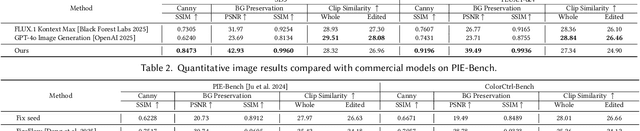
Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
HumanMM: Global Human Motion Recovery from Multi-shot Videos
Mar 10, 2025In this paper, we present a novel framework designed to reconstruct long-sequence 3D human motion in the world coordinates from in-the-wild videos with multiple shot transitions. Such long-sequence in-the-wild motions are highly valuable to applications such as motion generation and motion understanding, but are of great challenge to be recovered due to abrupt shot transitions, partial occlusions, and dynamic backgrounds presented in such videos. Existing methods primarily focus on single-shot videos, where continuity is maintained within a single camera view, or simplify multi-shot alignment in camera space only. In this work, we tackle the challenges by integrating an enhanced camera pose estimation with Human Motion Recovery (HMR) by incorporating a shot transition detector and a robust alignment module for accurate pose and orientation continuity across shots. By leveraging a custom motion integrator, we effectively mitigate the problem of foot sliding and ensure temporal consistency in human pose. Extensive evaluations on our created multi-shot dataset from public 3D human datasets demonstrate the robustness of our method in reconstructing realistic human motion in world coordinates.
Simulating the Real World: A Unified Survey of Multimodal Generative Models
Mar 06, 2025



Understanding and replicating the real world is a critical challenge in Artificial General Intelligence (AGI) research. To achieve this, many existing approaches, such as world models, aim to capture the fundamental principles governing the physical world, enabling more accurate simulations and meaningful interactions. However, current methods often treat different modalities, including 2D (images), videos, 3D, and 4D representations, as independent domains, overlooking their interdependencies. Additionally, these methods typically focus on isolated dimensions of reality without systematically integrating their connections. In this survey, we present a unified survey for multimodal generative models that investigate the progression of data dimensionality in real-world simulation. Specifically, this survey starts from 2D generation (appearance), then moves to video (appearance+dynamics) and 3D generation (appearance+geometry), and finally culminates in 4D generation that integrate all dimensions. To the best of our knowledge, this is the first attempt to systematically unify the study of 2D, video, 3D and 4D generation within a single framework. To guide future research, we provide a comprehensive review of datasets, evaluation metrics and future directions, and fostering insights for newcomers. This survey serves as a bridge to advance the study of multimodal generative models and real-world simulation within a unified framework.
ScaMo: Exploring the Scaling Law in Autoregressive Motion Generation Model
Dec 19, 2024The scaling law has been validated in various domains, such as natural language processing (NLP) and massive computer vision tasks; however, its application to motion generation remains largely unexplored. In this paper, we introduce a scalable motion generation framework that includes the motion tokenizer Motion FSQ-VAE and a text-prefix autoregressive transformer. Through comprehensive experiments, we observe the scaling behavior of this system. For the first time, we confirm the existence of scaling laws within the context of motion generation. Specifically, our results demonstrate that the normalized test loss of our prefix autoregressive models adheres to a logarithmic law in relation to compute budgets. Furthermore, we also confirm the power law between Non-Vocabulary Parameters, Vocabulary Parameters, and Data Tokens with respect to compute budgets respectively. Leveraging the scaling law, we predict the optimal transformer size, vocabulary size, and data requirements for a compute budget of $1e18$. The test loss of the system, when trained with the optimal model size, vocabulary size, and required data, aligns precisely with the predicted test loss, thereby validating the scaling law.
MotionWavelet: Human Motion Prediction via Wavelet Manifold Learning
Nov 25, 2024Modeling temporal characteristics and the non-stationary dynamics of body movement plays a significant role in predicting human future motions. However, it is challenging to capture these features due to the subtle transitions involved in the complex human motions. This paper introduces MotionWavelet, a human motion prediction framework that utilizes Wavelet Transformation and studies human motion patterns in the spatial-frequency domain. In MotionWavelet, a Wavelet Diffusion Model (WDM) learns a Wavelet Manifold by applying Wavelet Transformation on the motion data therefore encoding the intricate spatial and temporal motion patterns. Once the Wavelet Manifold is built, WDM trains a diffusion model to generate human motions from Wavelet latent vectors. In addition to the WDM, MotionWavelet also presents a Wavelet Space Shaping Guidance mechanism to refine the denoising process to improve conformity with the manifold structure. WDM also develops Temporal Attention-Based Guidance to enhance prediction accuracy. Extensive experiments validate the effectiveness of MotionWavelet, demonstrating improved prediction accuracy and enhanced generalization across various benchmarks. Our code and models will be released upon acceptance.
MotionCLR: Motion Generation and Training-free Editing via Understanding Attention Mechanisms
Oct 24, 2024This research delves into the problem of interactive editing of human motion generation. Previous motion diffusion models lack explicit modeling of the word-level text-motion correspondence and good explainability, hence restricting their fine-grained editing ability. To address this issue, we propose an attention-based motion diffusion model, namely MotionCLR, with CLeaR modeling of attention mechanisms. Technically, MotionCLR models the in-modality and cross-modality interactions with self-attention and cross-attention, respectively. More specifically, the self-attention mechanism aims to measure the sequential similarity between frames and impacts the order of motion features. By contrast, the cross-attention mechanism works to find the fine-grained word-sequence correspondence and activate the corresponding timesteps in the motion sequence. Based on these key properties, we develop a versatile set of simple yet effective motion editing methods via manipulating attention maps, such as motion (de-)emphasizing, in-place motion replacement, and example-based motion generation, etc. For further verification of the explainability of the attention mechanism, we additionally explore the potential of action-counting and grounded motion generation ability via attention maps. Our experimental results show that our method enjoys good generation and editing ability with good explainability.
MotionLLM: Understanding Human Behaviors from Human Motions and Videos
May 30, 2024This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
Apr 30, 2024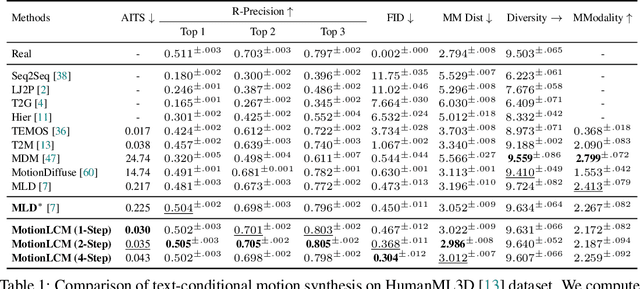
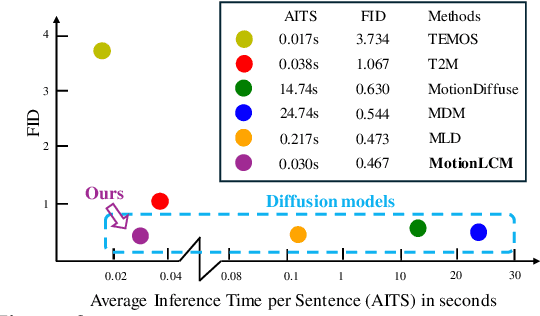
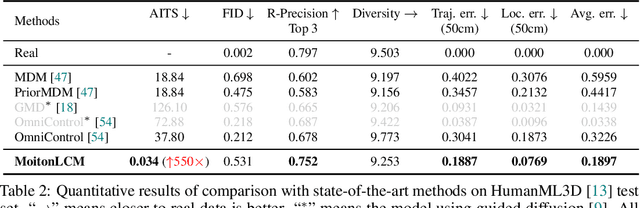
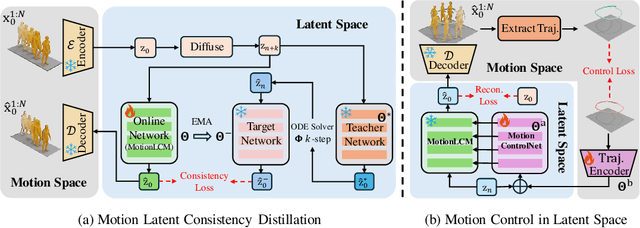
This work introduces MotionLCM, extending controllable motion generation to a real-time level. Existing methods for spatial control in text-conditioned motion generation suffer from significant runtime inefficiency. To address this issue, we first propose the motion latent consistency model (MotionLCM) for motion generation, building upon the latent diffusion model (MLD). By employing one-step (or few-step) inference, we further improve the runtime efficiency of the motion latent diffusion model for motion generation. To ensure effective controllability, we incorporate a motion ControlNet within the latent space of MotionLCM and enable explicit control signals (e.g., pelvis trajectory) in the vanilla motion space to control the generation process directly, similar to controlling other latent-free diffusion models for motion generation. By employing these techniques, our approach can generate human motions with text and control signals in real-time. Experimental results demonstrate the remarkable generation and controlling capabilities of MotionLCM while maintaining real-time runtime efficiency.
ERASE: Error-Resilient Representation Learning on Graphs for Label Noise Tolerance
Dec 13, 2023



Deep learning has achieved remarkable success in graph-related tasks, yet this accomplishment heavily relies on large-scale high-quality annotated datasets. However, acquiring such datasets can be cost-prohibitive, leading to the practical use of labels obtained from economically efficient sources such as web searches and user tags. Unfortunately, these labels often come with noise, compromising the generalization performance of deep networks. To tackle this challenge and enhance the robustness of deep learning models against label noise in graph-based tasks, we propose a method called ERASE (Error-Resilient representation learning on graphs for lAbel noiSe tolerancE). The core idea of ERASE is to learn representations with error tolerance by maximizing coding rate reduction. Particularly, we introduce a decoupled label propagation method for learning representations. Before training, noisy labels are pre-corrected through structural denoising. During training, ERASE combines prototype pseudo-labels with propagated denoised labels and updates representations with error resilience, which significantly improves the generalization performance in node classification. The proposed method allows us to more effectively withstand errors caused by mislabeled nodes, thereby strengthening the robustness of deep networks in handling noisy graph data. Extensive experimental results show that our method can outperform multiple baselines with clear margins in broad noise levels and enjoy great scalability. Codes are released at https://github.com/eraseai/erase.